Department of Biology, North Carolina State University, Raleigh, NC 27695-7617, USA.
Database (Oxford). 2012 Nov 22;2012:bas037. doi: 10.1093/database/bas037. Print 2012.
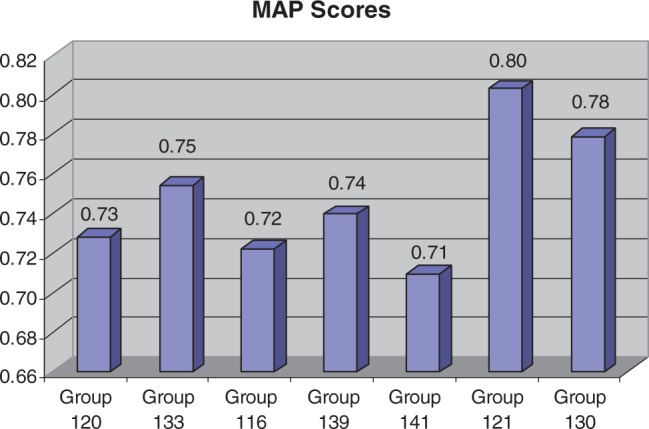
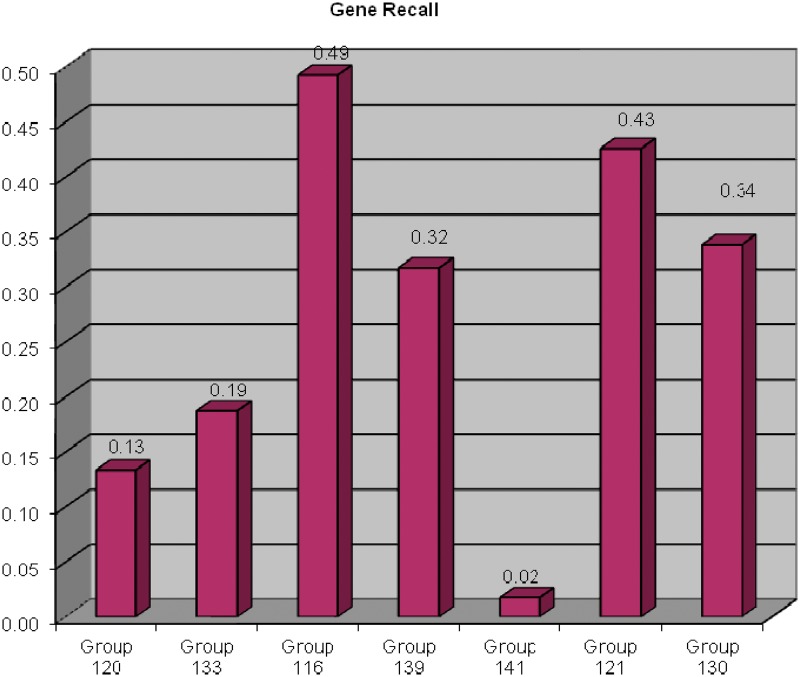
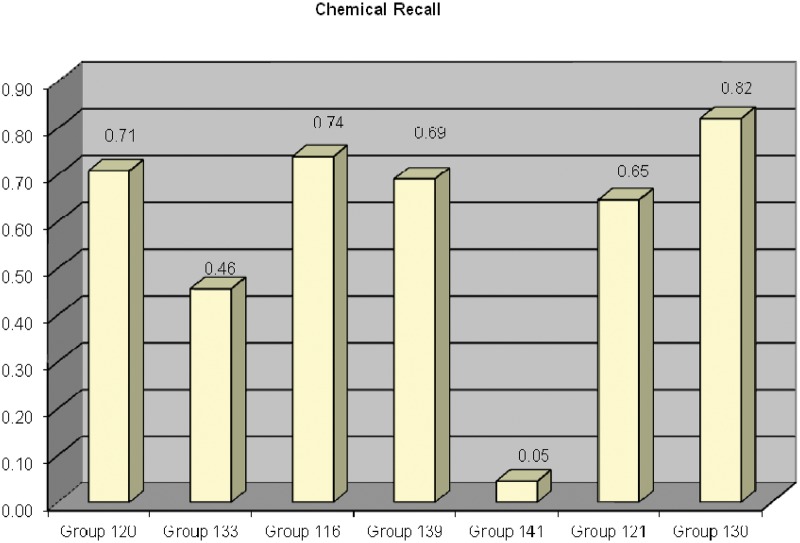
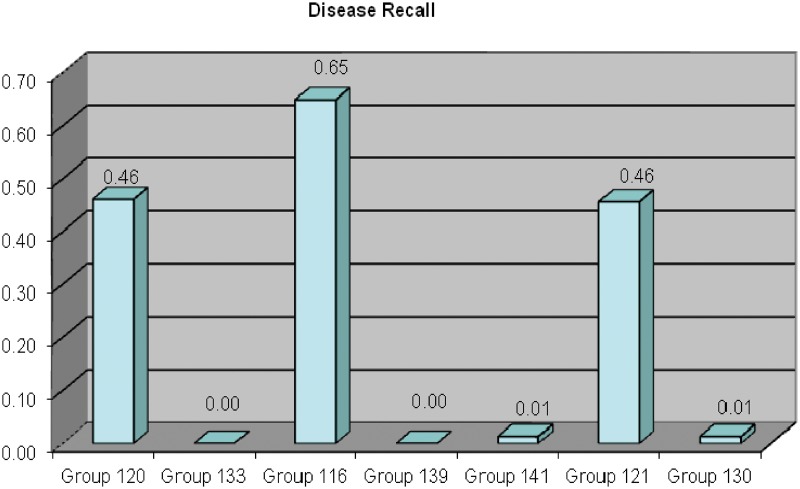
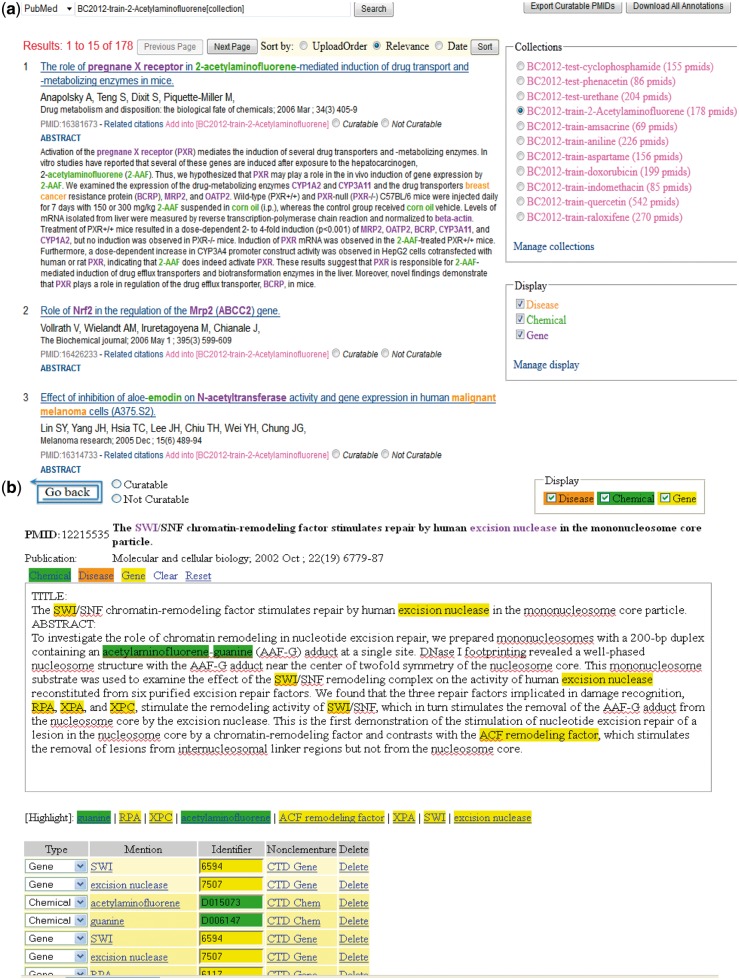
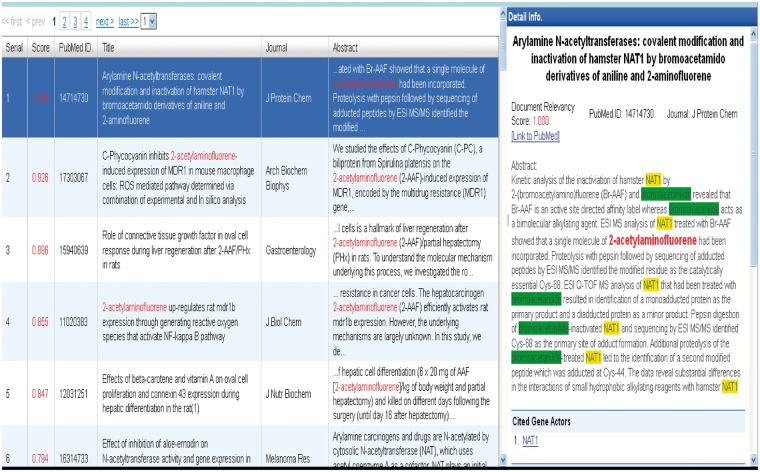
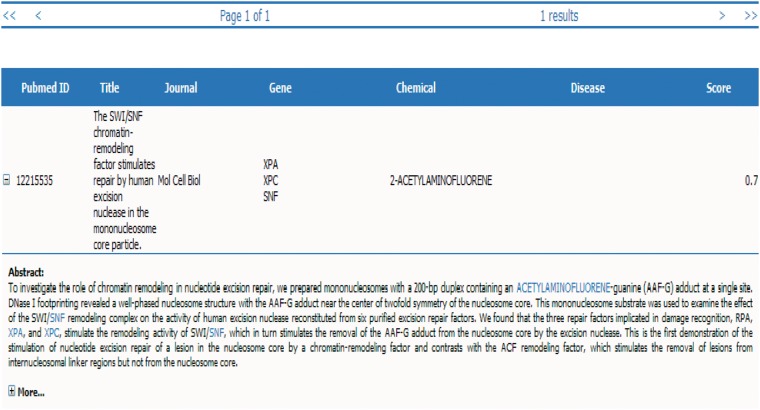
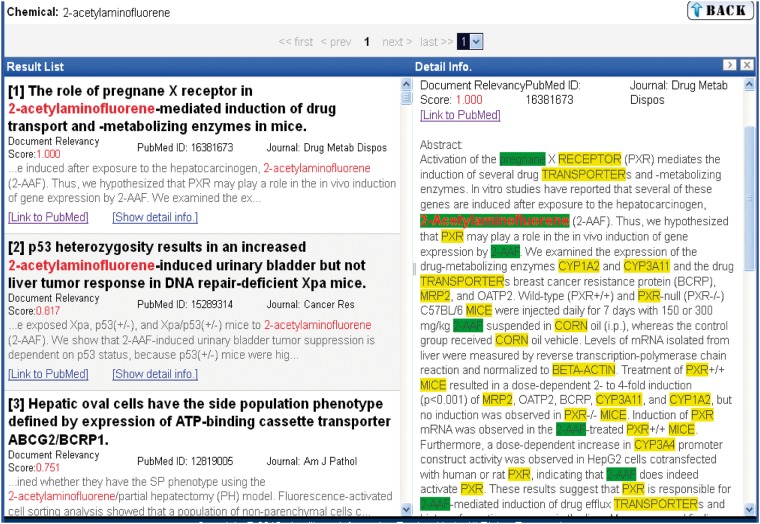
The Critical Assessment of Information Extraction systems in Biology (BioCreAtIvE) challenge evaluation is a community-wide effort for evaluating text mining and information extraction systems for the biological domain. The 'BioCreative Workshop 2012' subcommittee identified three areas, or tracks, that comprised independent, but complementary aspects of data curation in which they sought