Information Technology Supporting Center, Institute of Scientific and Technical Information of China, No. 15 Fuxing Rd., Haidian District, 100038 Beijing, PR China.
School of Economics and Management, Beijing Forestry University, No. 35 Qinghua East Rd., Haidian District, 100083 Beijing, PR China.
J Cheminform. 2015 Jan 19;7(Suppl 1 Text mining for chemistry and the CHEMDNER track):S11. doi: 10.1186/1758-2946-7-S1-S11. eCollection 2015.
In order to improve information access on chemical compounds and drugs (chemical entities) described in text repositories, it is very crucial to be able to identify chemical entity mentions (CEMs) automatically within text. The CHEMDNER challenge in BioCreative IV was specially designed to promote the implementation of corresponding systems that are able to detect mentions of chemical compounds and drugs, which has two subtasks: CDI (Chemical Document Indexing) and CEM.
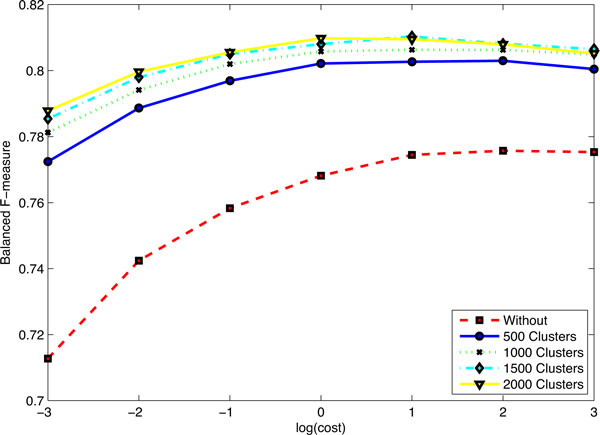
Our system processing pipeline consists of three major components: pre-processing (sentence detection, tokenization), recognition (CRF-based approach), and post-processing (rule-based approach and format conversion). In our post-challenge system, the cost parameter in CRF model was optimized by 10-fold cross validation with grid search, and word representations feature induced by Brown clustering method was introduced. For the CEM subtask, our official runs were ranked in top position by obtaining maximum 88.79% precision, 69.08% recall and 77.70% balanced F-measure, which were improved further to 88.43% precision, 76.48% recall and 82.02% balanced F-measure in our post-challenge system.
In our system, instead of extracting a CEM as a whole, we regarded it as a sequence labeling problem. Though our current system has much room for improvement, our system is valuable in showing that the performance in term of balanced F-measure can be improved largely by utilizing large amounts of relatively inexpensive un-annotated PubMed abstracts and optimizing the cost parameter in CRF model. From our practice and lessons, if one directly utilizes some open-source natural language processing (NLP) toolkits, such as OpenNLP, Standford CoreNLP, false positive (FP) rate may be very high. It is better to develop some additional rules to minimize the FP rate if one does not want to re-train the related models. Our CEM recognition system is available at: http://www.SciTeMiner.org/XuShuo/Demo/CEM.
为了提高文本知识库中描述的化合物和药物(化学实体)的信息获取能力,能够自动识别文本中的化学实体提及(CEM)是非常关键的。BioCreative IV 中的 CHEMDNER 挑战赛专门旨在促进实施能够检测化合物和药物提及的相应系统,该挑战赛有两个子任务:化学文档索引(CDI)和 CEM。
我们的系统处理流程由三个主要组件组成:预处理(句子检测、标记化)、识别(基于条件随机场的方法)和后处理(基于规则的方法和格式转换)。在我们的赛后系统中,通过 10 倍交叉验证和网格搜索优化了 CRF 模型中的成本参数,并引入了由 Brown 聚类方法诱导的词表示特征。对于 CEM 子任务,我们的官方运行在获得最大 88.79%精度、69.08%召回率和 77.70%平衡 F 度量的排名中处于领先地位,在我们的赛后系统中进一步提高到 88.43%精度、76.48%召回率和 82.02%平衡 F 度量。
在我们的系统中,我们不是将 CEM 作为一个整体提取,而是将其视为序列标记问题。尽管我们当前的系统还有很大的改进空间,但我们的系统在利用大量相对廉价的未注释 PubMed 摘要并优化 CRF 模型中的成本参数方面,在平衡 F 度量方面的性能有了很大的提高。从我们的实践和经验中可以看出,如果直接利用一些开源的自然语言处理(NLP)工具包,如 OpenNLP、Standford CoreNLP,假阳性(FP)率可能会非常高。如果不想重新训练相关模型,最好开发一些额外的规则来最小化 FP 率。我们的 CEM 识别系统可在以下网址获取:http://www.SciTeMiner.org/XuShuo/Demo/CEM。