Department of Biochemistry, University of Otago Dunedin, New Zealand ; Department of Mathematics and Statistics, University of Otago Dunedin, New Zealand ; Department of Biochemistry, Virtual Institute of Statistical Genetics, University of Otago Dunedin, New Zealand.
Department of Biochemistry, University of Otago Dunedin, New Zealand ; Department of Biochemistry, Virtual Institute of Statistical Genetics, University of Otago Dunedin, New Zealand.
Front Genet. 2014 Aug 1;5:248. doi: 10.3389/fgene.2014.00248. eCollection 2014.
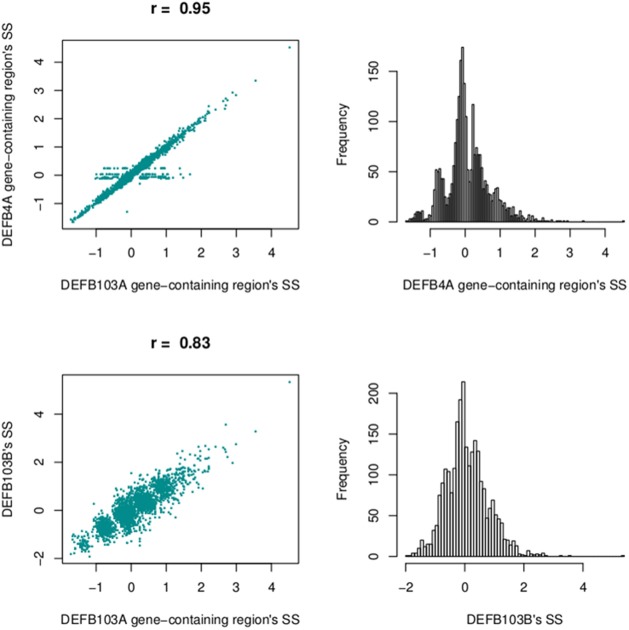
