School of Computer, Wuhan University, Wuhan 430072, China.
School of Public Health, Wuhan University, Wuhan 430072, China.
J Cheminform. 2015 Jan 19;7(Suppl 1 Text mining for chemistry and the CHEMDNER track):S4. doi: 10.1186/1758-2946-7-S1-S4. eCollection 2015.
The chemical compound and drug name recognition plays an important role in chemical text mining, and it is the basis for automatic relation extraction and event identification in chemical information processing. So a high-performance named entity recognition system for chemical compound and drug names is necessary.
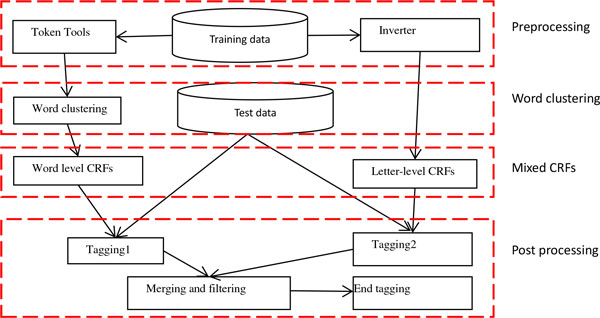
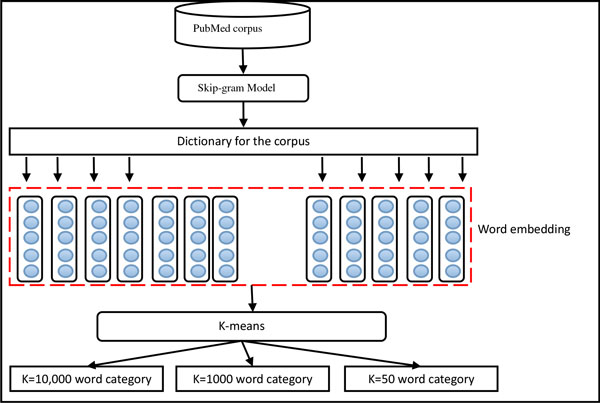
We developed a CHEMDNER system based on mixed conditional random fields (CRF) with word clustering for chemical compound and drug name recognition. For the word clustering, we used Brown's hierarchical algorithm and Skip-gram model based on deep learning with massive PubMed articles including titles and abstracts.
This system achieved the highest F-score of 88.20% for the CDI task and the second highest F-score of 87.11% for the CEM task in BioCreative IV. The performance was further improved by multi-scale clustering based on deep learning, achieving the F-score of 88.71% for CDI and 88.06% for CEM.
The mixed CRF model represents both the internal complexity and external contexts of the entities, and the model is integrated with word clustering to capture domain knowledge with PubMed articles including titles and abstracts. The domain knowledge helps to ensure the performance of the entity recognition, even without fine-grained linguistic features and manually designed rules.
化合物和药物名称识别在化学文本挖掘中起着重要作用,是化学信息处理中自动关系抽取和事件识别的基础。因此,需要开发一种高性能的化合物和药物名称命名实体识别系统。
我们开发了一个基于混合条件随机场(CRF)和单词聚类的 CHEMDNER 系统,用于识别化合物和药物名称。对于单词聚类,我们使用了 Brown 的层次算法和基于深度学习的 Skip-gram 模型,利用包含标题和摘要的大量 PubMed 文章。
在 BioCreative IV 中,该系统在 CDI 任务中获得了 88.20%的最高 F1 分数,在 CEM 任务中获得了 87.11%的第二高 F1 分数。通过基于深度学习的多尺度聚类进一步提高了性能,在 CDI 任务中获得了 88.71%的 F1 分数,在 CEM 任务中获得了 88.06%的 F1 分数。
混合 CRF 模型既表示实体的内部复杂性,又表示外部上下文,该模型与单词聚类相结合,利用包含标题和摘要的 PubMed 文章来捕获领域知识。领域知识有助于确保实体识别的性能,即使没有细粒度的语言特征和手动设计的规则。