Eusebi Paolo, Reitsma Johannes B, Vermunt Jeroen K
Department of Epidemiology, Regional Health Authority of Umbria, Via Mario Angeloni, 61, 06124 Perugia, Italy.
BMC Med Res Methodol. 2014 Jul 11;14:88. doi: 10.1186/1471-2288-14-88.
Several types of statistical methods are currently available for the meta-analysis of studies on diagnostic test accuracy. One of these methods is the Bivariate Model which involves a simultaneous analysis of the sensitivity and specificity from a set of studies. In this paper, we review the characteristics of the Bivariate Model and demonstrate how it can be extended with a discrete latent variable. The resulting clustering of studies yields additional insight into the accuracy of the test of interest.
A Latent Class Bivariate Model is proposed. This model captures the between-study variability in sensitivity and specificity by assuming that studies belong to one of a small number of latent classes. This yields both an easier to interpret and a more precise description of the heterogeneity between studies. Latent classes may not only differ with respect to the average sensitivity and specificity, but also with respect to the correlation between sensitivity and specificity.
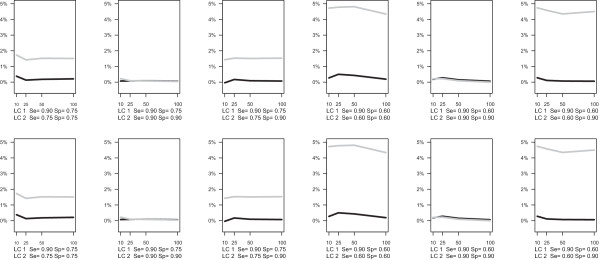
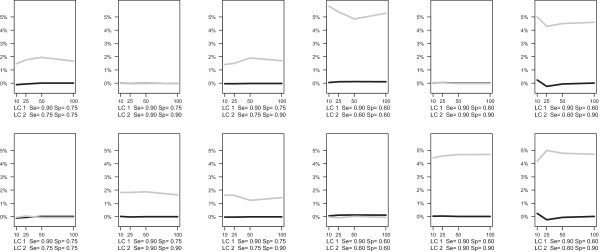
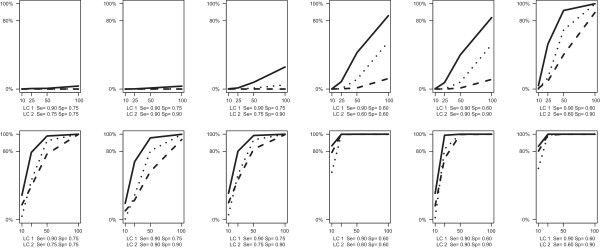
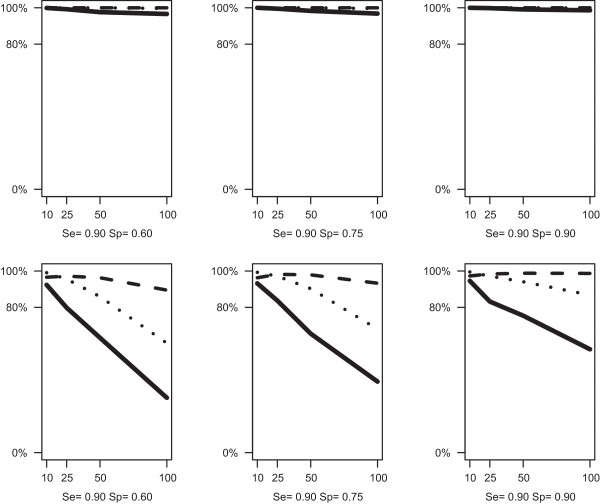
The Latent Class Bivariate Model identifies clusters of studies with their own estimates of sensitivity and specificity. Our simulation study demonstrated excellent parameter recovery and good performance of the model selection statistics typically used in latent class analysis. Application in a real data example on coronary artery disease showed that the inclusion of latent classes yields interesting additional information.
Our proposed new meta-analysis method can lead to a better fit of the data set of interest, less biased estimates and more reliable confidence intervals for sensitivities and specificities. But even more important, it may serve as an exploratory tool for subsequent sub-group meta-analyses.
目前有几种统计方法可用于诊断试验准确性研究的荟萃分析。其中一种方法是双变量模型,它涉及对一组研究的敏感性和特异性进行同时分析。在本文中,我们回顾了双变量模型的特点,并展示了如何用离散潜在变量对其进行扩展。由此产生的研究聚类为感兴趣的试验准确性提供了更多见解。
提出了一种潜在类别双变量模型。该模型通过假设研究属于少数几个潜在类别之一来捕捉研究间敏感性和特异性的变异性。这不仅产生了更易于解释的研究间异质性描述,而且更精确。潜在类别不仅在平均敏感性和特异性方面可能不同,而且在敏感性和特异性之间的相关性方面也可能不同。
潜在类别双变量模型识别出具有自身敏感性和特异性估计值的研究聚类。我们的模拟研究表明,参数恢复良好,潜在类别分析中常用的模型选择统计量表现良好。在冠心病真实数据实例中的应用表明,纳入潜在类别可产生有趣的额外信息。
我们提出的新荟萃分析方法可以使感兴趣的数据集拟合得更好,敏感性和特异性的估计偏差更小,置信区间更可靠。但更重要的是,它可以作为后续亚组荟萃分析的探索工具。