Naim Iftekhar, Datta Suprakash, Rebhahn Jonathan, Cavenaugh James S, Mosmann Tim R, Sharma Gaurav
Department of Computer Science, University of Rochester, Rochester, New York.
Cytometry A. 2014 May;85(5):408-21. doi: 10.1002/cyto.a.22446. Epub 2014 Feb 14.
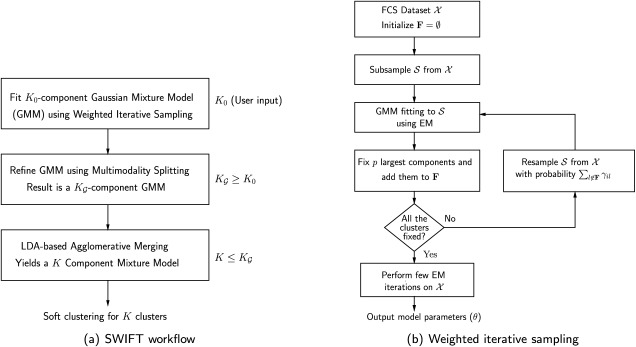
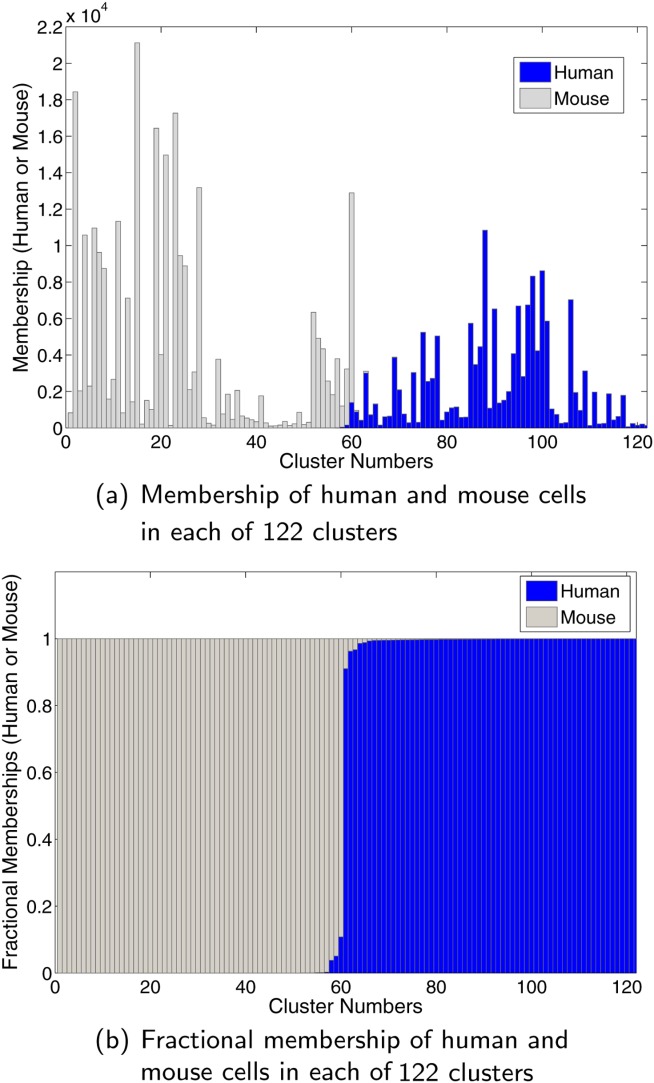
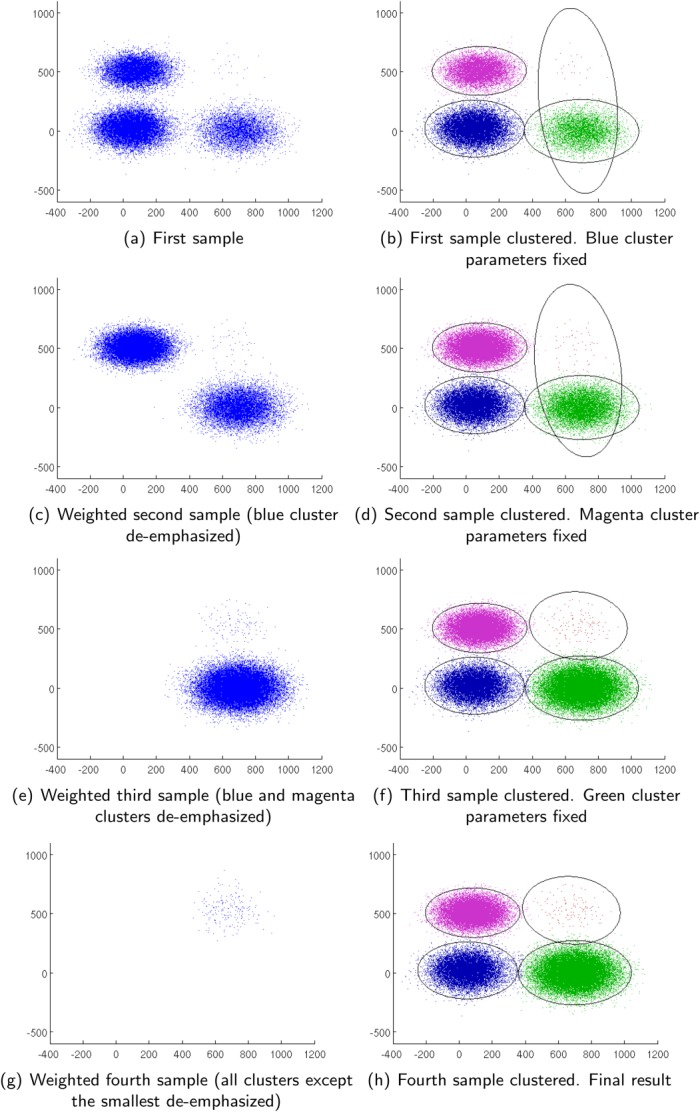
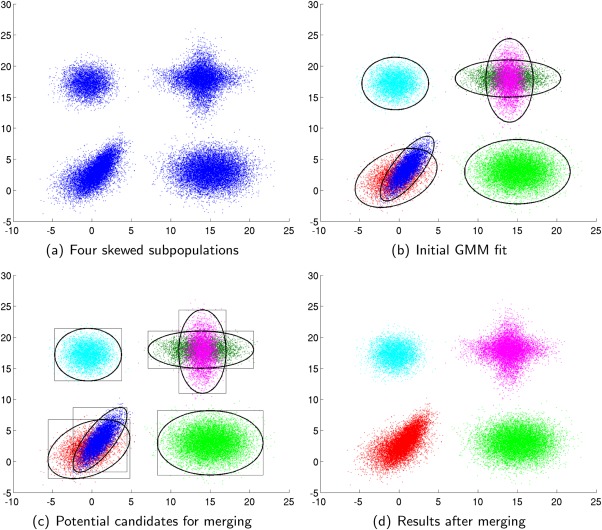
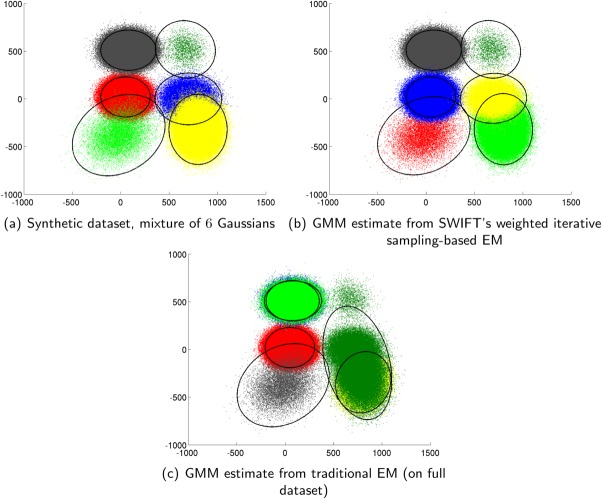
We present a model-based clustering method, SWIFT (Scalable Weighted Iterative Flow-clustering Technique), for digesting high-dimensional large-sized datasets obtained via modern flow cytometry into more compact representations that are well-suited for further automated or manual analysis. Key attributes of the method include the following: (a) the analysis is conducted in the multidimensional space retaining the semantics of the data, (b) an iterative weighted sampling procedure is utilized to maintain modest computational complexity and to retain discrimination of extremely small subpopulations (hundreds of cells from datasets containing tens of