Naccache Samia N, Federman Scot, Veeraraghavan Narayanan, Zaharia Matei, Lee Deanna, Samayoa Erik, Bouquet Jerome, Greninger Alexander L, Luk Ka-Cheung, Enge Barryett, Wadford Debra A, Messenger Sharon L, Genrich Gillian L, Pellegrino Kristen, Grard Gilda, Leroy Eric, Schneider Bradley S, Fair Joseph N, Martínez Miguel A, Isa Pavel, Crump John A, DeRisi Joseph L, Sittler Taylor, Hackett John, Miller Steve, Chiu Charles Y
Department of Laboratory Medicine, UCSF, San Francisco, California 94107, USA; UCSF-Abbott Viral Diagnostics and Discovery Center, San Francisco, California 94107, USA;
Department of Computer Science, University of California, Berkeley, California 94720, USA;
Genome Res. 2014 Jul;24(7):1180-92. doi: 10.1101/gr.171934.113. Epub 2014 Jun 4.
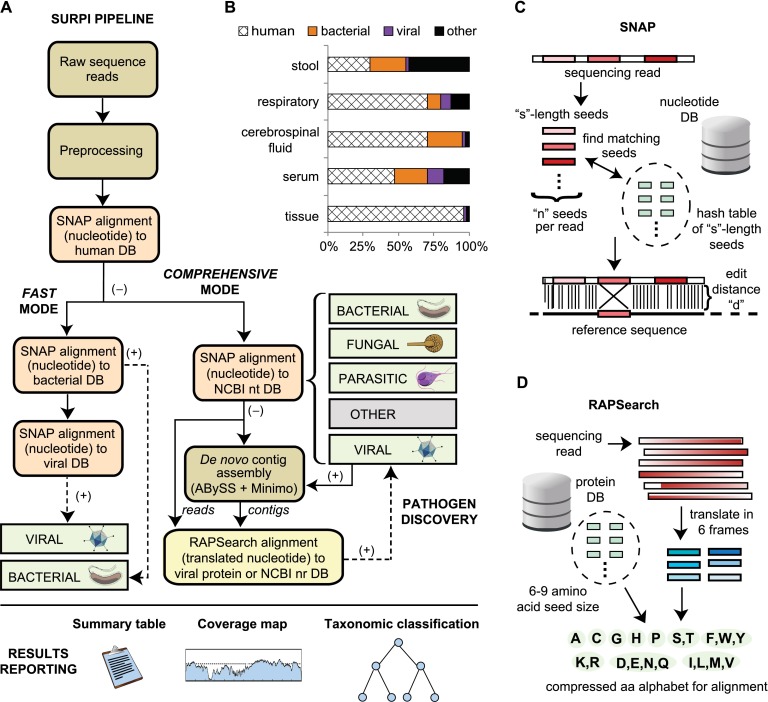
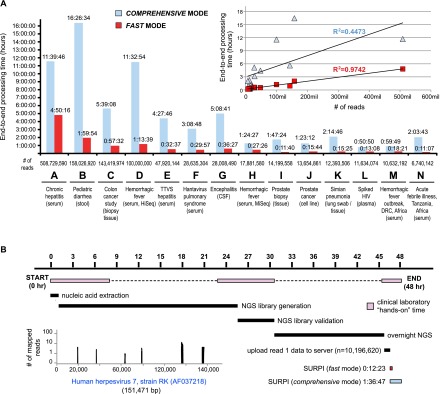
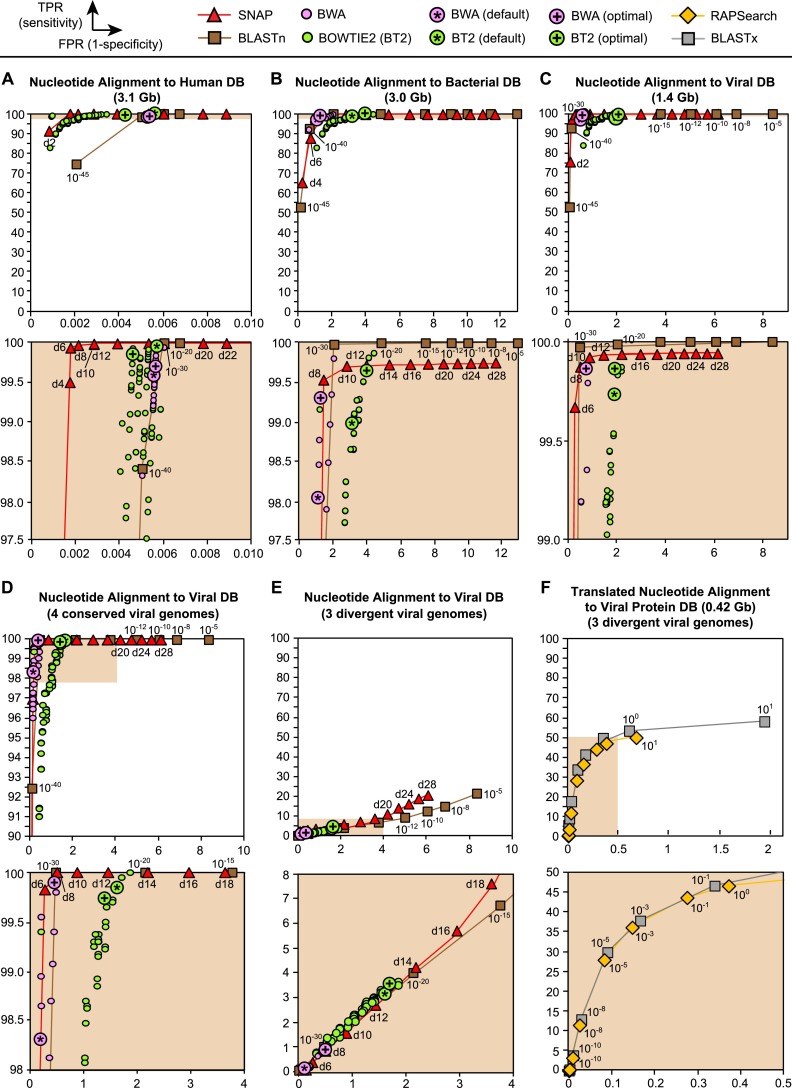
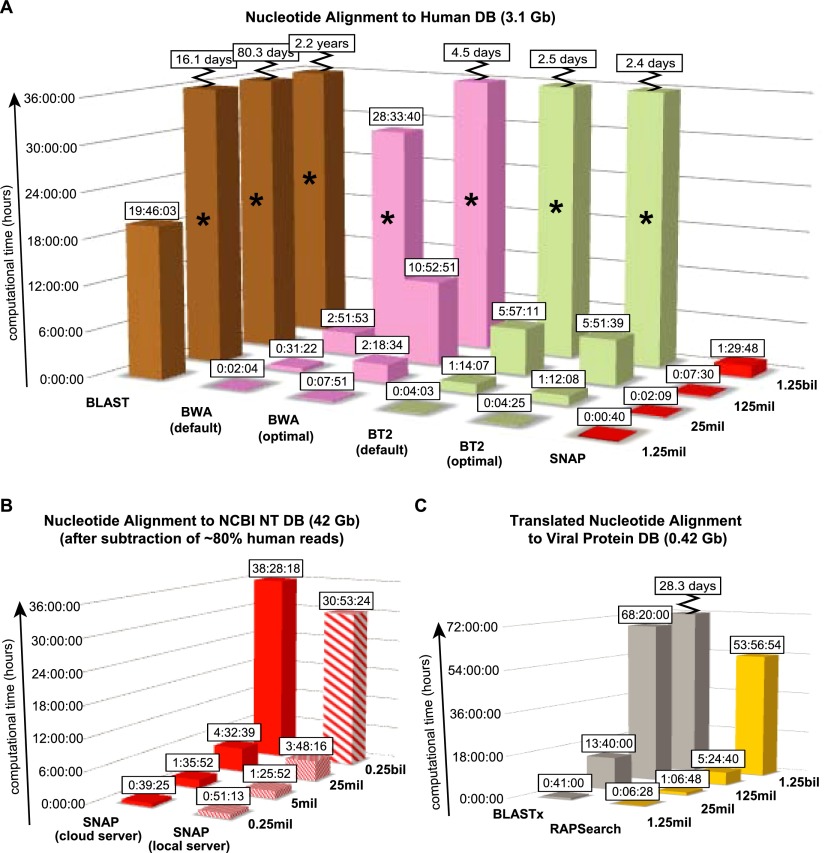
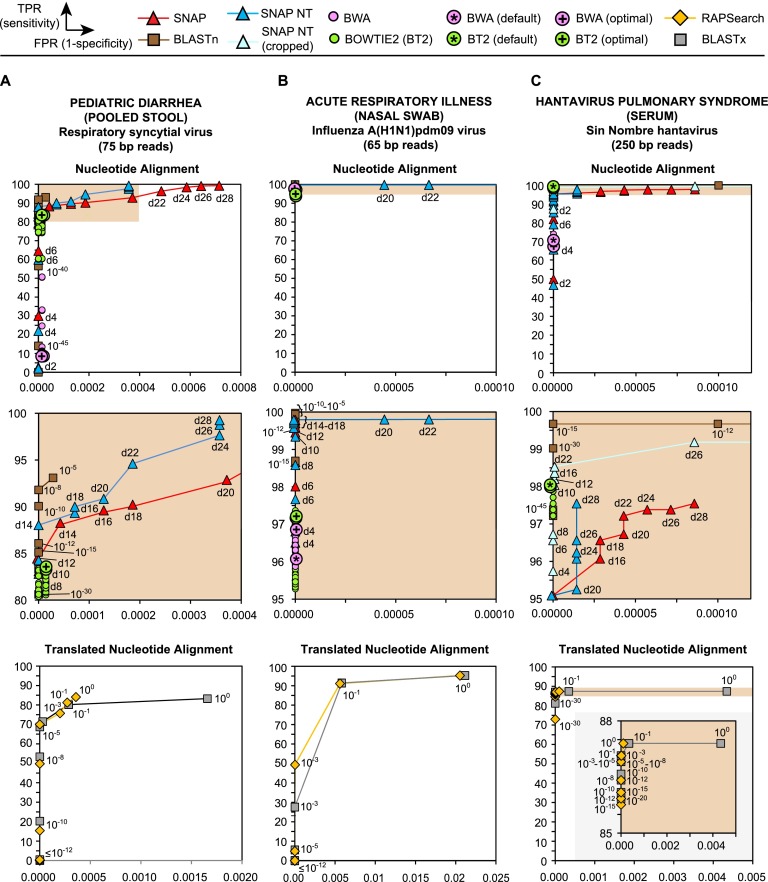
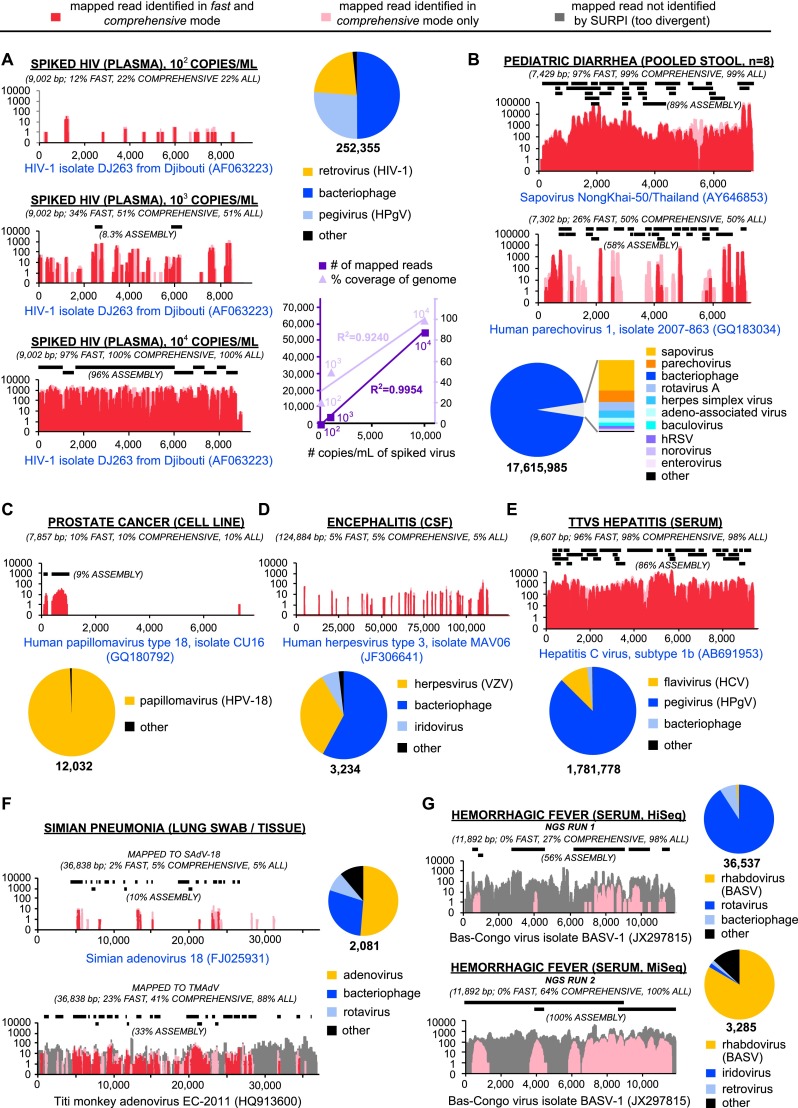
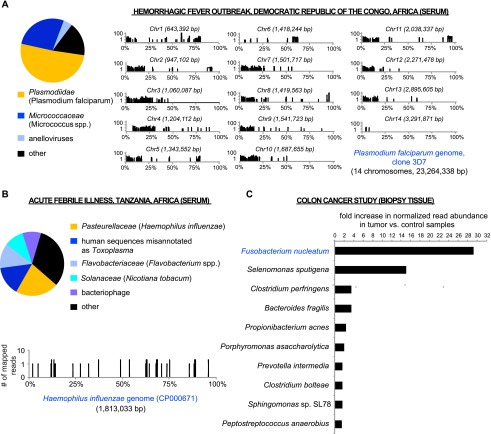
Unbiased next-generation sequencing (NGS) approaches enable comprehensive pathogen detection in the clinical microbiology laboratory and have numerous applications for public health surveillance, outbreak investigation, and the diagnosis of infectious diseases. However, practical deployment of the technology is hindered by the bioinformatics challenge of analyzing results accurately and in a clinically relevant timeframe. Here we describe SURPI ("sequence-based ultrarapid