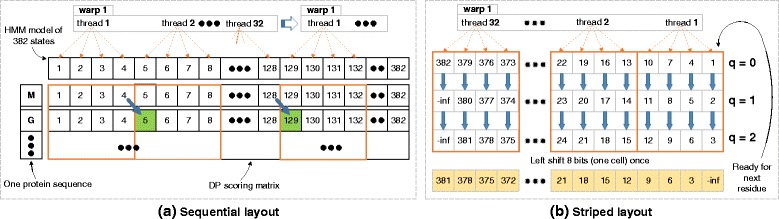
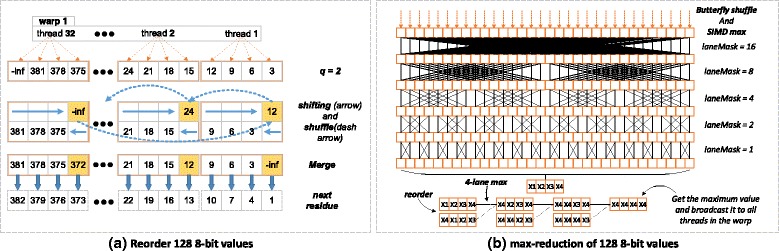
Jiang Hanyu, Ganesan Narayan
Department of Elec. and Comp. Engg, Stevens Institute of Technology, Hoboken, NJ, 07030, USA.
BMC Bioinformatics. 2016 Feb 27;17:106. doi: 10.1186/s12859-016-0946-4.
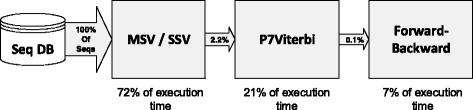
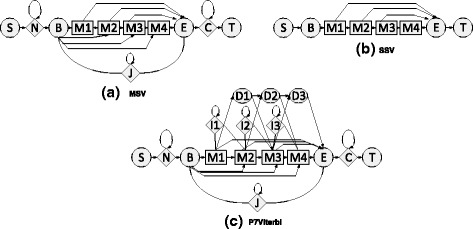
HMMER software suite is widely used for analysis of homologous protein and nucleotide sequences with high sensitivity. The latest version of hmmsearch in HMMER 3.x, utilizes heuristic-pipeline which consists of MSV/SSV (Multiple/Single ungapped Segment Viterbi) stage, P7Viterbi stage and the Forward scoring stage to accelerate homology detection. Since the latest version is highly optimized for performance on modern multi-core CPUs with SSE capabilities, only a few acceleration attempts report speedup. However, the most compute intensive tasks within the pipeline (viz., MSV/SSV and P7Viterbi stages) still stand to benefit from the computational capabilities of massively parallel processors.
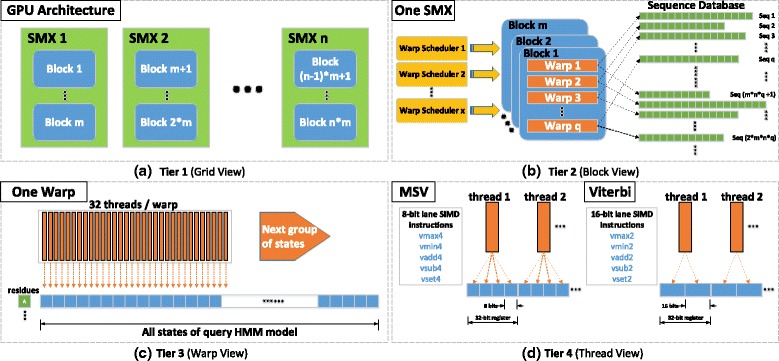
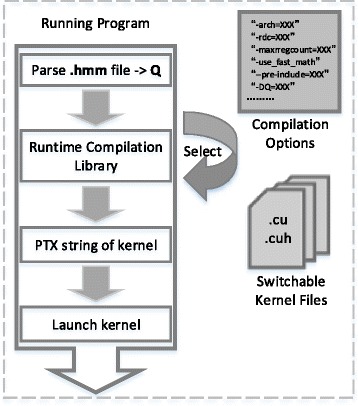
A Multi-Tiered Parallel Framework (CUDAMPF) implemented on CUDA-enabled GPUs presented here, offers a finer-grained parallelism for MSV/SSV and Viterbi algorithms. We couple SIMT (Single Instruction Multiple Threads) mechanism with SIMD (Single Instructions Multiple Data) video instructions with warp-synchronism to achieve high-throughput processing and eliminate thread idling. We also propose a hardware-aware optimal allocation scheme of scarce resources like on-chip memory and caches in order to boost performance and scalability of CUDAMPF. In addition, runtime compilation via NVRTC available with CUDA 7.0 is incorporated into the presented framework that not only helps unroll innermost loop to yield upto 2 to 3-fold speedup than static compilation but also enables dynamic loading and switching of kernels depending on the query model size, in order to achieve optimal performance.
