Wan Xiang, Liu Jiming, Cheung William K, Tong Tiejun
Department of Computer Science and Institute of Computational and Theoretical Studies, Hong Kong Baptist University, Kowloon Tong, Hong Kong.
Department of Mathematics, Hong Kong Baptist University, Kowloon Tong, Hong Kong.
BMC Med Inform Decis Mak. 2014 Dec 5;14:111. doi: 10.1186/s12911-014-0111-9.
In a medical data set, data are commonly composed of a minority (positive or abnormal) group and a majority (negative or normal) group and the cost of misclassifying a minority sample as a majority sample is highly expensive. This is the so-called imbalanced classification problem. The traditional classification functions can be seriously affected by the skewed class distribution in the data. To deal with this problem, people often use a priori cost to adjust the learning process in the pursuit of optimal classification function. However, this priori cost is often unknown and hard to estimate in medical decision making.
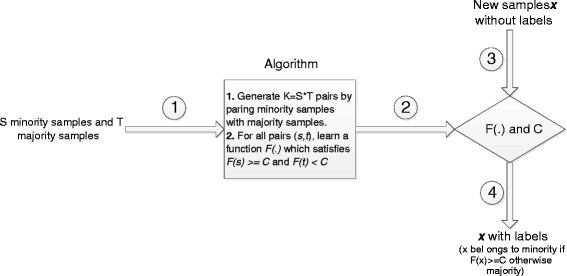
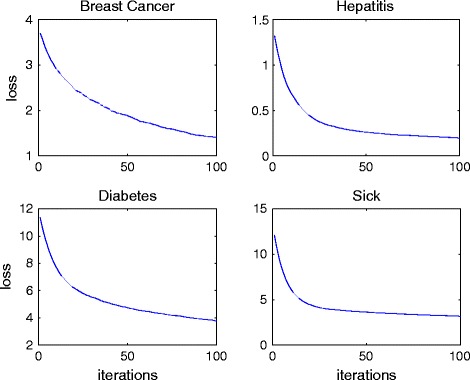
In this paper, we propose a new learning method, named RankCost, to classify imbalanced medical data without using a priori cost. Instead of focusing on improving the class-prediction accuracy, RankCost is to maximize the difference between the minority class and the majority class by using a scoring function, which translates the imbalanced classification problem into a partial ranking problem. The scoring function is learned via a non-parametric boosting algorithm.
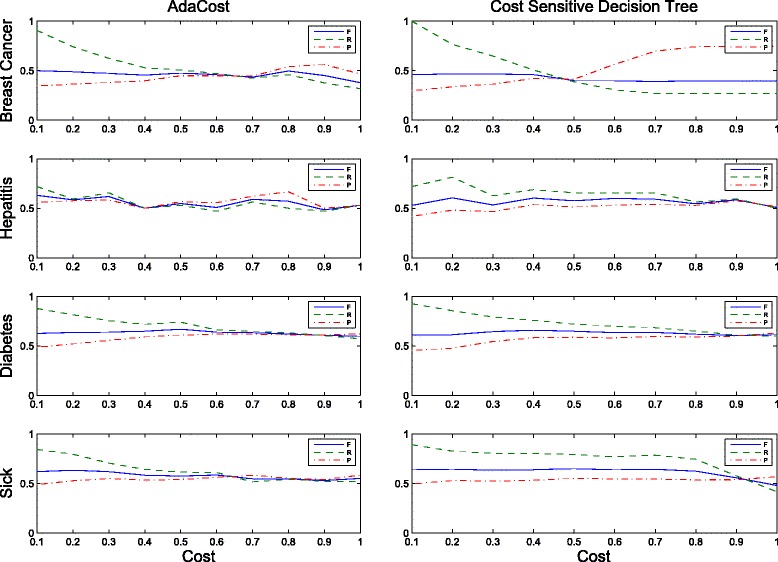
We compare RankCost to several representative approaches on four medical data sets varying in size, imbalanced ratio, and dimension. The experimental results demonstrate that unlike the currently available methods that often perform unevenly with different priori costs, RankCost shows comparable performance in a consistent manner.
It is a challenging task to learn an effective classification model based on imbalanced data in medical data analysis. The traditional approaches often use a priori cost to adjust the learning of the classification function. This work presents a novel approach, namely RankCost, for learning from medical imbalanced data sets without using a priori cost. The experimental results indicate that RankCost performs very well in imbalanced data classification and can be a useful method in real-world applications of medical decision making.
在医学数据集中,数据通常由少数(阳性或异常)组和多数(阴性或正常)组组成,将少数样本误分类为多数样本的代价非常高昂。这就是所谓的不平衡分类问题。传统的分类函数会受到数据中倾斜的类分布的严重影响。为了解决这个问题,人们通常使用先验代价来调整学习过程以追求最优分类函数。然而,在医学决策中,这种先验代价往往未知且难以估计。
在本文中,我们提出了一种名为RankCost的新学习方法,用于在不使用先验代价的情况下对不平衡医学数据进行分类。RankCost不是专注于提高类预测准确率,而是通过使用评分函数来最大化少数类和多数类之间的差异,该评分函数将不平衡分类问题转化为部分排序问题。评分函数通过非参数提升算法进行学习。
我们在四个大小、不平衡率和维度各异的医学数据集上,将RankCost与几种代表性方法进行了比较。实验结果表明,与目前可用的方法不同,后者在不同先验代价下表现往往参差不齐,而RankCost以一致的方式展现出可比的性能。
在医学数据分析中,基于不平衡数据学习有效的分类模型是一项具有挑战性的任务。传统方法通常使用先验代价来调整分类函数的学习。这项工作提出了一种新颖的方法,即RankCost,用于从不使用先验代价的医学不平衡数据集中进行学习。实验结果表明,RankCost在不平衡数据分类中表现出色,并且可以成为医学决策实际应用中的一种有用方法。