Kanda Kojun, Pflug James M, Sproul John S, Dasenko Mark A, Maddison David R
Department of Integrative Biology, Oregon State University, Corvallis, Oregon, United States of America.
Center for Genome Research and Biocomputing, Oregon State University, Corvallis, Oregon, United States of America.
PLoS One. 2015 Dec 30;10(12):e0143929. doi: 10.1371/journal.pone.0143929. eCollection 2015.
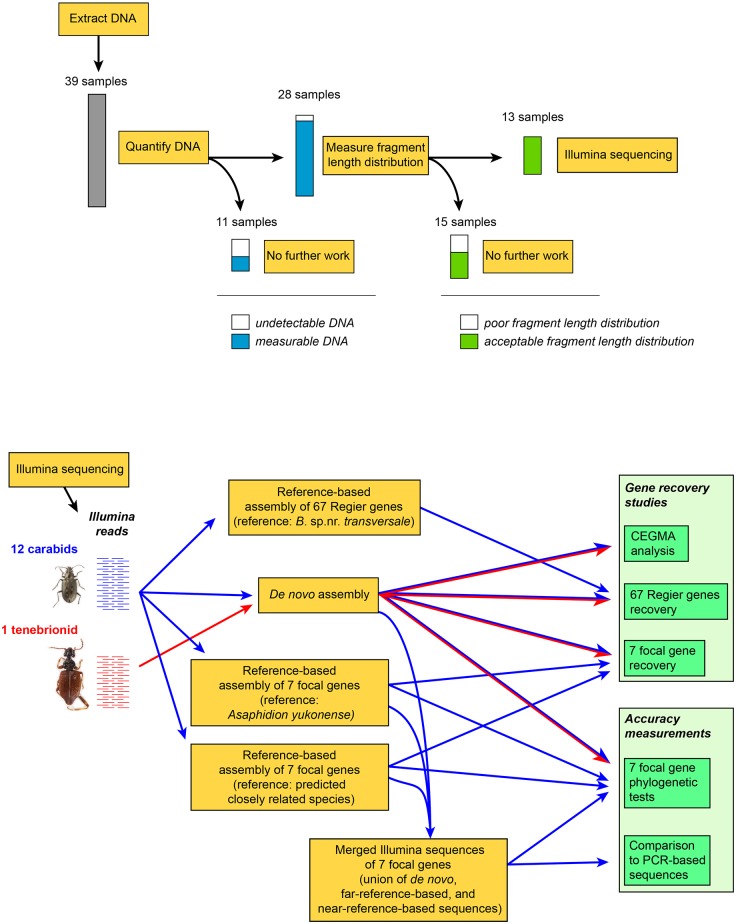