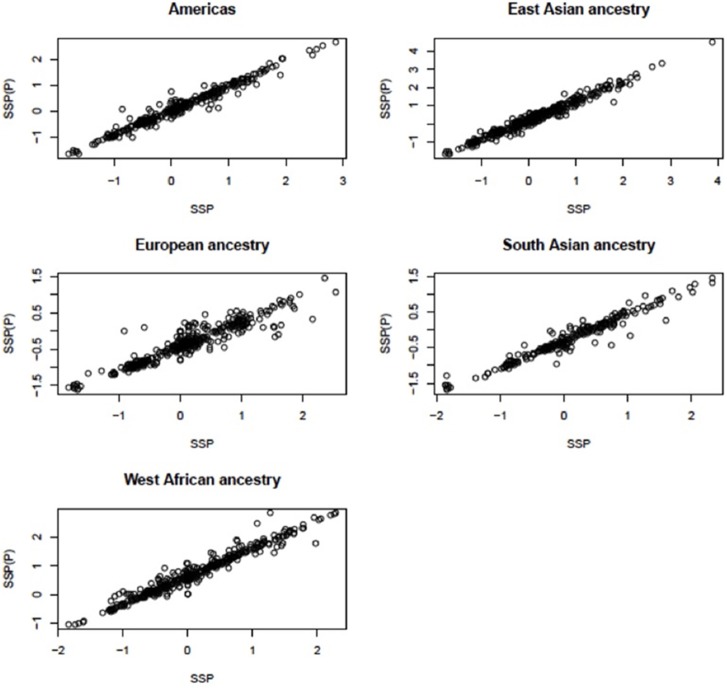
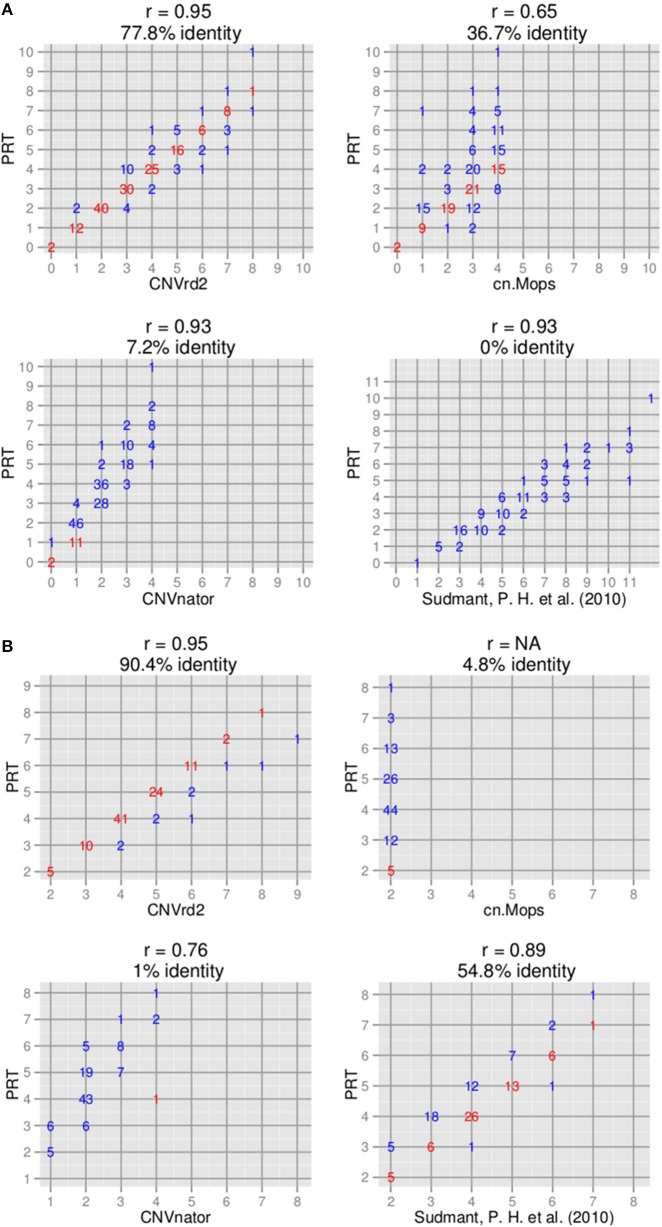
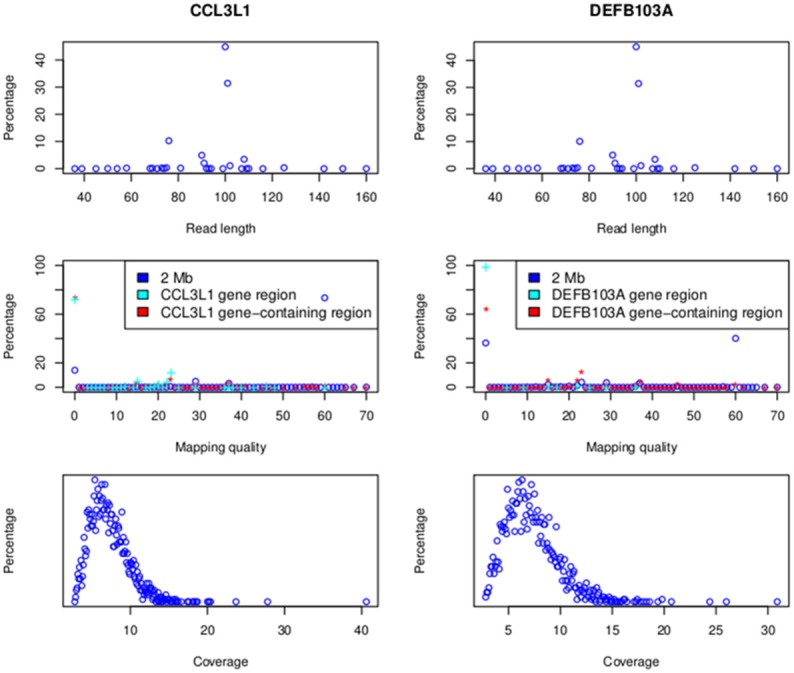
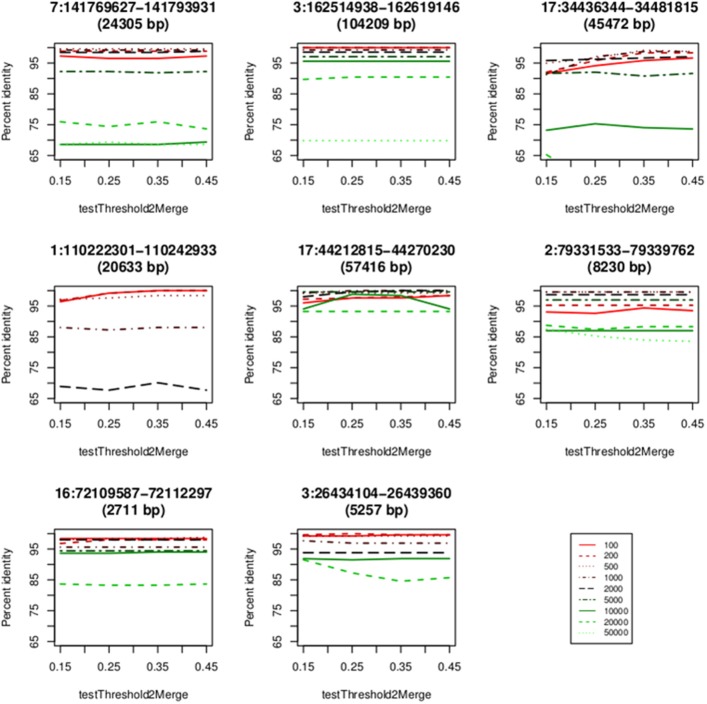
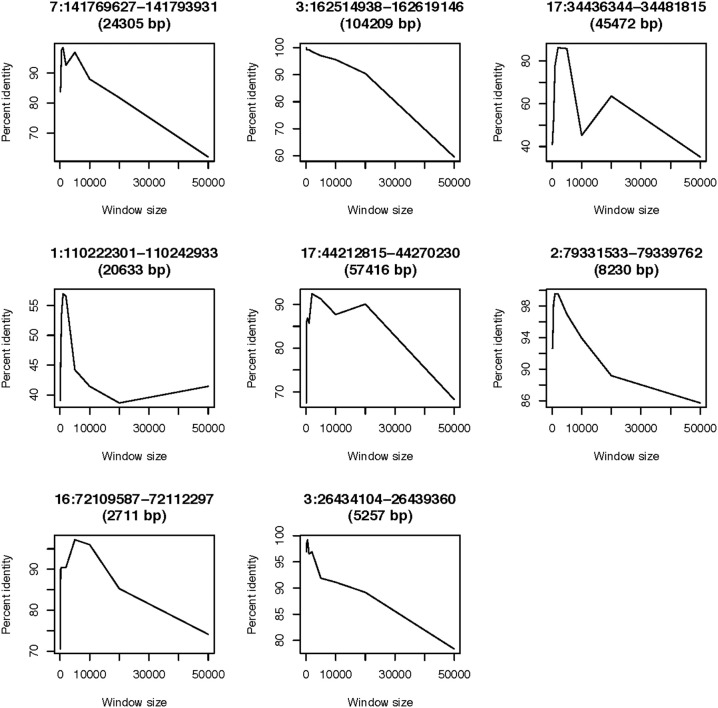
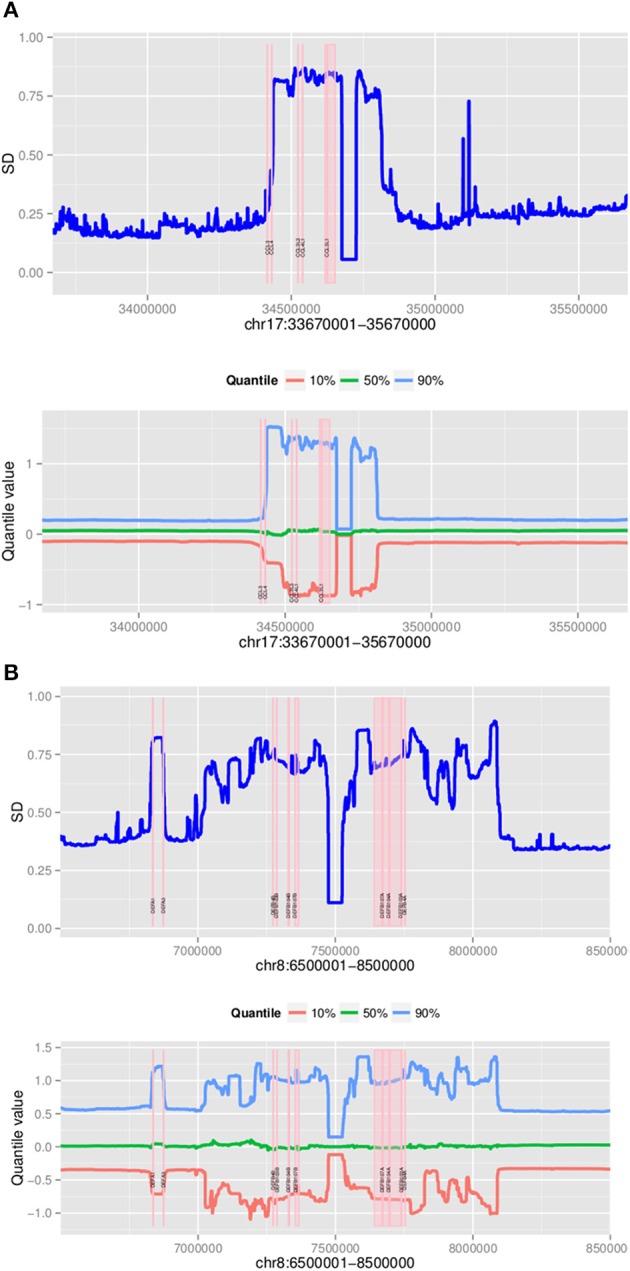
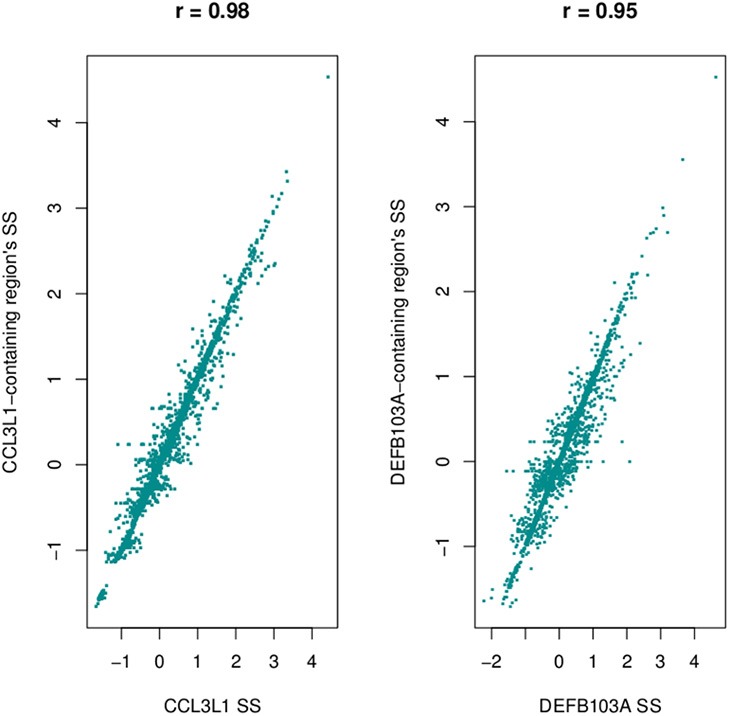
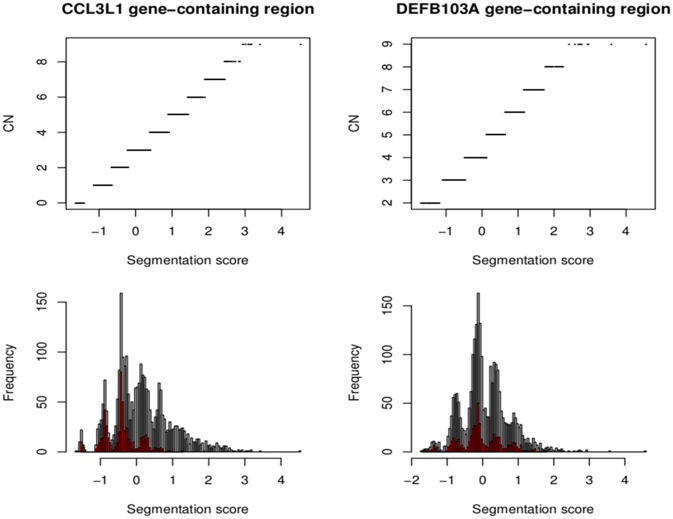
Recent advances in high-throughout sequencing technologies have made it possible to accurately assign copy number (CN) at CN variable loci. However, current analytic methods often perform poorly in regions in which complex CN variation is observed. Here we report