Department of Biomedical Informatics, Columbia University, New York, New York, USA.
J Am Med Inform Assoc. 2014 Mar-Apr;21(2):231-7. doi: 10.1136/amiajnl-2013-002159. Epub 2013 Dec 2.
The volume of healthcare data is growing rapidly with the adoption of health information technology. We focus on automated ICD9 code assignment from discharge summary content and methods for evaluating such assignments.
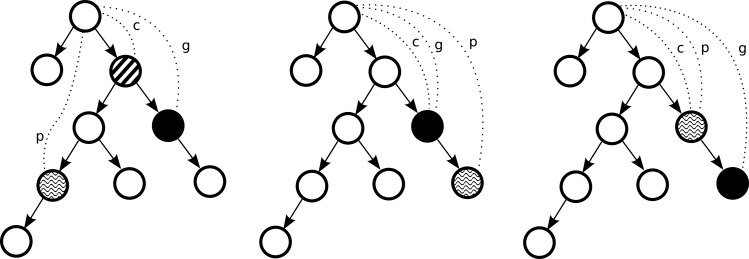
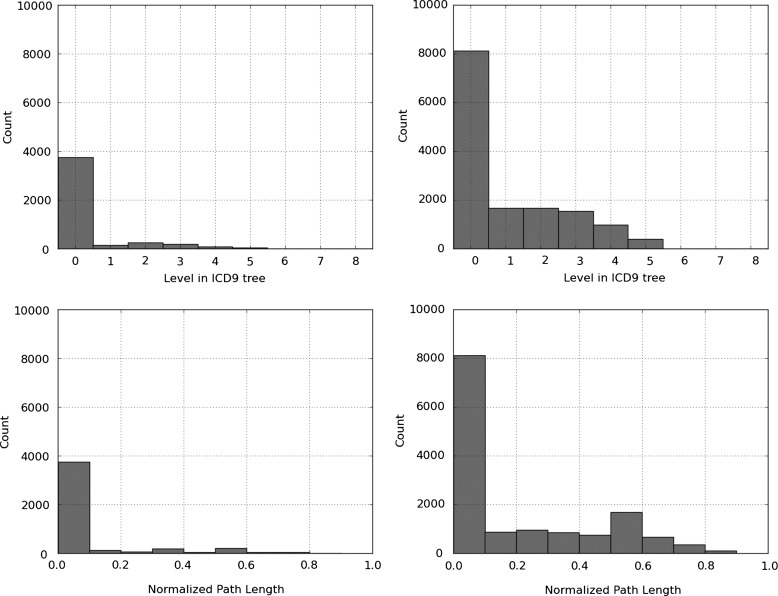
We study ICD9 diagnosis codes and discharge summaries from the publicly available Multiparameter Intelligent Monitoring in Intensive Care II (MIMIC II) repository. We experiment with two coding approaches: one that treats each ICD9 code independently of each other (flat classifier), and one that leverages the hierarchical nature of ICD9 codes into its modeling (hierarchy-based classifier). We propose novel evaluation metrics, which reflect the distances among gold-standard and predicted codes and their locations in the ICD9 tree. Experimental setup, code for modeling, and evaluation scripts are made available to the research community.