millions), and (c) a splitting and merging procedure is incorporated in the algorithm to preserve distinguishability between biologically distinct populations, while still providing a significant compaction relative to the original data. This article presents a detailed algorithmic description of SWIFT, outlining the application-driven motivations for the different design choices, a discussion of computational complexity of the different steps, and results obtained with SWIFT for synthetic data and relatively simple experimental data that allow validation of the desirable attributes. A companion paper (Part 2) highlights the use of SWIFT, in combination with additional computational tools, for more challenging biological problems.
我们提出了一种基于模型的聚类方法——SWIFT(可扩展加权迭代流聚类技术),用于将通过现代流式细胞术获得的高维大型数据集提炼成更紧凑的表示形式,以便于进一步进行自动化或手动分析。该方法的关键特性包括:(a) 在保留数据语义的多维空间中进行分析;(b) 采用迭代加权采样程序,以保持适度的计算复杂度,并保留对极小亚群(来自包含数千万个细胞的数据集的数百个细胞)的区分能力;(c) 算法中纳入了分裂和合并程序,以保持生物学上不同群体之间的可区分性,同时相对于原始数据仍能实现显著的压缩。本文详细介绍了SWIFT的算法描述,概述了不同设计选择的应用驱动动机,讨论了不同步骤的计算复杂度,以及使用SWIFT处理合成数据和相对简单的实验数据所获得的结果,这些数据能够验证该方法的理想特性。一篇配套论文(第2部分)重点介绍了将SWIFT与其他计算工具相结合,用于解决更具挑战性的生物学问题。