the development of a read depth-based approach, CNVrd2, for investigation of CN variation using high-throughput sequencing data. This methodology was developed using data from the 1000 Genomes Project from the CCL3L1 locus, and tested using data from the DEFB103A locus. In both cases, samples were selected for which paralog ratio test data were also available for comparison. The CNVrd2 method first uses observed read-count ratios to refine segmentation results in one population. Then a linear regression model is applied to adjust the results across multiple populations, in combination with a Bayesian normal mixture model to cluster segmentation scores into groups for individual CN counts. The performance of CNVrd2 was compared to that of two other read depth-based methods (CNVnator, cn.mops) at the CCL3L1 and DEFB103A loci. The highest concordance with the paralog ratio test method was observed for CNVrd2 (77.8/90.4% for CNVrd2, 36.7/4.8% for cn.mops and 7.2/1% for CNVnator at CCL3L1 and DEF103A). CNVrd2 is available as an R package as part of the Bioconductor project: http://www.bioconductor.org/packages/release/bioc/html/CNVrd2.html.
高通量测序技术的最新进展使得在拷贝数可变(CNV)位点准确分配拷贝数(CN)成为可能。然而,目前的分析方法在观察到复杂 CN 变异的区域往往表现不佳。在这里,我们报告了一种基于读取深度的方法 CNVrd2 的开发,用于使用高通量测序数据研究 CN 变异。该方法是使用来自 CCL3L1 基因座的 1000 基因组计划的数据开发的,并使用来自 DEFB103A 基因座的数据进行了测试。在这两种情况下,选择了具有可供比较的等位基因比率测试数据的样本。CNVrd2 方法首先使用观察到的读取计数比来细化一个群体中的分割结果。然后,应用线性回归模型来调整多个群体的结果,结合贝叶斯正态混合模型将分割分数聚类成个体 CN 计数的组。在 CCL3L1 和 DEFB103A 基因座上,将 CNVrd2 的性能与另外两种基于读取深度的方法(CNVnator、cn.mops)进行了比较。与等位基因比率测试方法最一致的是 CNVrd2(在 CCL3L1 和 DEF103A 上,CNVrd2 为 77.8/90.4%,cn.mops 为 36.7/4.8%,CNVnator 为 7.2/1%)。CNVrd2 作为 Bioconductor 项目的一部分以 R 包的形式提供:http://www.bioconductor.org/packages/release/bioc/html/CNVrd2.html。