Gautam Poonam, Nair Sudha C, Ramamoorthy Kalidoss, Swamy Cherukuvada V Brahmendra, Nagaraj Ramakrishnan
CSIR- Centre for Cellular and Molecular Biology, Hyderabad, India.
PLoS One. 2013 Aug 20;8(8):e72584. doi: 10.1371/journal.pone.0072584. eCollection 2013.
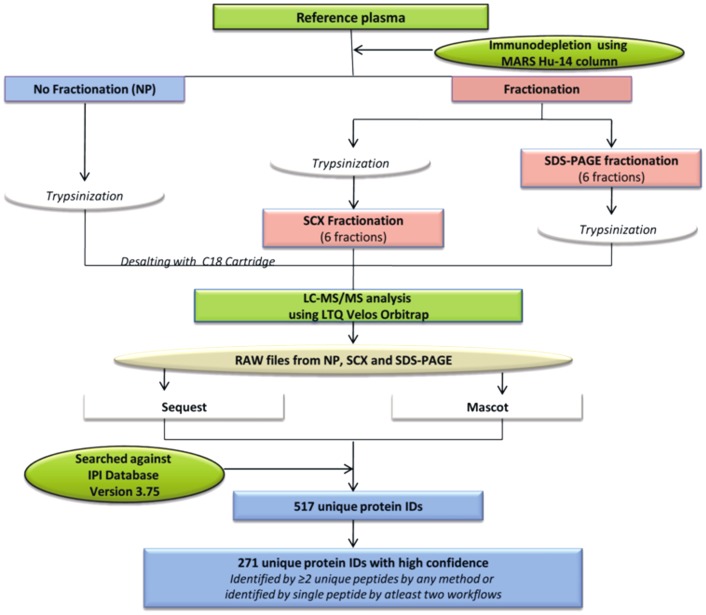
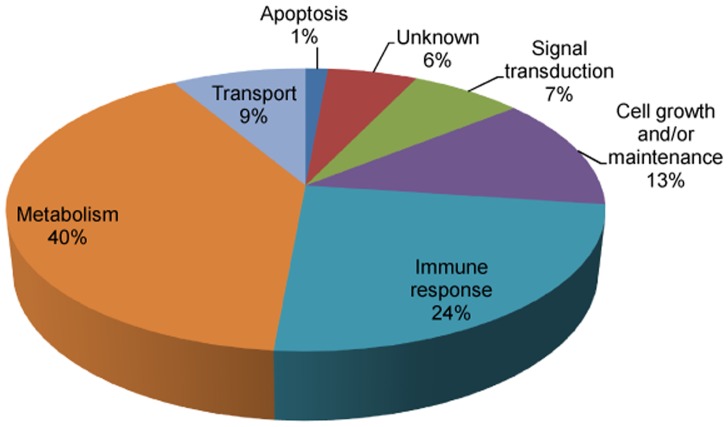
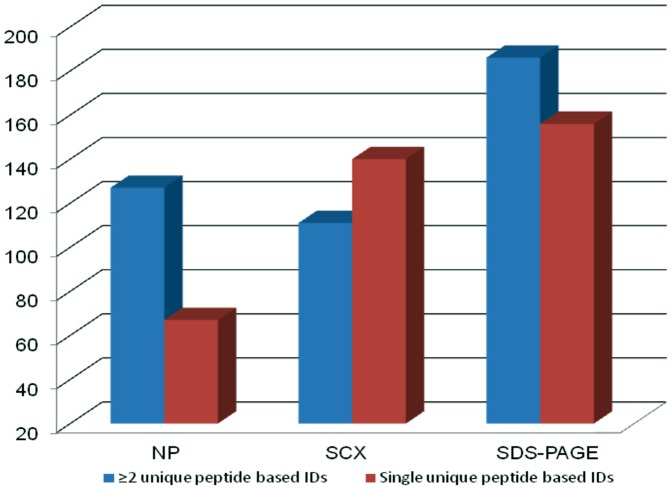
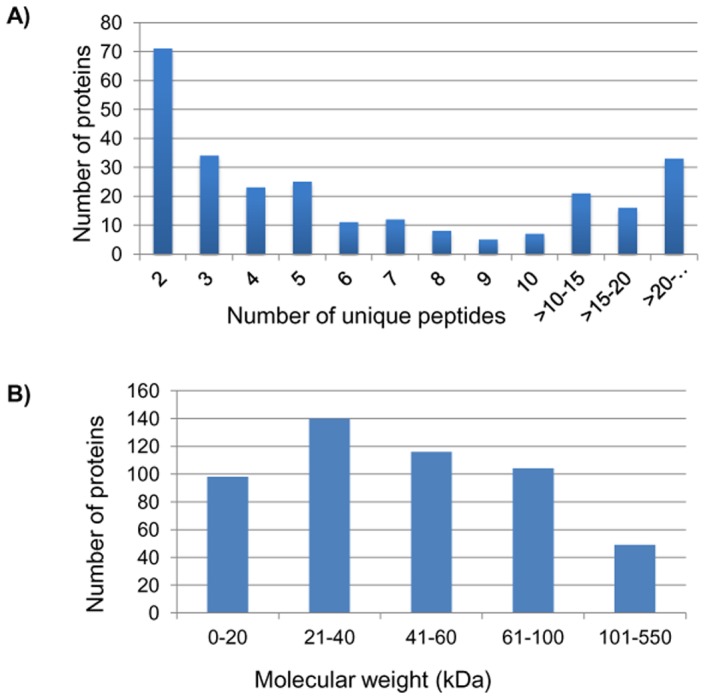
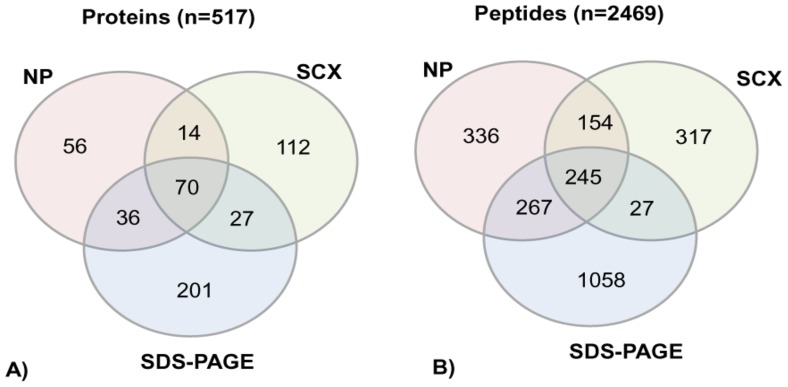
Analysis of any mammalian plasma proteome is a challenge, particularly by mass spectrometry, due to the presence of albumin and other abundant proteins which can mask the detection of low abundant proteins. As detection of human plasma proteins is valuable in diagnostics, exploring various workflows with minimal fractionation prior to mass spectral analysis, is required in order to study population diversity involving analysis in a large cohort of samples. Here, we used 'reference plasma sample', a pool of plasma from 10 healthy individuals from Indian population in the age group of 25-60 yrs including 5 males and 5 females. The 14 abundant proteins were immunodepleted from plasma and then evaluated by three different workflows for proteome analysis using a nanoflow reverse phase liquid chromatography system coupled to a LTQ Orbitrap Velos mass spectrometer. The analysis of reference plasma sample a) without prefractionation, b) after