Nie Yaling, Yu Jingkai
National Key Laboratory of Biochemical Engineering, Institute of Process Engineering, Chinese Academy of Sciences, Beijing 100190, China.
BMC Syst Biol. 2013 Jun 25;7:49. doi: 10.1186/1752-0509-7-49.
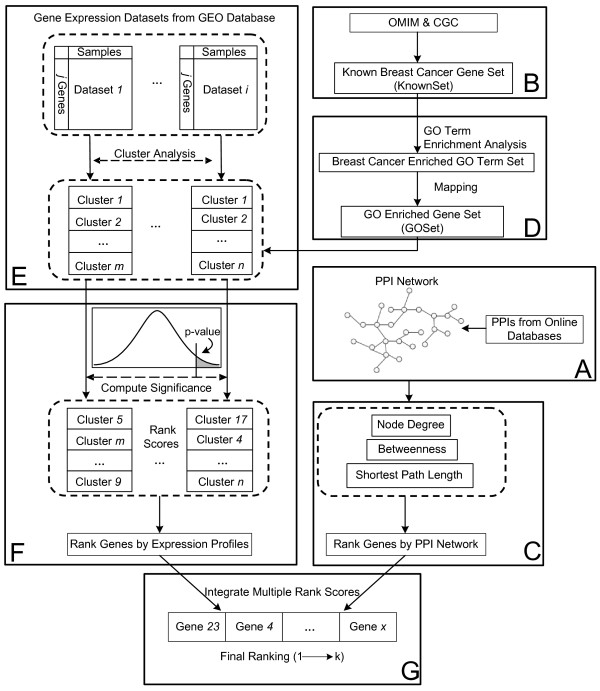
Mining novel breast cancer genes is an important task in breast cancer research. Many approaches prioritize candidate genes based on their similarity to known cancer genes, usually by integrating multiple data sources. However, different types of data often contain varying degrees of noise. For effective data integration, it's important to design methods that work robustly with respect to noise.
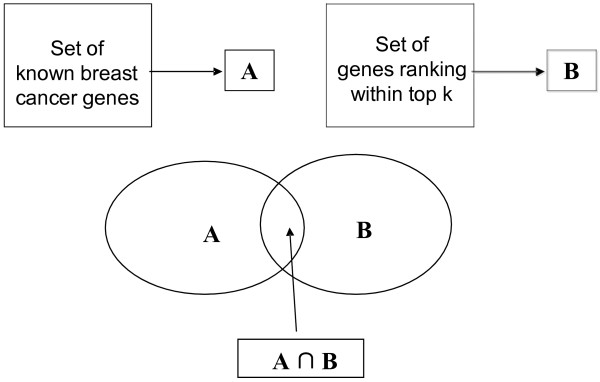
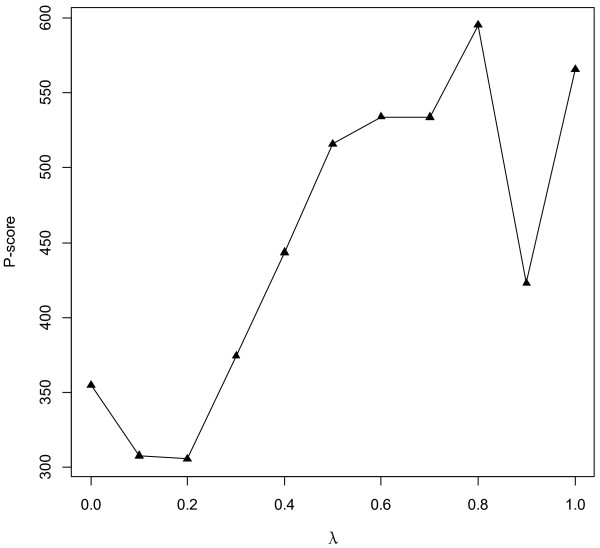
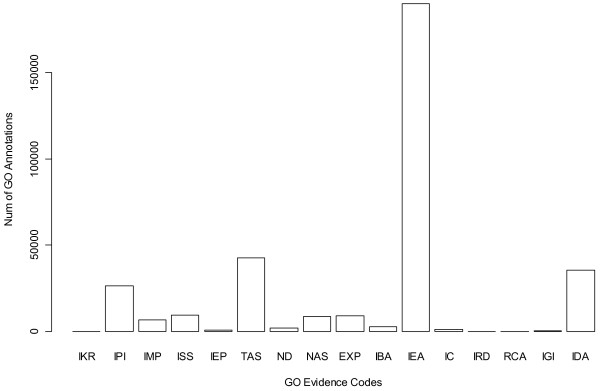
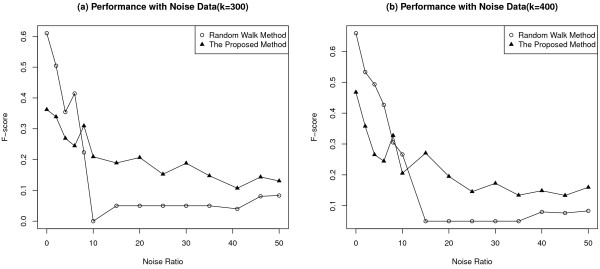
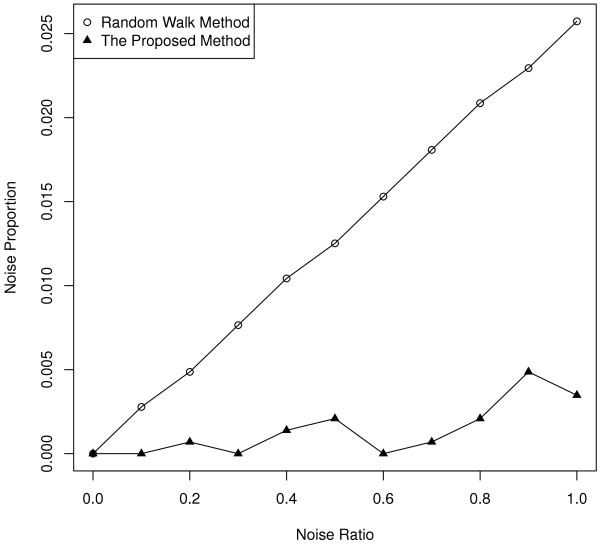
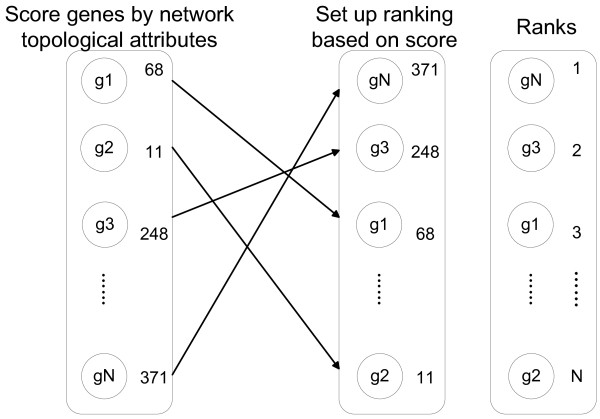
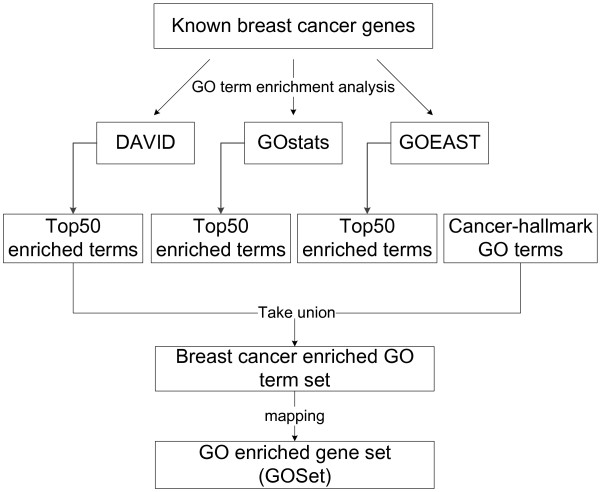
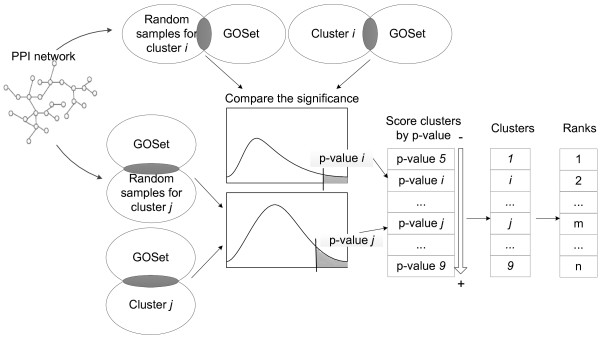