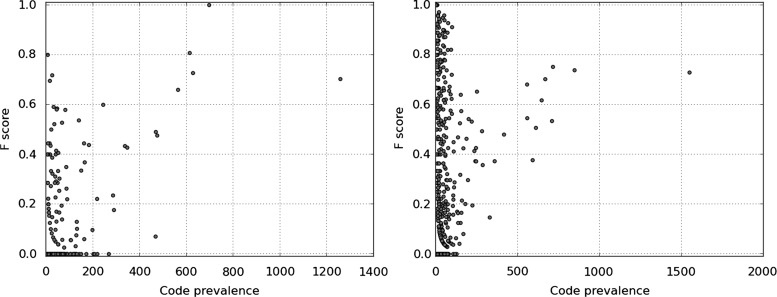
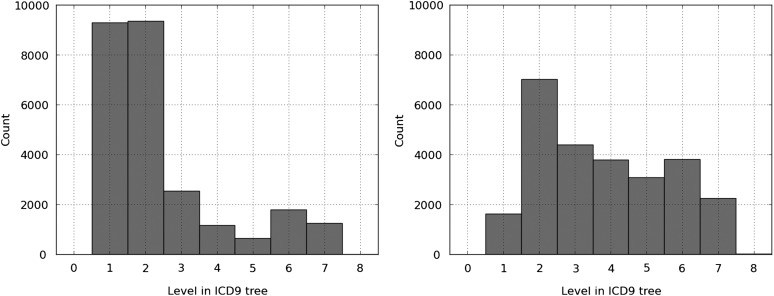
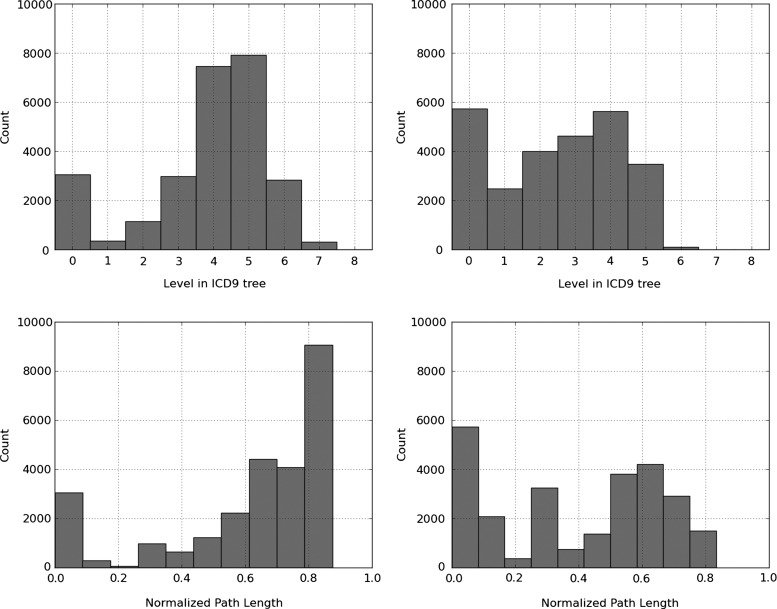
The hierarchy-based classifier outperforms the flat classifier with F-measures of 39.5% and 27.6%, respectively, when trained on 20,533 documents and tested on 2282 documents. While recall is improved at the expense of precision, our novel evaluation metrics show a more refined assessment: for instance, the hierarchy-based classifier identifies the correct sub-tree of gold-standard codes more often than the flat classifier. Error analysis reveals that gold-standard codes are not perfect, and as such the recall and precision are likely underestimated.
Hierarchy-based classification yields better ICD9 coding than flat classification for MIMIC patients. Automated ICD9 coding is an example of a task for which data and tools can be shared and for which the research community can work together to build on shared models and advance the state of the art.
随着健康信息技术的采用,医疗保健数据的数量迅速增长。我们专注于从出院总结内容中自动分配 ICD9 代码,以及评估此类分配的方法。
我们研究了公共可用的 Multiparameter Intelligent Monitoring in Intensive Care II (MIMIC II) 存储库中的 ICD9 诊断代码和出院总结。我们尝试了两种编码方法:一种是独立处理每个 ICD9 代码的方法(平面分类器),另一种是利用 ICD9 代码的层次结构对其进行建模的方法(基于层次结构的分类器)。我们提出了新的评估指标,反映了金标准和预测代码之间的距离及其在 ICD9 树中的位置。实验设置、建模代码和评估脚本可供研究社区使用。
基于层次结构的分类器在 20533 个文档上进行训练并在 2282 个文档上进行测试时,其 F 度量分别为 39.5%和 27.6%,优于平面分类器。虽然召回率提高了,但精度却有所下降,但我们的新评估指标提供了更精细的评估:例如,基于层次结构的分类器比平面分类器更经常识别出金标准代码的正确子树。错误分析表明,金标准代码并不完美,因此召回率和精度可能被低估。
基于层次结构的分类比 MIMIC 患者的平面分类产生更好的 ICD9 编码。自动 ICD9 编码是一个可以共享数据和工具的任务的示例,研究社区可以共同努力,基于共享模型进行构建并推进技术的发展。