Neural Computation Unit, Okinawa Institute of Science and Technology, Graduate University Okinawa, Japan.
Front Neurorobot. 2013 Feb 28;7:3. doi: 10.3389/fnbot.2013.00003. eCollection 2013.
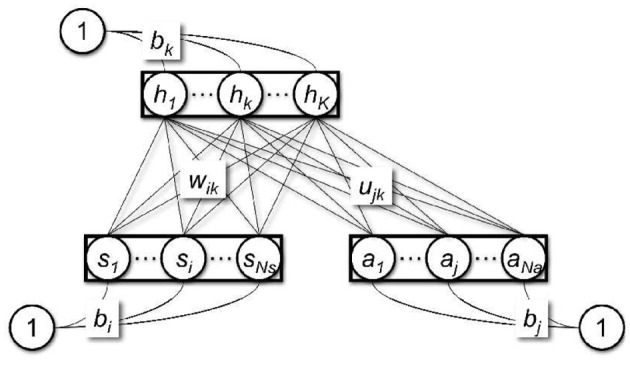
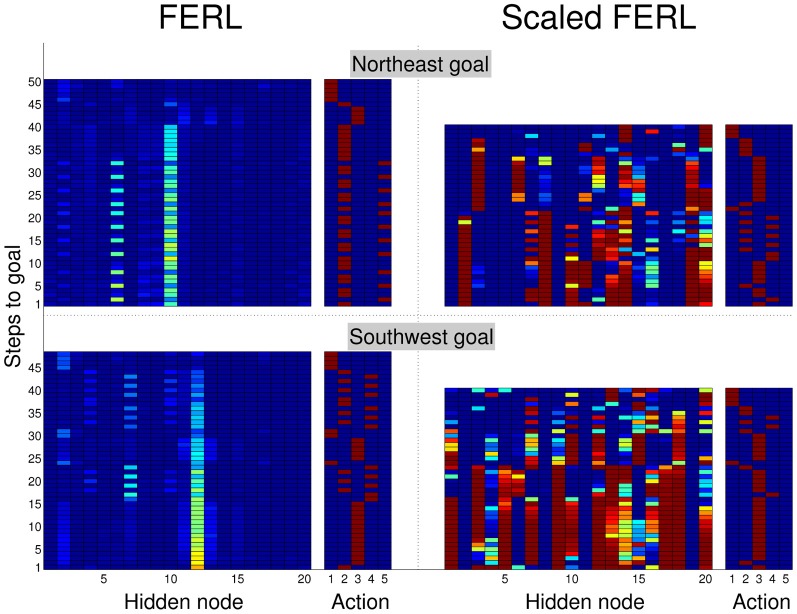
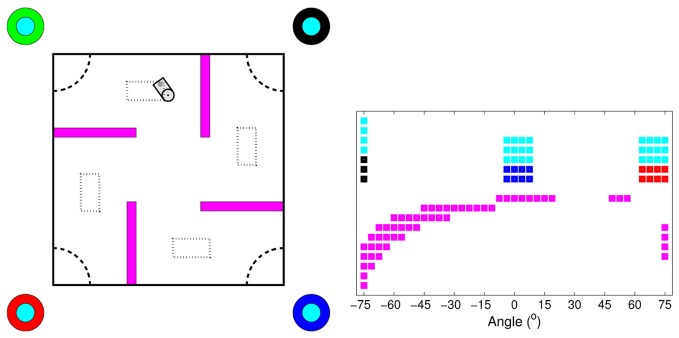
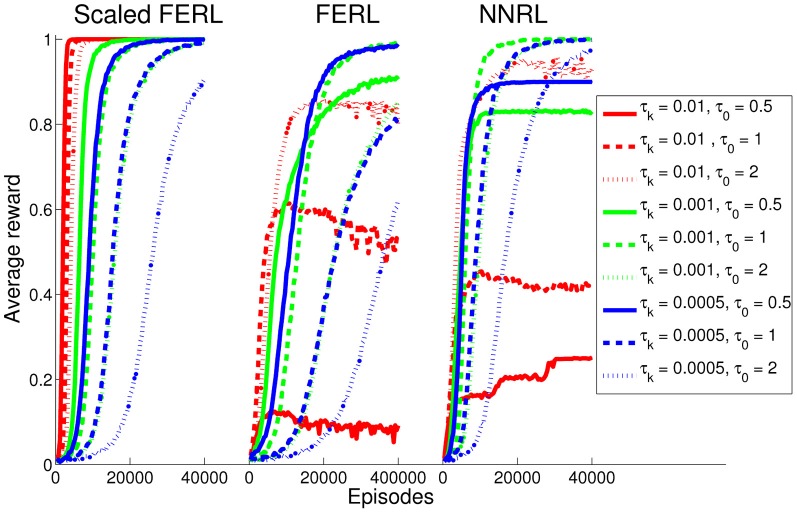
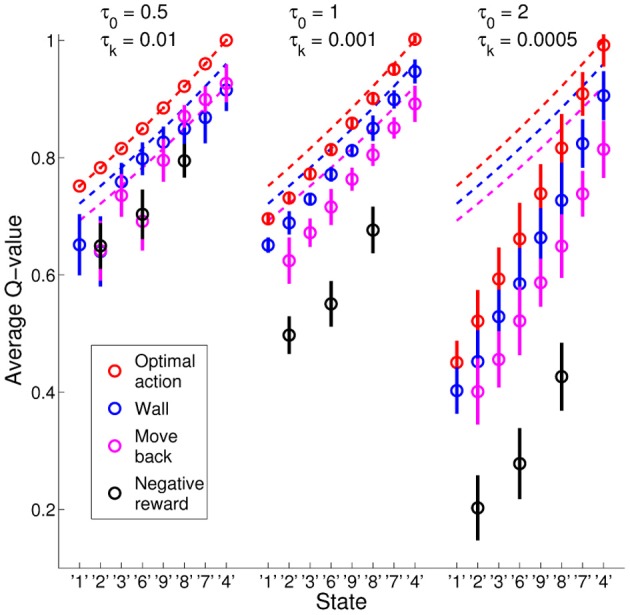
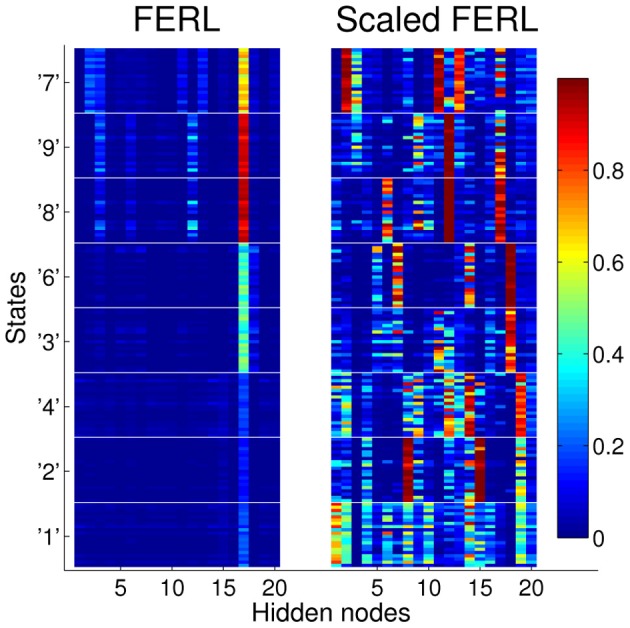
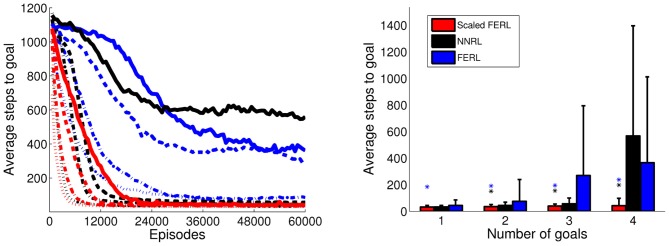
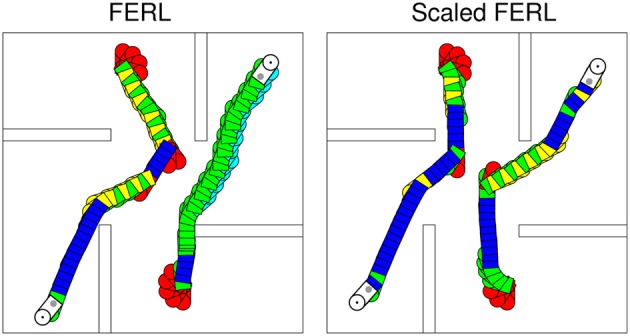
Free-energy based reinforcement learning (FERL) was proposed for learning in high-dimensional state- and action spaces, which cannot be handled by standard function approximation methods. In this study, we propose a scaled version of free-energy based reinforcement learning to achieve more robust and more efficient learning performance. The action-value function is approximated by the negative free-energy of a restricted Boltzmann machine, divided by a constant scaling factor that is related to the size of the Boltzmann machine (the square root of the number of state nodes in this study). Our first task is a digit floor gridworld task, where the states are represented by images of handwritten digits from the MNIST data set. The purpose of the task is to investigate the proposed method's ability, through the extraction of task-relevant features in the hidden