Gene Ontology (GO) annotations were often utilized in cancer gene mining works. However, the vast majority of GO annotations were computationally derived, thus not completely accurate. A set of genes annotated with breast cancer enriched GO terms was adopted here as a set of source data with realistic noise. A novel noise tolerant approach was proposed to rank candidate breast cancer genes using noisy source data within the framework of a comprehensive human Protein-Protein Interaction (PPI) network. Performance of the proposed method was quantitatively evaluated by comparing it with the more established random walk approach. Results showed that the proposed method exhibited better performance in ranking known breast cancer genes and higher robustness against data noise than the random walk approach. When noise started to increase, the proposed method was able to maintained relatively stable performance, while the random walk approach showed drastic performance decline; when noise increased to a large extent, the proposed method was still able to achieve better performance than random walk did.
A novel noise tolerant method was proposed to mine breast cancer genes. Compared to the well established random walk approach, it showed better performance in correctly ranking cancer genes and worked robustly with respect to noise within source data. To the best of our knowledge, it's the first such effort to quantitatively analyze noise tolerance between different breast cancer gene mining methods. The sorted gene list can be valuable for breast cancer research. The proposed quantitative noise analysis method may also prove useful for other data integration efforts. It is hoped that the current work can lead to more discussions about influence of data noise on different computational methods for mining disease genes.
挖掘新型乳腺癌基因是乳腺癌研究中的一项重要任务。许多方法通常通过整合多个数据源,根据候选基因与已知癌症基因的相似性对其进行优先级排序。然而,不同类型的数据往往包含不同程度的噪声。为了实现有效的数据整合,设计对噪声具有鲁棒性的方法非常重要。
基因本体论(GO)注释常用于癌症基因挖掘工作。然而,绝大多数GO注释是通过计算得出的,因此并不完全准确。这里采用一组用乳腺癌富集的GO术语注释的基因作为具有实际噪声的源数据集。提出了一种新的抗噪声方法,在综合人类蛋白质-蛋白质相互作用(PPI)网络框架内,使用有噪声的源数据对候选乳腺癌基因进行排名。通过与更成熟的随机游走方法进行比较,对所提出方法的性能进行了定量评估。结果表明,与随机游走方法相比,该方法在对已知乳腺癌基因进行排名时表现出更好的性能,并且对数据噪声具有更高的鲁棒性。当噪声开始增加时,该方法能够保持相对稳定的性能,而随机游走方法的性能则急剧下降;当噪声大幅增加时,该方法仍能比随机游走方法取得更好的性能。
提出了一种新的抗噪声方法来挖掘乳腺癌基因。与成熟的随机游走方法相比,它在正确排名癌症基因方面表现出更好的性能,并且对源数据中的噪声具有鲁棒性。据我们所知,这是首次对不同乳腺癌基因挖掘方法之间的抗噪声能力进行定量分析。排序后的基因列表对乳腺癌研究可能具有重要价值。所提出的定量噪声分析方法可能对其他数据整合工作也有用。希望当前的工作能够引发更多关于数据噪声对挖掘疾病基因的不同计算方法影响的讨论。