Feng Pengmian, Jiang Ning, Liu Nan
School of Public Health, Hebei United University, Tangshan 063000, China.
ScientificWorldJournal. 2014;2014:740506. doi: 10.1155/2014/740506. Epub 2014 Aug 19.
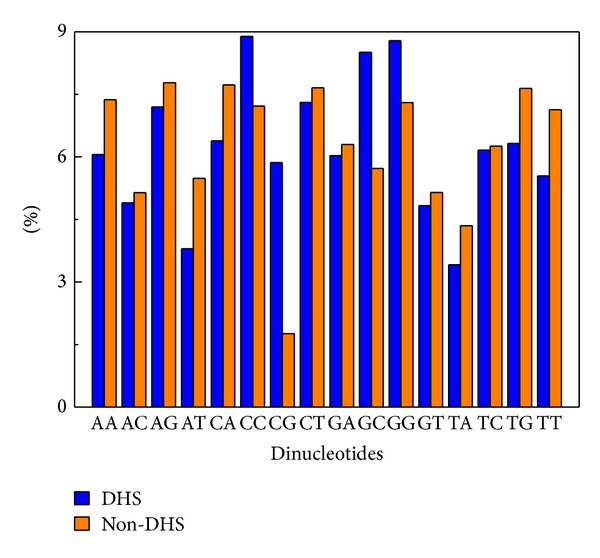
DNase I hypersensitive sites (DHS) associated with a wide variety of regulatory DNA elements. Knowledge about the locations of DHS is helpful for deciphering the function of noncoding genomic regions. With the acceleration of genome sequences in the postgenomic age, it is highly desired to develop cost-effective computational methods to identify DHS. In the present work, a support vector machine based model was proposed to identify DHS by using the pseudo dinucleotide composition. In the jackknife test, the proposed model obtained an accuracy of 83%, which is competitive with that of the existing method. This result suggests that the proposed model may become a useful tool for DHS identifications.
脱氧核糖核酸酶I超敏感位点(DHS)与多种调控性DNA元件相关。了解DHS的位置有助于解读非编码基因组区域的功能。随着后基因组时代基因组测序的加速,迫切需要开发经济高效的计算方法来识别DHS。在当前工作中,提出了一种基于支持向量机的模型,通过使用伪二核苷酸组成来识别DHS。在留一法测试中,所提出的模型获得了83%的准确率,与现有方法具有竞争力。这一结果表明,所提出的模型可能成为识别DHS的有用工具。