Wiegers Thomas C, Davis Allan Peter, Mattingly Carolyn J
Department of Biological Sciences, North Carolina State University, 139 David Clark Lab, Campus Box 7617, Raleigh, NC 27695-7617, USA
Department of Biological Sciences, North Carolina State University, 139 David Clark Lab, Campus Box 7617, Raleigh, NC 27695-7617, USA.
Database (Oxford). 2014 Jun 10;2014. doi: 10.1093/database/bau050. Print 2014.
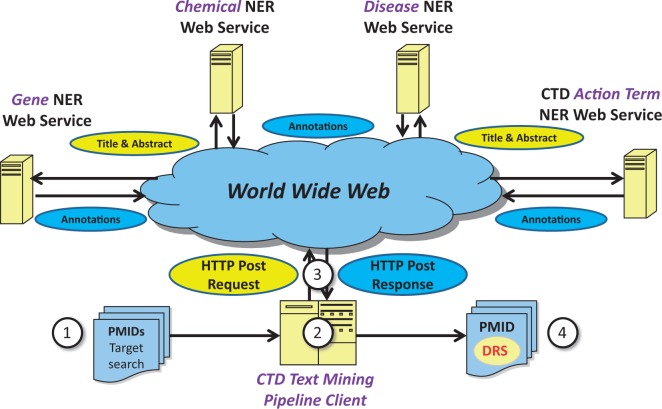
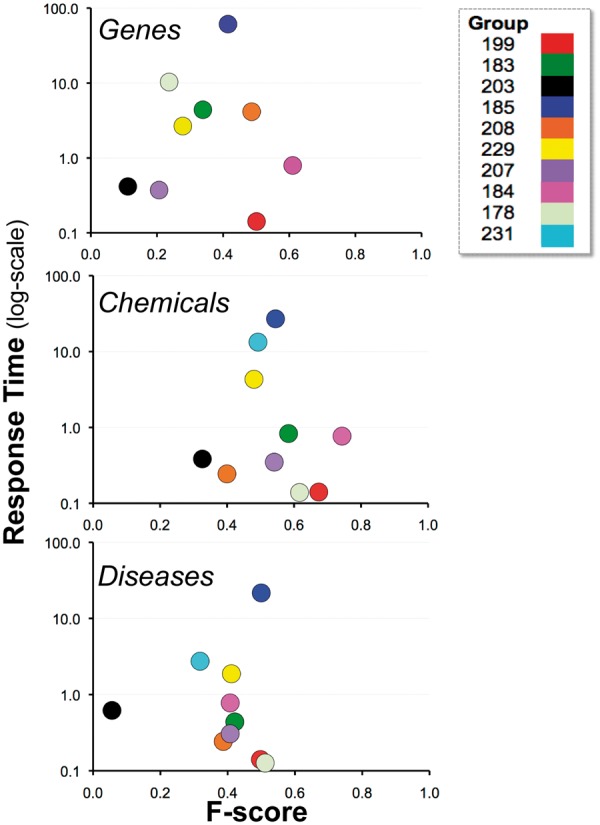
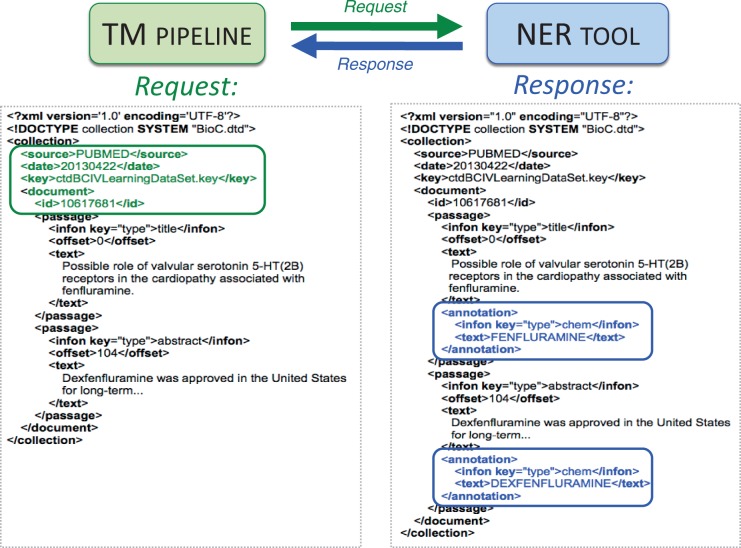
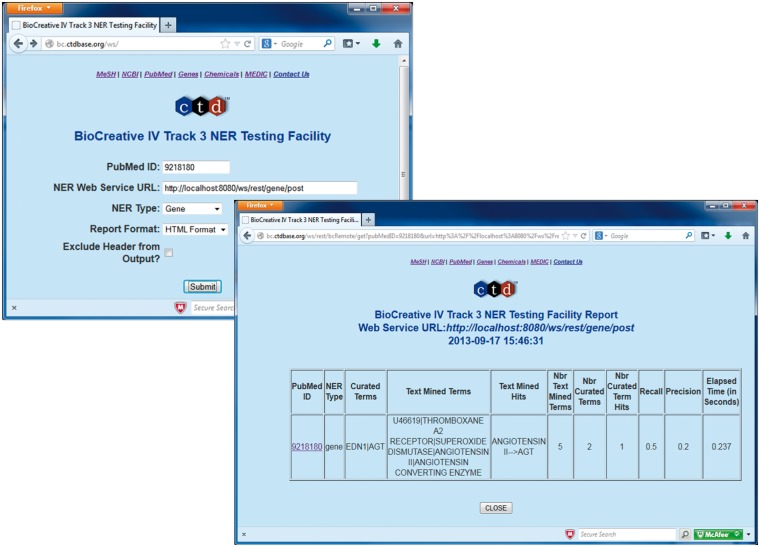
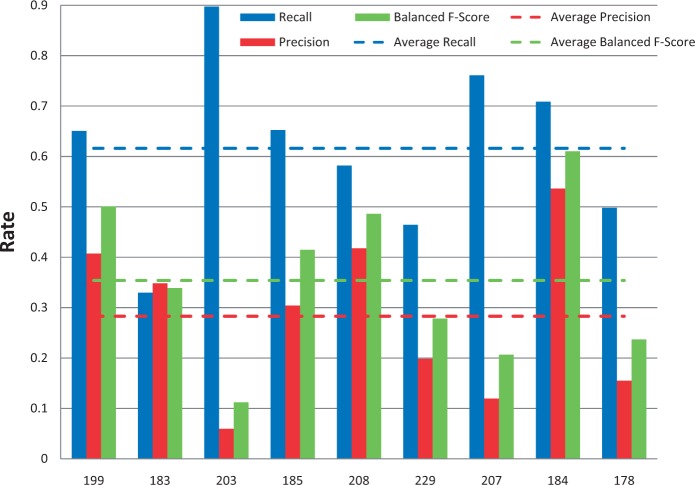
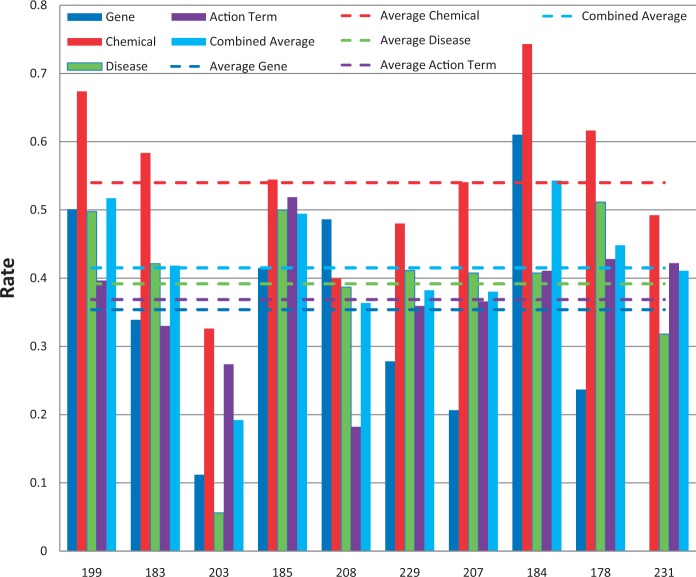
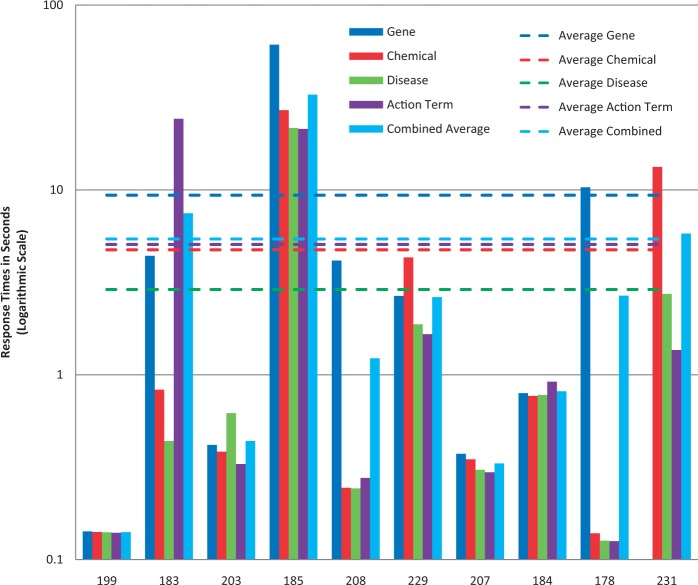
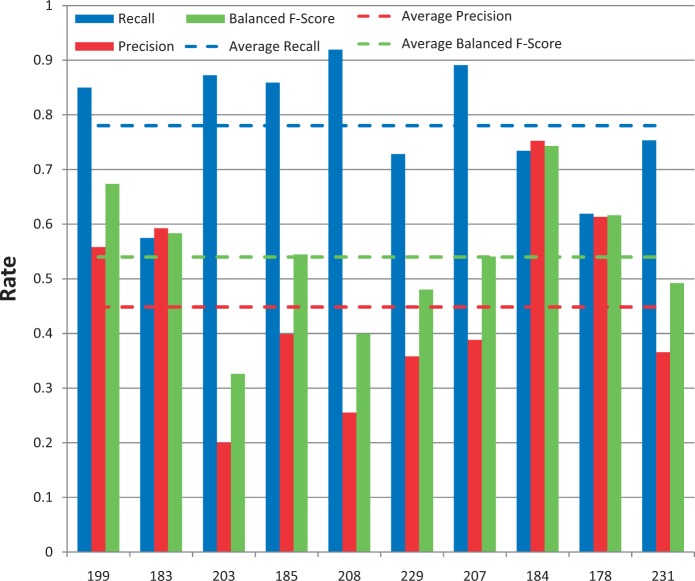
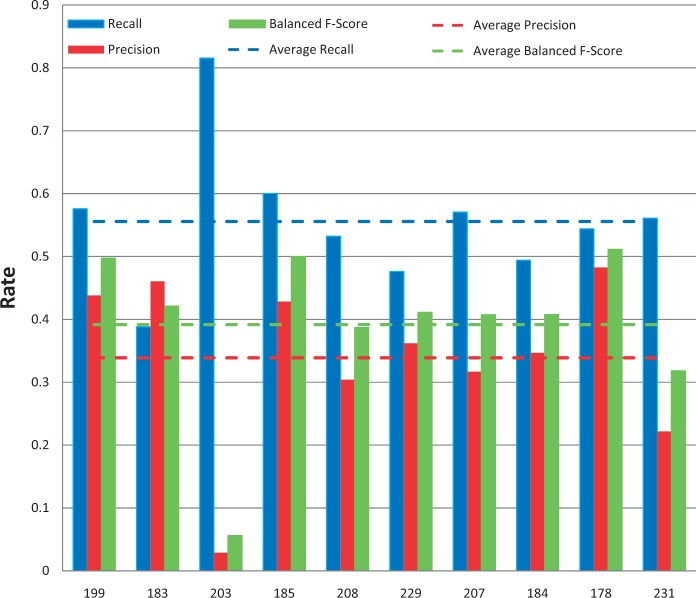
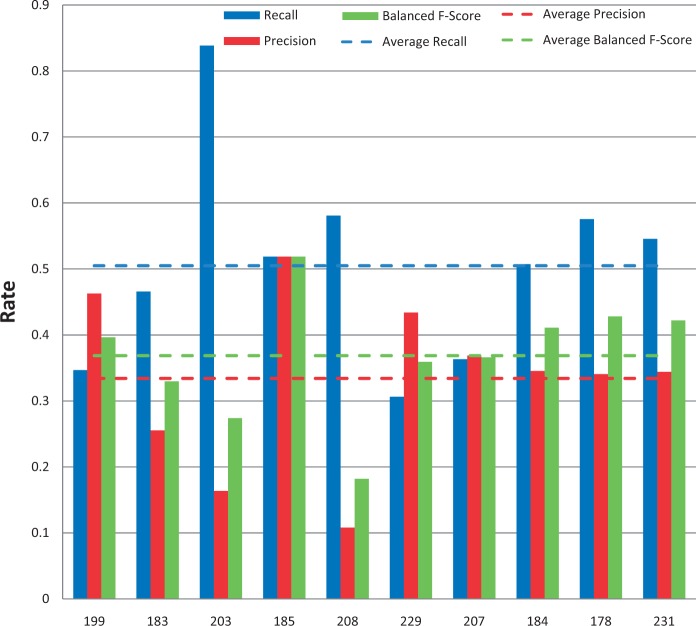
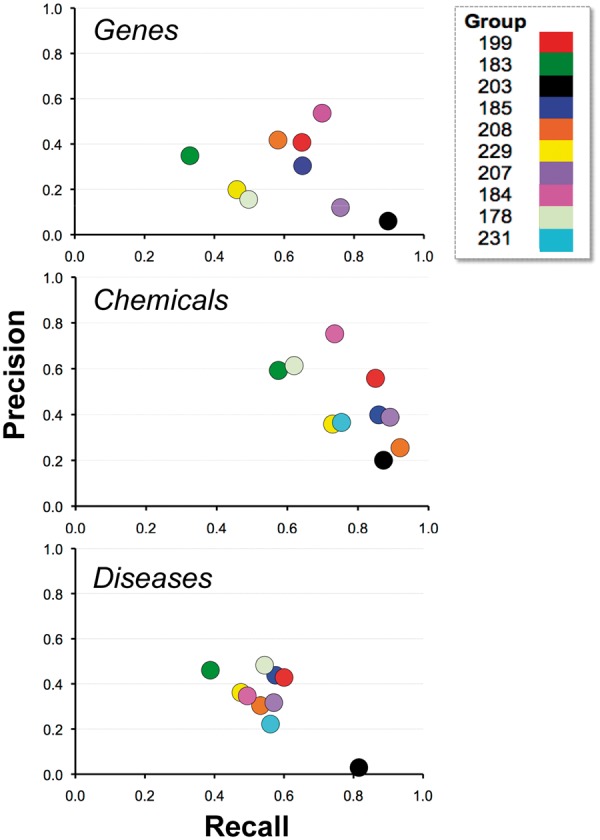