pathogen identification"), a computational pipeline for pathogen identification from complex metagenomic NGS data generated from clinical samples, and demonstrate use of the pipeline in the analysis of 237 clinical samples comprising more than 1.1 billion sequences. Deployable on both cloud-based and standalone servers, SURPI leverages two state-of-the-art aligners for accelerated analyses, SNAP and RAPSearch, which are as accurate as existing bioinformatics tools but orders of magnitude faster in performance. In fast mode, SURPI detects viruses and bacteria by scanning data sets of 7-500 million reads in 11 min to 5 h, while in comprehensive mode, all known microorganisms are identified, followed by de novo assembly and protein homology searches for divergent viruses in 50 min to 16 h. SURPI has also directly contributed to real-time microbial diagnosis in acutely ill patients, underscoring its potential key role in the development of unbiased NGS-based clinical assays in infectious diseases that demand rapid turnaround times.
无偏倚的下一代测序(NGS)方法能够在临床微生物实验室中进行全面的病原体检测,并且在公共卫生监测、疫情调查和传染病诊断方面有众多应用。然而,该技术的实际应用受到在临床相关时间范围内准确分析结果这一生物信息学挑战的阻碍。在此,我们描述了SURPI(“基于序列的超快速病原体鉴定”),这是一种用于从临床样本生成的复杂宏基因组NGS数据中鉴定病原体的计算流程,并展示了该流程在分析包含超过11亿条序列的237份临床样本中的应用。SURPI可部署在基于云的服务器和独立服务器上,它利用两种先进的比对工具进行加速分析,即SNAP和RAPSearch,这两种工具与现有的生物信息学工具一样准确,但性能要快几个数量级。在快速模式下,SURPI通过扫描700万至5亿条 reads 的数据集,在11分钟至5小时内检测病毒和细菌,而在全面模式下,可识别所有已知微生物,随后进行从头组装和针对变异病毒的蛋白质同源性搜索,耗时50分钟至16小时。SURPI还直接助力了对急重症患者的实时微生物诊断,凸显了其在需要快速周转时间的基于NGS的无偏倚传染病临床检测开发中的潜在关键作用。