College of Computer Science and Technology in the Jilin University.
College of Computer Science and Technology in Changchun University.
Brief Bioinform. 2021 Jan 18;22(1):315-333. doi: 10.1093/bib/bbz160.
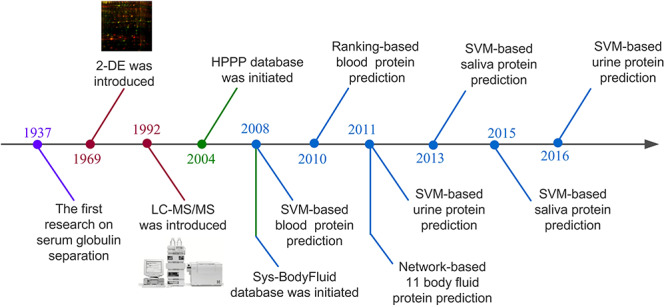
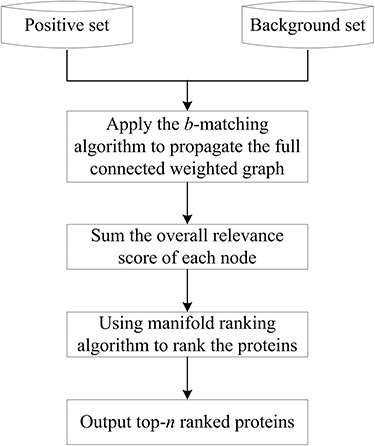
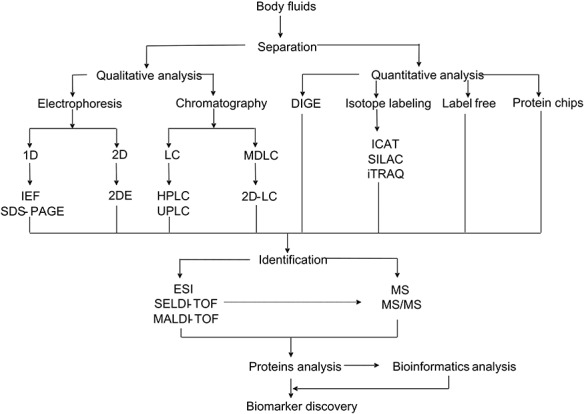
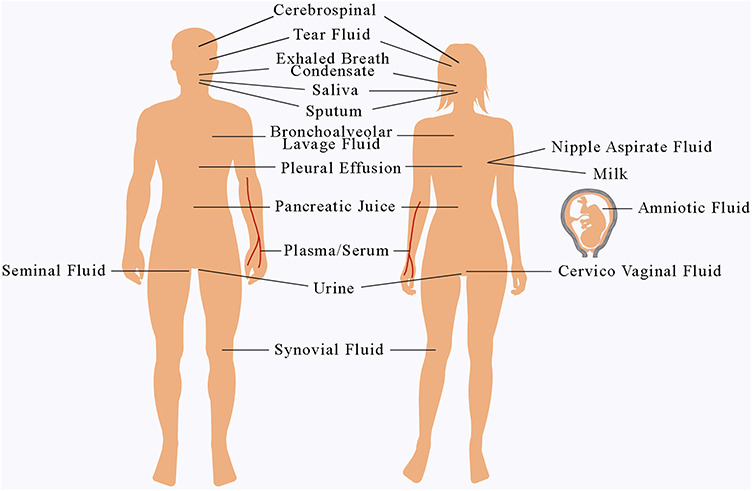
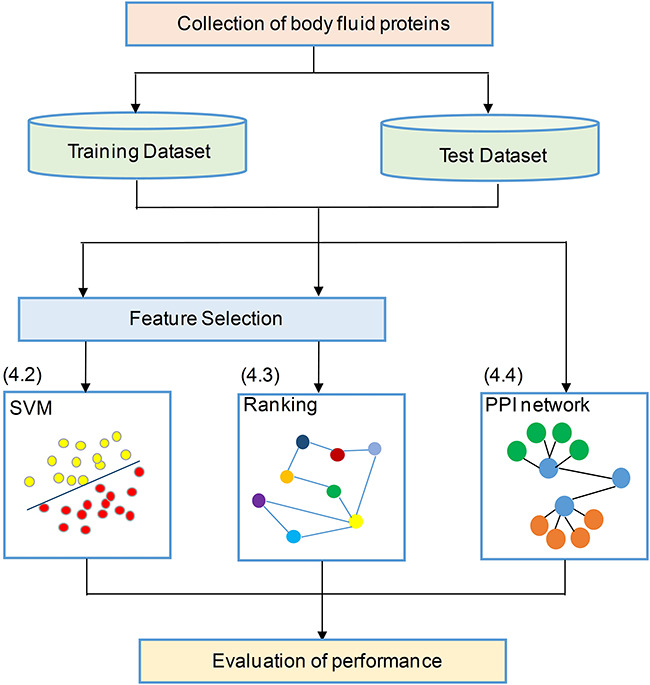
Empowered by the advancement of high-throughput bio technologies, recent research on body-fluid proteomes has led to the discoveries of numerous novel disease biomarkers and therapeutic drugs. In the meantime, a tremendous progress in disclosing the body-fluid proteomes was made, resulting in a collection of over 15 000 different proteins detected in major human body fluids. However, common challenges remain with current proteomics technologies about how to effectively handle the large variety of protein modifications in those fluids. To this end, computational effort utilizing statistical and machine-learning approaches has shown early successes in identifying biomarker proteins in specific human diseases. In this article, we first summarized the experimental progresses using a combination of conventional and high-throughput technologies, along with the major discoveries, and focused on current research status of 16 types of body-fluid proteins. Next, the emerging computational work on protein prediction based on support vector machine, ranking algorithm, and protein-protein interaction network were also surveyed, followed by algorithm and application discussion. At last, we discuss additional critical concerns about these topics and close the review by providing future perspectives especially toward the realization of clinical disease biomarker discovery.
在高通量生物技术进步的推动下,近期对体液蛋白质组的研究导致了许多新型疾病生物标志物和治疗药物的发现。与此同时,在揭示体液蛋白质组方面也取得了巨大进展,在主要人体体液中检测到了超过 15000 种不同的蛋白质。然而,目前的蛋白质组学技术仍然面临着如何有效处理这些体液中大量蛋白质修饰的常见挑战。为此,利用统计和机器学习方法的计算工作在识别特定人类疾病中的生物标志物蛋白方面已经显示出了早期的成功。在本文中,我们首先总结了使用传统和高通量技术相结合的实验进展,以及主要发现,并重点介绍了 16 种体液蛋白质的当前研究现状。接下来,还调查了基于支持向量机、排序算法和蛋白质-蛋白质相互作用网络的蛋白质预测的新兴计算工作,然后进行了算法和应用讨论。最后,我们讨论了这些主题的其他关键问题,并提供了未来的展望,特别是在实现临床疾病生物标志物发现方面。