Institució Catalana de Recerca i Estudis Avançats, Barcelona, Catalonia, Spain.
PLoS One. 2012;7(9):e44620. doi: 10.1371/journal.pone.0044620. Epub 2012 Sep 11.
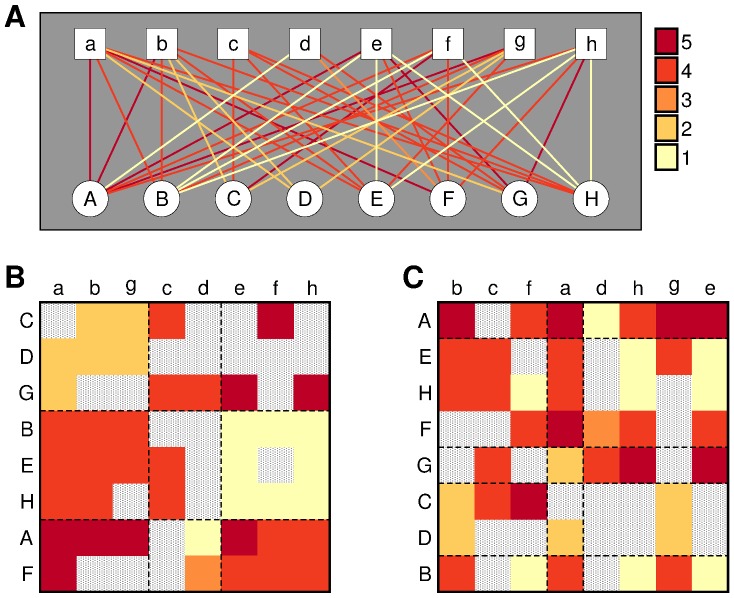
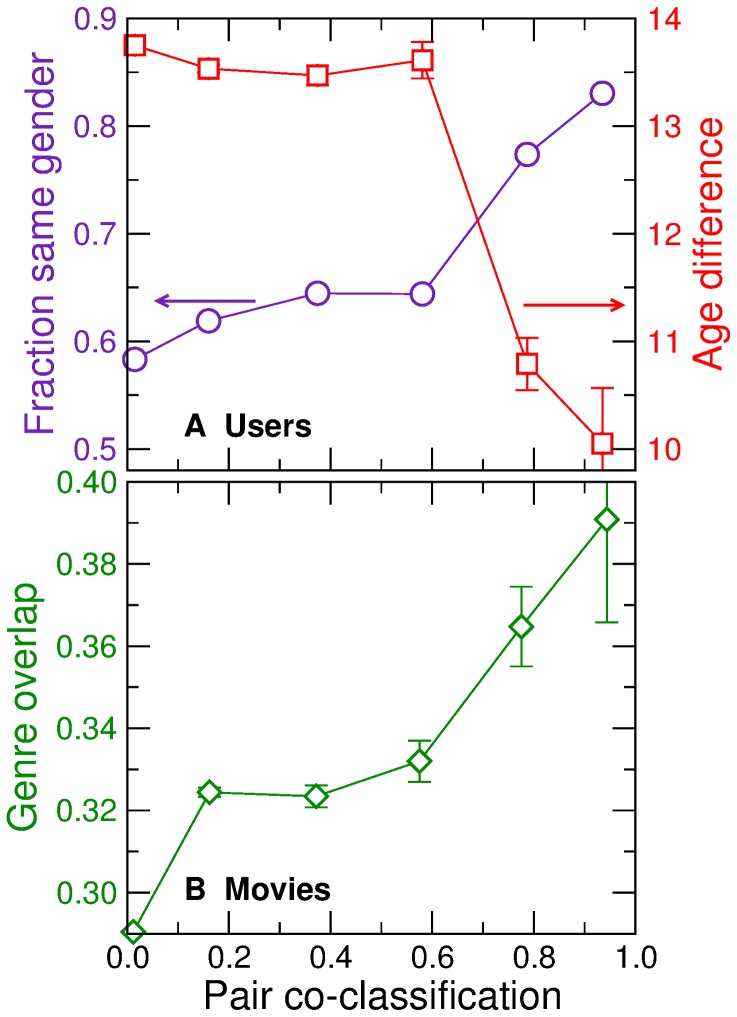
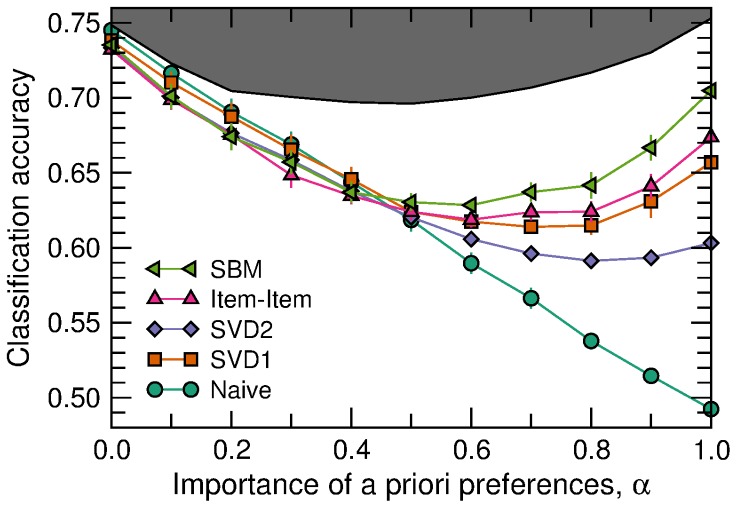
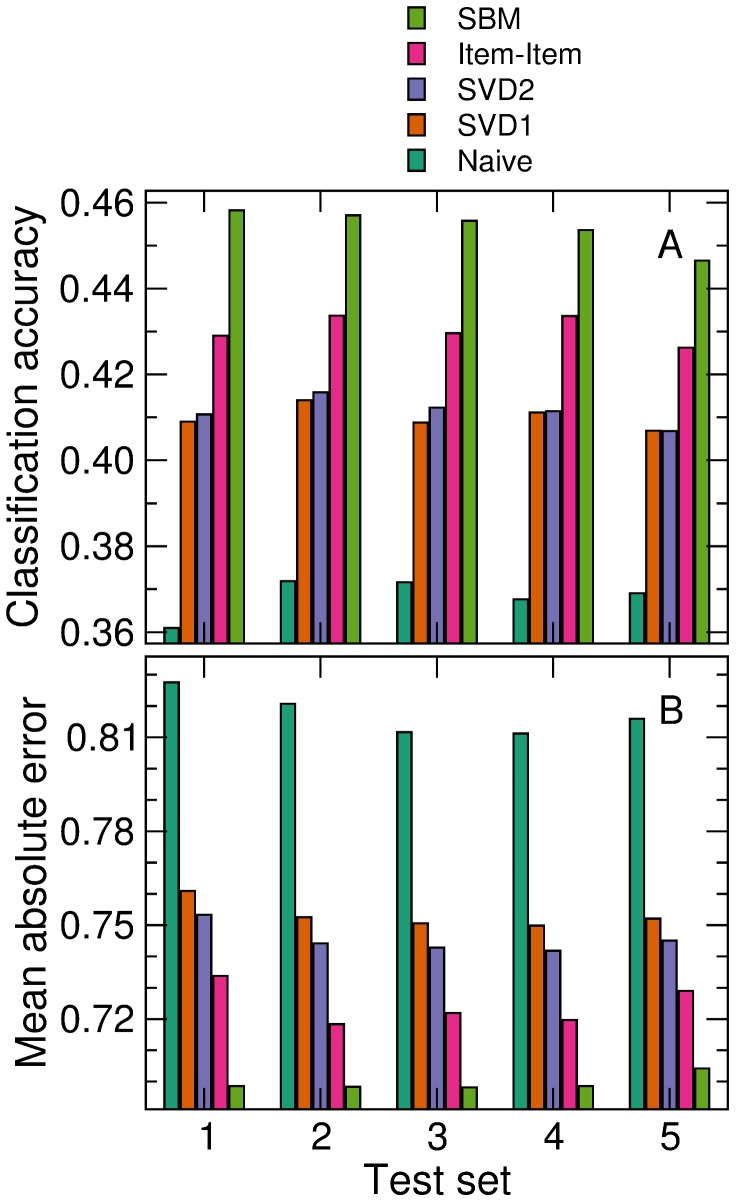
With ever-increasing available data, predicting individuals' preferences and helping them locate the most relevant information has become a pressing need. Understanding and predicting preferences is also important from a fundamental point of view, as part of what has been called a "new" computational social science. Here, we propose a novel approach based on stochastic block models, which have been developed by sociologists as plausible models of complex networks of social interactions. Our model is in the spirit of predicting individuals' preferences based on the preferences of others but, rather than fitting a particular model, we rely on a Bayesian approach that samples over the ensemble of all possible models. We show that our approach is considerably more accurate than leading recommender algorithms, with major relative improvements between 38% and 99% over industry-level algorithms. Besides, our approach sheds light on decision-making processes by identifying groups of individuals that have consistently similar preferences, and enabling the analysis of the characteristics of those groups.
随着可用数据的不断增加,预测个人偏好并帮助他们找到最相关的信息已成为当务之急。从根本的角度理解和预测偏好也很重要,这是所谓的“新”计算社会科学的一部分。在这里,我们提出了一种基于随机块模型的新方法,这些模型是由社会学家作为复杂社会互动网络的合理模型开发的。我们的模型是基于预测个人偏好的基础上,基于他人的偏好,但我们不是拟合特定的模型,而是依靠一种贝叶斯方法,对所有可能的模型进行抽样。我们表明,我们的方法比领先的推荐算法准确得多,与行业水平的算法相比,相对提高了 38%至 99%。此外,我们的方法通过识别具有一致相似偏好的个体组并能够分析这些组的特征,揭示了决策过程。