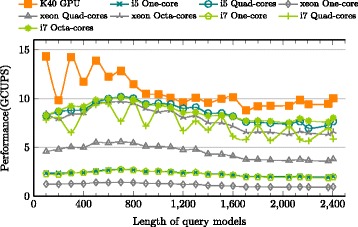
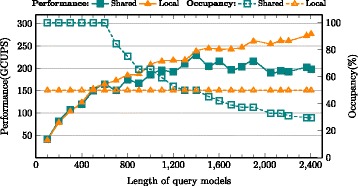
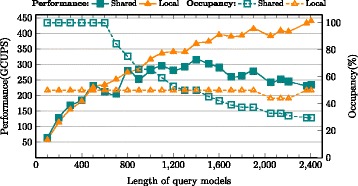
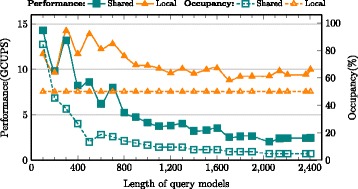
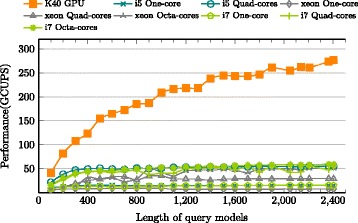
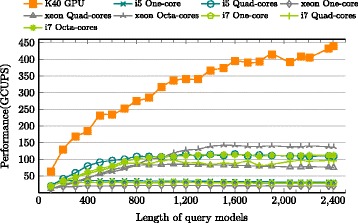
CUDAMPF is designed as a hardware-aware parallel framework for accelerating computational hotspots within the hmmsearch pipeline as well as other sequence alignment applications. It achieves significant speedup by exploiting hierarchical parallelism on single GPU and takes full advantage of limited resources based on their own performance features. In addition to exceeding performance of other acceleration attempts, comprehensive evaluations against high-end CPUs (Intel i5, i7 and Xeon) shows that CUDAMPF yields upto 440 GCUPS for SSV, 277 GCUPS for MSV and 14.3 GCUPS for P7Viterbi all with 100 % accuracy, which translates to a maximum speedup of 37.5, 23.1 and 11.6-fold for MSV, SSV and P7Viterbi respectively. The source code is available at https://github.com/Super-Hippo/CUDAMPF.
HMMER软件套件被广泛用于高灵敏度地分析同源蛋白质和核苷酸序列。HMMER 3.x中最新版本的hmmsearch利用启发式管道,该管道由MSV/SSV(多个/单个无间隙片段维特比)阶段、P7维特比阶段和前向评分阶段组成,以加速同源性检测。由于最新版本针对具有SSE功能的现代多核CPU进行了高度优化,只有少数加速尝试报告了加速效果。然而,管道中计算量最大的任务(即MSV/SSV和P7维特比阶段)仍有望从大规模并行处理器的计算能力中受益。
本文介绍的在支持CUDA的GPU上实现的多层并行框架(CUDAMPF),为MSV/SSV和维特比算法提供了更细粒度的并行性。我们将单指令多线程(SIMT)机制与单指令多数据(SIMD)视频指令以及线程束同步相结合,以实现高吞吐量处理并消除线程空闲。我们还提出了一种硬件感知的稀缺资源(如片上内存和缓存)优化分配方案,以提高CUDAMPF的性能和可扩展性。此外,通过CUDA 7.0提供的NVRTC进行的运行时编译被纳入所提出的框架中,这不仅有助于展开最内层循环,比静态编译产生高达2到3倍的加速,还能根据查询模型大小动态加载和切换内核,以实现最佳性能。
CUDAMPF被设计为一种硬件感知的并行框架,用于加速hmmsearch管道内的计算热点以及其他序列比对应用。它通过利用单个GPU上的分层并行性实现了显著的加速,并根据自身性能特征充分利用有限资源。除了超过其他加速尝试的性能外,针对高端CPU(英特尔i5、i7和至强)的综合评估表明,CUDAMPF在SSV上产生高达440 GCUPS,在MSV上产生277 GCUPS,在P7维特比上产生14.3 GCUPS,所有这些都具有100%的准确率,这分别转化为MSV、SSV和P7维特比的最大加速比为37.5倍、23.1倍和11.6倍。源代码可在https://github.com/Super-Hippo/CUDAMPF获取。