School of Life Sciences, Anhui University, Hefei, 230601, Anhui, China.
School of Life Sciences and Biotechnology, Shanghai Jiao Tong University, Shanghai, 200240, China.
BMC Bioinformatics. 2018 Aug 29;19(1):306. doi: 10.1186/s12859-018-2321-0.
Pseudouridylation is the most prevalent type of posttranscriptional modification in various stable RNAs of all organisms, which significantly affects many cellular processes that are regulated by RNA. Thus, accurate identification of pseudouridine (Ψ) sites in RNA will be of great benefit for understanding these cellular processes. Due to the low efficiency and high cost of current available experimental methods, it is highly desirable to develop computational methods for accurately and efficiently detecting Ψ sites in RNA sequences. However, the predictive accuracy of existing computational methods is not satisfactory and still needs improvement.
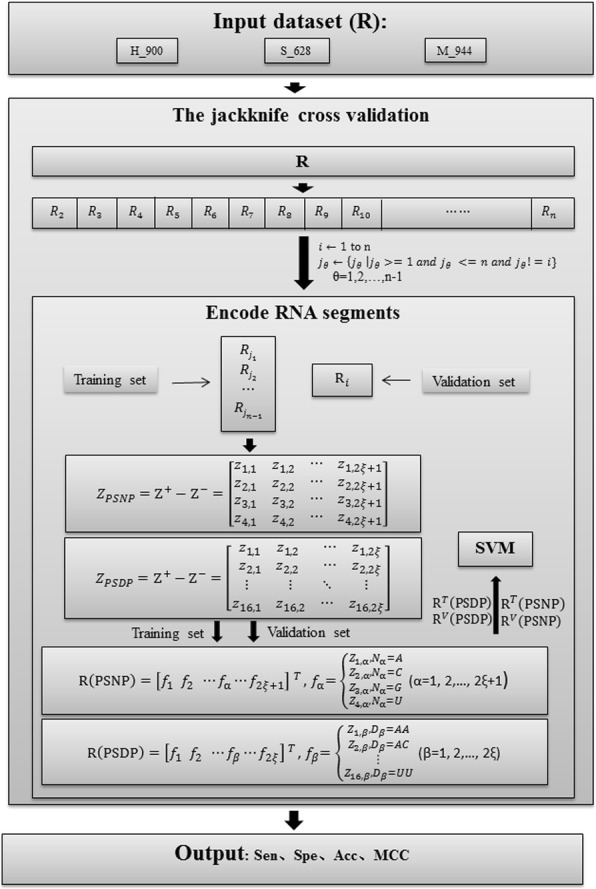
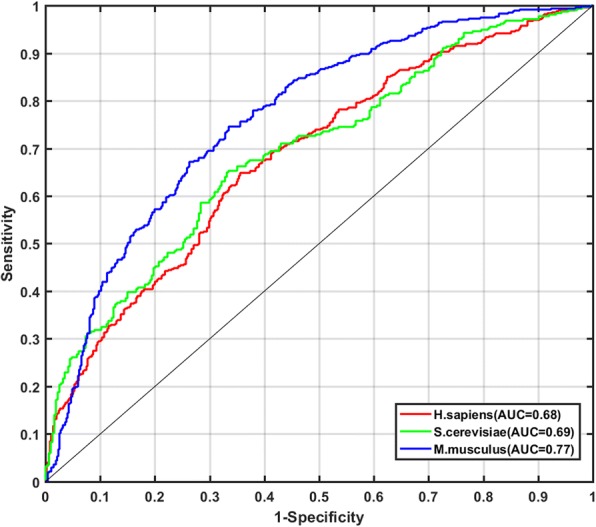
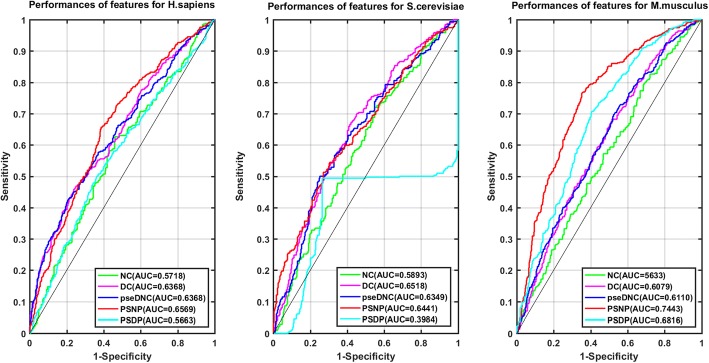
In this study, we developed a new model, PseUI, for Ψ sites identification in three species, which are H. sapiens, S. cerevisiae, and M. musculus. Firstly, five different kinds of features including nucleotide composition (NC), dinucleotide composition (DC), pseudo dinucleotide composition (pseDNC), position-specific nucleotide propensity (PSNP), and position-specific dinucleotide propensity (PSDP) were generated based on RNA segments. Then, a sequential forward feature selection strategy was used to gain an effective feature subset with a compact representation but discriminative prediction power. Based on the selected feature subsets, we built our model by using a support vector machine (SVM). Finally, the generalization of our model was validated by both the jackknife test and independent validation tests on the benchmark datasets. The experimental results showed that our model is more accurate and stable than the previously published models. We have also provided a user-friendly web server for our model at http://zhulab.ahu.edu.cn/PseUI , and a brief instruction for the web server is provided in this paper. By using this instruction, the academic users can conveniently get their desired results without complicated calculations.
In this study, we proposed a new predictor, PseUI, to detect Ψ sites in RNA sequences. It is shown that our model outperformed the existing state-of-art models. It is expected that our model, PseUI, will become a useful tool for accurate identification of RNA Ψ sites.
假尿嘧啶核苷(pseudouridine,Ψ)的修饰是所有生物中各种稳定 RNA 中最普遍的转录后修饰类型,它显著影响许多受 RNA 调控的细胞过程。因此,准确识别 RNA 中的 Ψ 位点将极大地有助于理解这些细胞过程。由于当前可用实验方法的效率低、成本高,因此非常需要开发准确、高效的计算方法来检测 RNA 序列中的 Ψ 位点。然而,现有的计算方法的预测准确性并不令人满意,仍需要改进。
在这项研究中,我们开发了一种新的模型 PseUI,用于鉴定三个物种(人、酵母和小鼠)的 RNA 中的 Ψ 位点。首先,基于 RNA 片段生成了五种不同类型的特征,包括核苷酸组成(NC)、二核苷酸组成(DC)、伪二核苷酸组成(pseDNC)、位置特异性核苷酸倾向(PSNP)和位置特异性二核苷酸倾向(PSDP)。然后,采用顺序前向特征选择策略获得具有紧凑表示但具有区分预测能力的有效特征子集。基于所选特征子集,我们使用支持向量机(SVM)构建了我们的模型。最后,通过 Jackknife 测试和独立验证测试对基准数据集验证了我们模型的泛化能力。实验结果表明,我们的模型比以前发表的模型更准确和稳定。我们还在 http://zhulab.ahu.edu.cn/PseUI 上为我们的模型提供了一个用户友好的网络服务器,并在本文中提供了该网络服务器的简要说明。通过使用此说明,学术用户可以方便地获得他们所需的结果,而无需进行复杂的计算。
在这项研究中,我们提出了一种新的预测器 PseUI,用于检测 RNA 序列中的 Ψ 位点。结果表明,我们的模型优于现有的最先进模型。我们预计,我们的模型 PseUI 将成为准确识别 RNA Ψ 位点的有用工具。