prefractionation at peptide level by strong cation exchange chromatography and c) after prefractionation at protein level by sodium dodecyl sulfate polyacrylamide gel electrophoresis, led to the identification of 194, 251 and 342 proteins respectively. Together, a comprehensive dataset of 517 unique proteins was achieved from all the three workflows, including 271 proteins with high confidence identified by ≥ 2 unique peptides in any of the workflows or identified by single peptide in any of the two workflows. A total of 70 proteins were common in all the three workflows. Some of the proteins were unique to our study and could be specific to Indian population. The high-confidence dataset obtained from our study may be useful for studying the population diversity, in discovery and validation process for biomarker identification.
对任何哺乳动物的血浆蛋白质组进行分析都是一项挑战,尤其是通过质谱分析时,因为存在白蛋白和其他丰富的蛋白质,它们可能会掩盖低丰度蛋白质的检测。由于检测人血浆蛋白质在诊断中具有重要价值,因此在质谱分析之前需要探索各种尽可能少分级分离的工作流程,以便在大量样本队列中进行分析以研究群体多样性。在这里,我们使用了“参考血浆样本”,这是一组来自印度人群、年龄在25至60岁之间的10名健康个体的血浆,其中包括5名男性和5名女性。从血浆中免疫去除14种丰富的蛋白质,然后使用与LTQ Orbitrap Velos质谱仪联用的纳流反相液相色谱系统,通过三种不同的工作流程对蛋白质组进行分析评估。对参考血浆样本进行分析:a)不进行预分级分离,b)在肽水平通过强阳离子交换色谱进行预分级分离后,c)在蛋白质水平通过十二烷基硫酸钠聚丙烯酰胺凝胶电泳进行预分级分离后,分别鉴定出194、251和342种蛋白质。总共,从所有这三种工作流程中获得了一个包含517种独特蛋白质的综合数据集,其中包括271种高可信度蛋白质,这些蛋白质在任何一种工作流程中由≥2个独特肽段鉴定,或在任何两种工作流程中由单个肽段鉴定。在所有这三种工作流程中共有70种蛋白质。其中一些蛋白质是我们研究特有的,可能是印度人群特有的。我们研究中获得的高可信度数据集可能有助于在生物标志物鉴定的发现和验证过程中研究群体多样性。