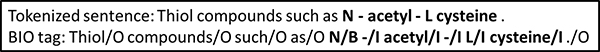Department of Computer Science, Harbin Institute of Technology Shenzhen Guraduate, Shenzhen, Guangdong, China ; School of Biomedical Informatics, The University of Texas Health Science Center at Houston, Houston, Texas, USA.
Department of Pharmacy, the First Affiliated Hospital, Harbin Medical University Harbin, Heilongjiang, China.
J Cheminform. 2015 Jan 19;7(Suppl 1 Text mining for chemistry and the CHEMDNER track):S8. doi: 10.1186/1758-2946-7-S1-S8. eCollection 2015.
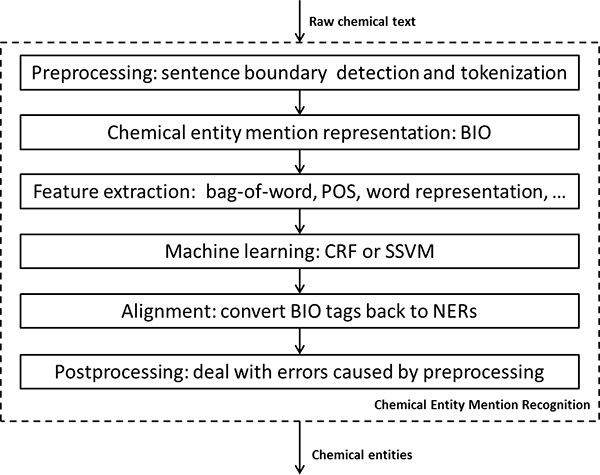
Chemical compounds and drugs (together called chemical entities) embedded in scientific articles are crucial for many information extraction tasks in the biomedical domain. However, only a very limited number of chemical entity recognition systems are publically available, probably due to the lack of large manually annotated corpora. To accelerate the development of chemical entity recognition systems, the Spanish National Cancer Research Center (CNIO) and The University of Navarra organized a challenge on Chemical and Drug Named Entity Recognition (CHEMDNER). The CHEMDNER challenge contains two individual subtasks: 1) Chemical Entity Mention recognition (CEM); and 2) Chemical Document Indexing (CDI). Our study proposes machine learning-based systems for the CEM task.
The 2013 CHEMDNER challenge organizers provided a manually annotated 10,000 UTF8-encoded PubMed abstracts according to a predefined annotation guideline: a training set of 3,500 abstracts, a development set of 3,500 abstracts and a test set of 3,000 abstracts. We developed machine learning-based systems, based on conditional random fields (CRF) and structured support vector machines (SSVM) respectively, for the CEM task for this data set. The effects of three types of word representation (WR) features, generated by Brown clustering, random indexing and skip-gram, on both two machine learning-based systems were also investigated. The performance of our system was evaluated on the test set using scripts provided by the CHEMDNER challenge organizers. Primary evaluation measures were micro Precision, Recall, and F-measure.
Our best system was among the top ranked systems with an official micro F-measure of 85.05%. Fixing a bug caused by inconsistent features marginally improved the performance (micro F-measure of 85.20%) of the system.
The SSVM-based CEM systems outperformed the CRF-based CEM systems when using the same features. Each type of the WR feature was beneficial to the CEM task. Both the CRF-based and SSVM-based systems using the all three types of WR features showed better performance than the systems using only one type of the WR feature.
科学文献中嵌入的化学化合物和药物(统称为化学实体)对于生物医学领域的许多信息提取任务至关重要。然而,只有非常有限数量的化学实体识别系统是公开可用的,这可能是由于缺乏大型手动标注语料库。为了加速化学实体识别系统的发展,西班牙国家癌症研究中心(CNIO)和纳瓦拉大学组织了一次化学和药物命名实体识别(CHEMDNER)挑战赛。CHEMDNER 挑战赛包含两个独立的子任务:1)化学实体提及识别(CEM);2)化学文献索引(CDI)。我们的研究提出了基于机器学习的 CEM 任务系统。
2013 年 CHEMDNER 挑战赛组织者根据预定义的标注指南提供了 10000 个手动标注的 UTF8 编码 PubMed 摘要:一个 3500 个摘要的训练集、一个 3500 个摘要的开发集和一个 3000 个摘要的测试集。我们为这个数据集开发了基于条件随机场(CRF)和结构化支持向量机(SSVM)的基于机器学习的系统,用于 CEM 任务。还研究了三种词表示(WR)特征对这两个基于机器学习的系统的影响,这三种 WR 特征分别由 Brown 聚类、随机索引和 skip-gram 生成。使用 CHEMDNER 挑战赛组织者提供的脚本在测试集上评估了我们系统的性能。主要评估指标是微观精度、召回率和 F1 分数。
我们的最佳系统在排名靠前的系统中排名较高,官方的微观 F1 分数为 85.05%。修复一个由特征不一致引起的错误略微提高了系统的性能(微观 F1 分数为 85.20%)。
当使用相同的特征时,基于 SSVM 的 CEM 系统优于基于 CRF 的 CEM 系统。每种 WR 特征类型都对 CEM 任务有益。使用所有三种 WR 特征的 CRF 基于和 SSVM 基于系统的性能均优于仅使用一种 WR 特征的系统。