community input: literature triage (Track I); curation workflow (Track II) and text mining/natural language processing (NLP) systems (Track III). Track I participants were invited to develop tools or systems that would effectively triage and prioritize articles for curation and present results in a prototype web interface. Training and test datasets were derived from the Comparative Toxicogenomics Database (CTD; http://ctdbase.org) and consisted of manuscripts from which chemical-gene-disease data were manually curated. A total of seven groups participated in Track I. For the triage component, the effectiveness of participant systems was measured by aggregate gene, disease and chemical 'named-entity recognition' (NER) across articles; the effectiveness of 'information retrieval' (IR) was also measured based on 'mean average precision' (MAP). Top recall scores for gene, disease and chemical NER were 49, 65 and 82%, respectively; the top MAP score was 80%. Each participating group also developed a prototype web interface; these interfaces were evaluated based on functionality and ease-of-use by CTD's biocuration project manager. In this article, we present a detailed description of the challenge and a summary of the results.
生物信息提取系统的关键评估(BioCreAtIvE)挑战评估是一个社区范围内的努力,旨在评估生物领域的文本挖掘和信息提取系统。“2012 年 BioCreative 研讨会”小组委员会确定了三个领域,或跟踪,它们包含了数据管理的独立但互补的方面,他们寻求社区的投入:文献分类(Track I);策展工作流程(Track II)和文本挖掘/自然语言处理(NLP)系统(Track III)。邀请 Track I 的参与者开发工具或系统,以便有效地对文章进行分类和优先级排序,以便在原型 Web 界面中呈现结果。培训和测试数据集源自比较毒理学基因组数据库(CTD;http://ctdbase.org),由手动编辑化学-基因-疾病数据的手稿组成。共有七个小组参加了 Track I。对于分类组件,参与者系统的有效性通过文章中基因、疾病和化学“命名实体识别”(NER)的综合评估来衡量;基于“平均精度”(MAP)也衡量了“信息检索”(IR)的有效性。基因、疾病和化学 NER 的最高召回分数分别为 49%、65%和 82%;最高的 MAP 分数为 80%。每个参与小组还开发了一个原型 Web 界面;根据 CTD 的生物策展项目经理的功能和易用性对这些界面进行了评估。在本文中,我们详细介绍了挑战并总结了结果。