Department of Statistics, University of California, Berkeley, California 94720, USA.
Genome Res. 2012 Sep;22(9):1646-57. doi: 10.1101/gr.134767.111.
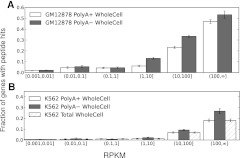
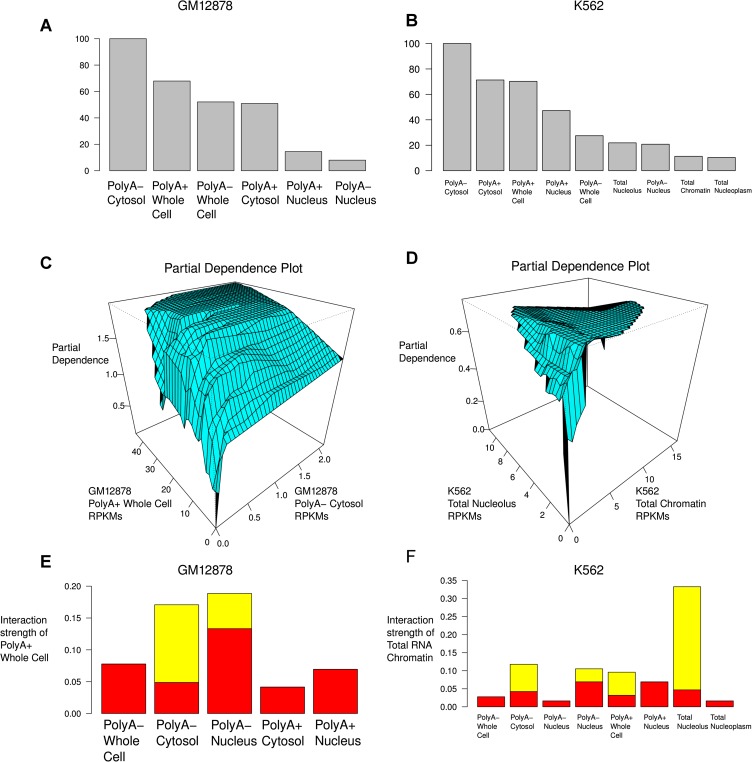
Data from the Encyclopedia of DNA Elements (ENCODE) project show over 9640 human genome loci classified as long noncoding RNAs (lncRNAs), yet only ~100 have been deeply characterized to determine their role in the cell. To measure the protein-coding output from these RNAs, we jointly analyzed two recent data sets produced in the ENCODE project: tandem mass spectrometry (MS/MS) data mapping expressed peptides to their encoding genomic loci, and RNA-seq data generated by ENCODE in long polyA+ and polyA- fractions in the cell lines K562 and GM12878. We used the machine-learning algorithm RuleFit3 to regress the peptide data against RNA expression data. The most important covariate for predicting translation was, surprisingly, the Cytosol polyA- fraction in both cell lines. LncRNAs are ~13-fold less likely to produce detectable peptides than similar mRNAs, indicating that ~92% of GENCODE v7 lncRNAs are not translated in these two ENCODE cell lines. Intersecting 9640 lncRNA loci with 79,333 peptides yielded 85 unique peptides matching 69 lncRNAs. Most cases were due to a coding transcript misannotated as lncRNA. Two exceptions were an unprocessed pseudogene and a bona fide lncRNA gene, both with open reading frames (ORFs) compromised by upstream stop codons. All potentially translatable lncRNA ORFs had only a single peptide match, indicating low protein abundance and/or false-positive peptide matches. We conclude that with very few exceptions, ribosomes are able to distinguish coding from noncoding transcripts and, hence, that ectopic translation and cryptic mRNAs are rare in the human lncRNAome.
来自 DNA 元件百科全书 (ENCODE) 项目的数据显示,人类基因组中有超过 9640 个位点被归类为长非编码 RNA(lncRNA),但只有约 100 个被深入表征以确定其在细胞中的作用。为了测量这些 RNA 的蛋白质编码输出,我们联合分析了 ENCODE 项目中最近产生的两个数据集:串联质谱 (MS/MS) 数据将表达肽映射到其编码基因组位置,以及 ENCODE 在 K562 和 GM12878 细胞系中的长 polyA+和 polyA- 分数中生成的 RNA-seq 数据。我们使用机器学习算法 RuleFit3 将肽数据回归到 RNA 表达数据。令人惊讶的是,预测翻译的最重要协变量是这两种细胞系中的细胞质 polyA- 分数。lncRNA 产生可检测肽的可能性比相似的 mRNA 低约 13 倍,这表明在这两种 ENCODE 细胞系中,约 92%的 GENCODE v7 lncRNA 没有被翻译。将 9640 个 lncRNA 基因座与 79333 个肽相交,得到了 85 个与 69 个 lncRNA 匹配的独特肽。大多数情况下是由于编码转录本被错误注释为 lncRNA。两个例外是一个未加工的假基因和一个真正的 lncRNA 基因,它们的开放阅读框 (ORF) 都被上游终止密码子破坏。所有潜在可翻译的 lncRNA ORF 只有一个肽匹配,表明蛋白质丰度低和/或肽匹配假阳性。我们得出的结论是,除了极少数例外,核糖体能够区分编码和非编码转录本,因此,异位翻译和隐匿的 mRNA 在人类 lncRNA 中很少见。