The Critical Assessment of Information Extraction systems in Biology (BioCreAtIvE) challenge evaluation tasks collectively represent a community-wide effort to evaluate a variety of text-mining and information extraction systems applied to the biological domain. The BioCreative IV Workshop included five independent subject areas, including Track 3, which focused on named-entity recognition (NER) for the Comparative Toxicogenomics Database (CTD; http://ctdbase.org). Previously, CTD had organized document ranking and NER-related tasks for the BioCreative Workshop 2012; a key finding of that effort was that interoperability and integration complexity were major impediments to the direct application of the systems to CTD's text-mining pipeline. This underscored a prevailing problem with software integration efforts. Major interoperability-related issues included lack of process modularity, operating system incompatibility, tool configuration complexity and lack of standardization of high-level inter-process communications. One approach to potentially mitigate interoperability and general integration issues is the use of Web services to abstract implementation details; rather than integrating NER tools directly, HTTP-based calls from CTD's asynchronous, batch-oriented text-mining pipeline could be made to remote NER Web services for recognition of specific biological terms using BioC (an emerging family of XML formats) for inter-process communications. To test this concept, participating groups developed Representational State Transfer /BioC-compliant Web services tailored to CTD's NER requirements. Participants were provided with a comprehensive set of training materials. CTD evaluated results obtained from the remote Web service-based URLs against a test data set of 510 manually curated scientific articles. Twelve groups participated in the challenge. Recall, precision, balanced F-scores and response times were calculated. Top balanced F-scores for gene, chemical and disease NER were 61, 74 and 51%, respectively. Response times ranged from fractions-of-a-second to over a minute per article. We