Guo Jia, Kiryluk Krzysztof, Wang Shuang
Department of Biostatistics, Columbia University, New York, NY 10032, United States.
Department of Medicine, Columbia University, New York, NY 10032, United States.
JAMIA Open. 2024 Sep 14;7(3):ooae084. doi: 10.1093/jamiaopen/ooae084. eCollection 2024 Oct.
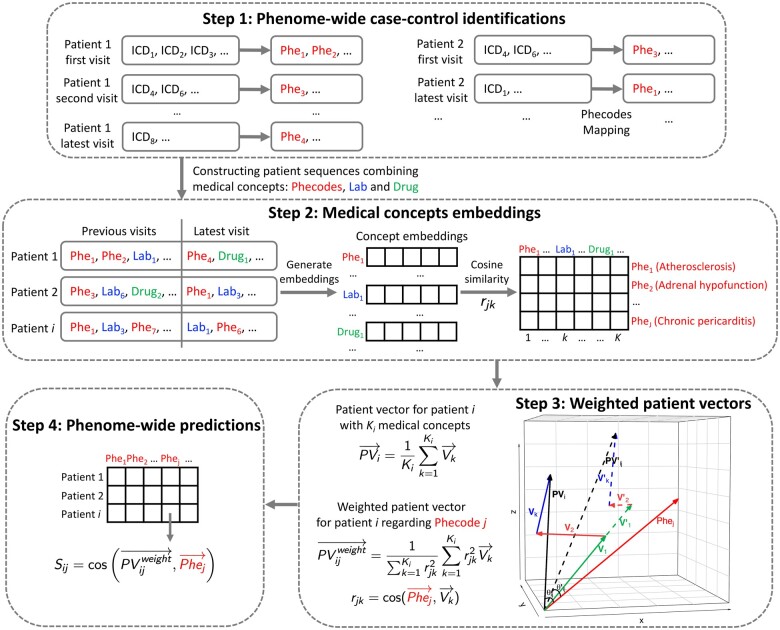
Electronic health records (EHRs) provide opportunities for the development of computable predictive tools. Conventional machine learning methods and deep learning methods have been widely used for this task, with the approach of usually designing one tool for one clinical outcome. Here we developed PheWP2V, a nome-ide prediction framework using eighted atient ectors. PheWP2V conducts tailored predictions for phenome-wide phenotypes using numeric representations of patients' past medical records weighted based on their similarities with individual phenotypes.
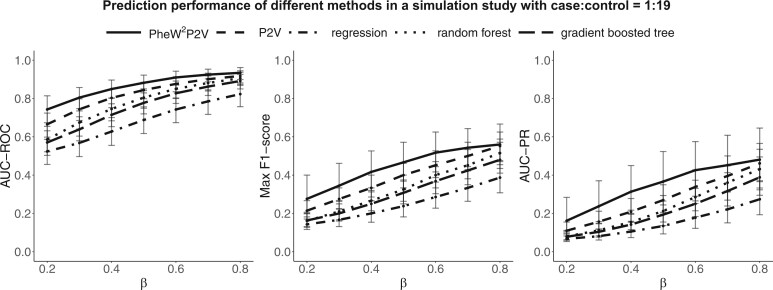
PheWP2V defines clinical disease phenotypes using Phecode mapping based on International Classification of Disease codes, which reduces redundancy and case-control misclassification in real-life EHR datasets. Through upweighting medical records of patients that are more relevant to a phenotype of interest in calculating patient vectors, PheWP2V achieves tailored incidence risk prediction of a phenotype. The calculation of weighted patient vectors is computationally efficient, and the weighting mechanism ensures tailored predictions across the phenome. We evaluated prediction performance of PheWP2V and baseline methods with simulation studies and clinical applications using the MIMIC-III database.
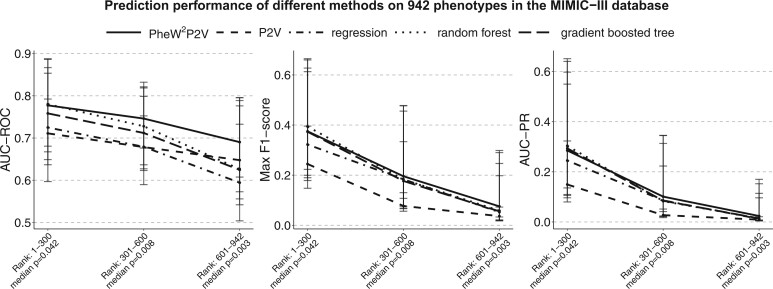
Across 942 phenome-wide predictions using the MIMIC-III database, PheWP2V has median area under the receiver operating characteristic curve (AUC-ROC) 0.74 (baseline methods have values ≤0.72), median max F-score 0.20 (baseline methods have values ≤0.19), and median area under the precision-recall curve (AUC-PR) 0.10 (baseline methods have values ≤0.10).
PheWP2V can predict phenotypes efficiently by using medical concept embeddings and upweighting relevant past medical histories. By leveraging both labeled and unlabeled data, PheWP2V reduces overfitting and improves predictions for rare phenotypes, making it a useful screening tool for early diagnosis of high-risk conditions, though further research is needed to assess the transferability of embeddings across different databases.
PheWP2V is fast, flexible, and has superior prediction performance for many clinical disease phenotypes across the phenome of the MIMIC-III database compared to that of several popular baseline methods.
电子健康记录(EHRs)为可计算预测工具的开发提供了机会。传统机器学习方法和深度学习方法已广泛用于此任务,通常是针对一种临床结果设计一种工具。在此,我们开发了PheWP2V,一种使用加权患者向量的全表型预测框架。PheWP2V使用基于患者既往病历的数字表示形式(根据其与个体表型的相似性进行加权),对全表型范围内的表型进行定制预测。
PheWP2V使用基于疾病国际分类代码的Phecode映射来定义临床疾病表型,这减少了现实生活EHR数据集中的冗余和病例对照错误分类。通过在计算患者向量时对与感兴趣表型更相关的患者病历进行加权,PheWP2V实现了对表型的定制发病率风险预测。加权患者向量的计算在计算上是高效的,并且加权机制确保了全表型范围内的定制预测。我们使用MIMIC-III数据库通过模拟研究和临床应用评估了PheWP2V和基线方法的预测性能。
在使用MIMIC-III数据库进行的942次全表型预测中,PheWP2V的受试者操作特征曲线下面积(AUC-ROC)中位数为0.74(基线方法的值≤0.72),最大F分数中位数为0.20(基线方法的值≤0.19),精确召回率曲线下面积(AUC-PR)中位数为0.10(基线方法的值≤0.10)。
PheWP2V可以通过使用医学概念嵌入和对相关既往病史进行加权来有效预测表型。通过利用标记数据和未标记数据,PheWP2V减少了过拟合并改善了对罕见表型的预测,使其成为早期诊断高危疾病的有用筛查工具,不过需要进一步研究来评估嵌入在不同数据库之间的可转移性。
与几种流行的基线方法相比,PheWP2V快速、灵活,并且在MIMIC-III数据库的全表型范围内对许多临床疾病表型具有卓越的预测性能。