layer, to cluster images of the same digit and to cluster images of different digits that corresponds to states with the same optimal action. We also test the method's robustness with respect to different exploration schedules, i.e., different settings of the initial temperature and the temperature discount rate in softmax action selection. Our second task is a robot visual navigation task, where the robot can learn its position by the different colors of the lower part of four landmarks and it can infer the correct corner goal area by the color of the upper part of the landmarks. The state space consists of binarized camera images with, at most, nine different colors, which is equal to 6642 binary states. For both tasks, the learning performance is compared with standard FERL and with function approximation where the action-value function is approximated by a two-layered feedforward neural network.
基于自由能的强化学习 (FERL) 被提出用于学习高维状态和动作空间,这是标准函数逼近方法无法处理的。在本研究中,我们提出了一种自由能的缩放版本,以实现更稳健和更有效的学习性能。动作值函数由受限玻尔兹曼机的负自由能近似,除以一个与玻尔兹曼机大小相关的常数缩放因子(在本研究中是状态节点数的平方根)。我们的第一个任务是数字地板网格世界任务,其中状态由 MNIST 数据集的手写数字图像表示。任务的目的是通过在隐藏层中提取与任务相关的特征,研究所提出的方法能够对相同数字的图像进行聚类,并对具有相同最优动作的不同数字的图像进行聚类。我们还测试了该方法对不同探索计划的鲁棒性,即软动作选择中初始温度和温度折扣率的不同设置。我们的第二个任务是机器人视觉导航任务,机器人可以通过四个地标物下部的不同颜色来学习自己的位置,并且可以通过地标物上部的颜色来推断正确的角落目标区域。状态空间由最多有九个不同颜色的二值化相机图像组成,这相当于 6642 个二值状态。对于这两个任务,将学习性能与标准 FERL 和函数逼近进行比较,其中动作值函数由两层前馈神经网络近似。