present a description of the challenge and summary of results, demonstrating how curation groups can effectively use interoperable NER technologies to simplify text-mining pipeline implementation. Database URL: http://ctdbase.org/
生物学信息提取系统的关键评估(BioCreAtIvE)挑战评估任务共同代表了一项全社区范围的努力,旨在评估应用于生物领域的各种文本挖掘和信息提取系统。BioCreative IV研讨会包括五个独立的主题领域,其中第3赛道专注于比较毒理基因组学数据库(CTD;http://ctdbase.org)的命名实体识别(NER)。此前,CTD曾为2012年BioCreative研讨会组织过文档排名和与NER相关的任务;该项工作的一个关键发现是,互操作性和集成复杂性是将这些系统直接应用于CTD文本挖掘流程的主要障碍。这凸显了软件集成工作中一个普遍存在的问题。与互操作性相关的主要问题包括缺乏流程模块化、操作系统不兼容、工具配置复杂以及高层进程间通信缺乏标准化。一种可能减轻互操作性和一般集成问题的方法是使用Web服务来抽象实现细节;不是直接集成NER工具,而是从CTD的异步、面向批处理的文本挖掘流程进行基于HTTP的调用,以调用远程NER Web服务,使用BioC(一种新兴的XML格式家族)进行进程间通信来识别特定的生物术语。为了测试这一概念,参与小组开发了符合代表性状态转移/BioC标准的Web服务,以满足CTD的NER要求。为参与者提供了一套全面的培训材料。CTD根据一个由510篇人工整理的科学文章组成的测试数据集,评估了从基于远程Web服务的URL获得的结果。十二个小组参与了此次挑战。计算了召回率、精确率、平衡F分数和响应时间。基因、化学物质和疾病NER的最高平衡F分数分别为61%、74%和51%。响应时间从每篇文章几分之一秒到超过一分钟不等。我们描述了此次挑战并总结了结果,展示了编目小组如何有效地使用可互操作的NER技术来简化文本挖掘流程的实现。数据库网址:http://ctdbase.org/