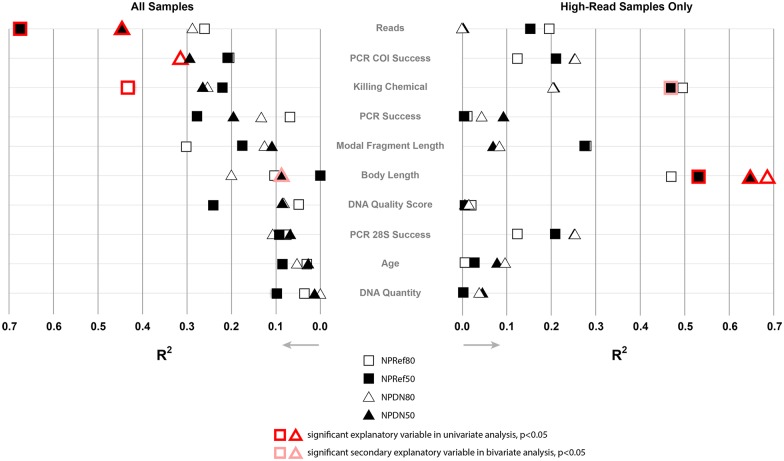
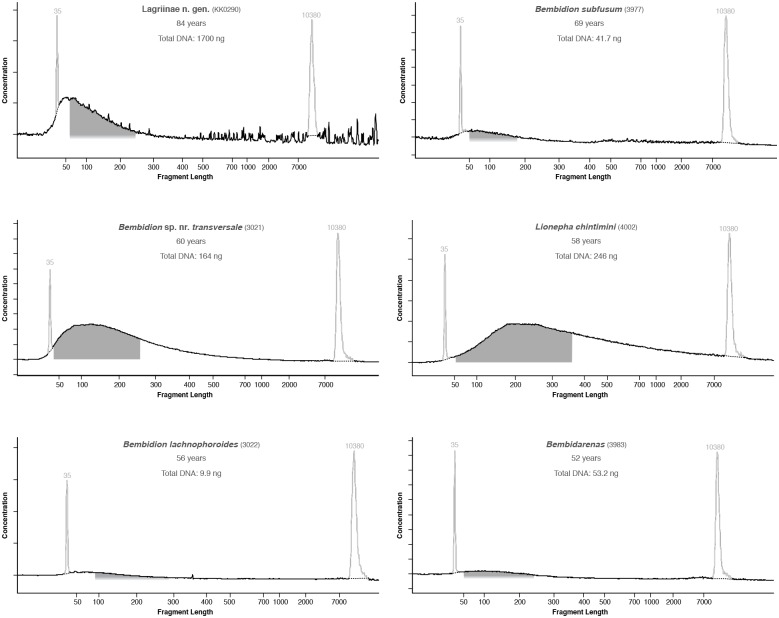
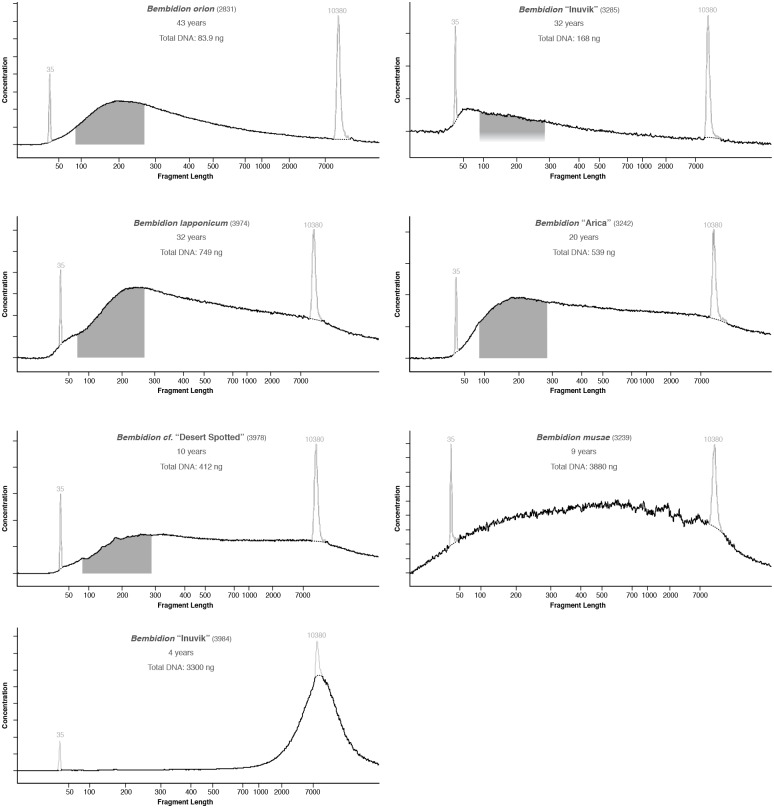
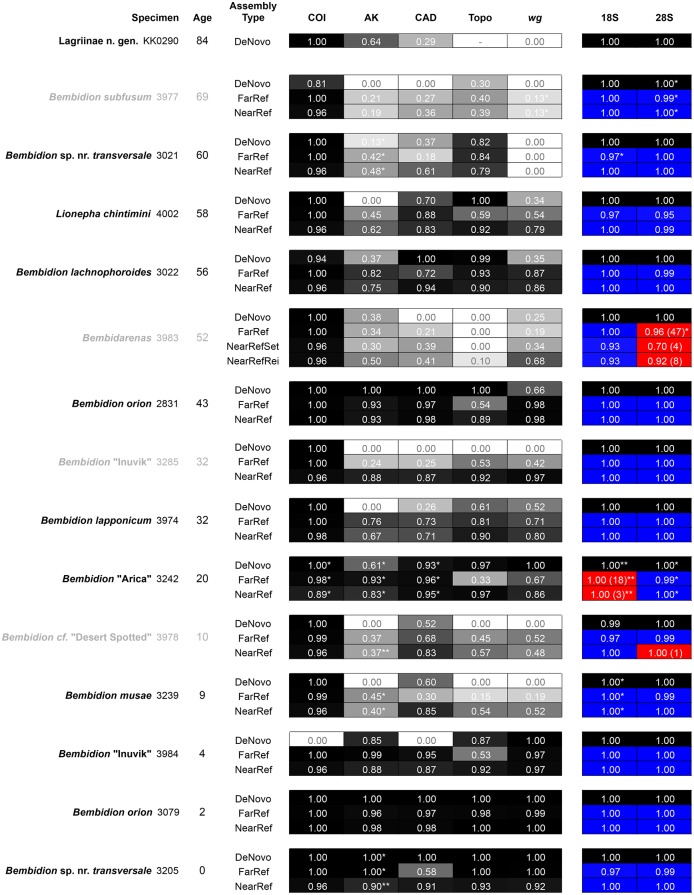
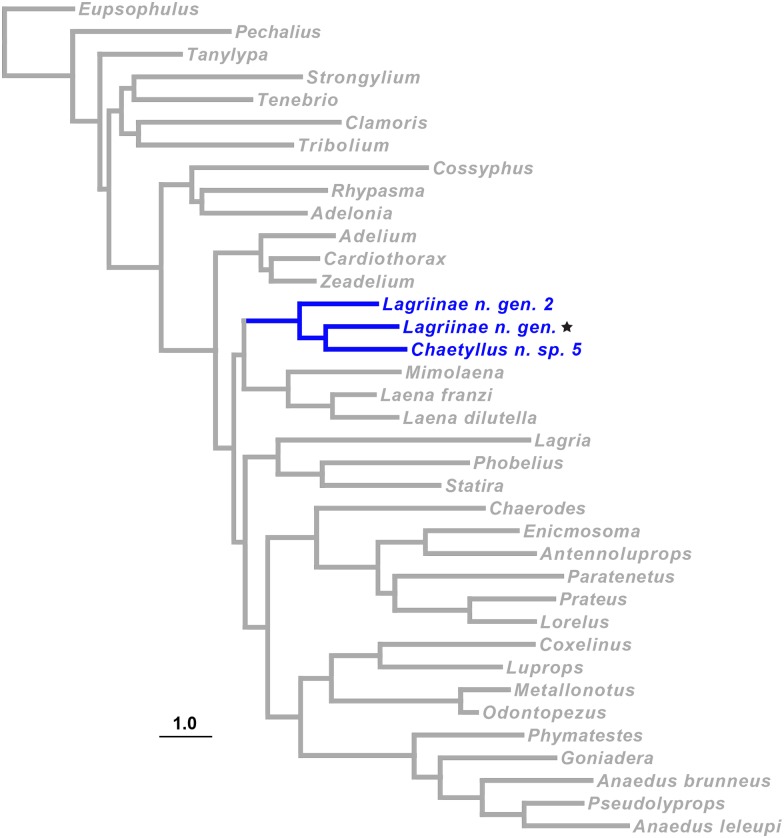
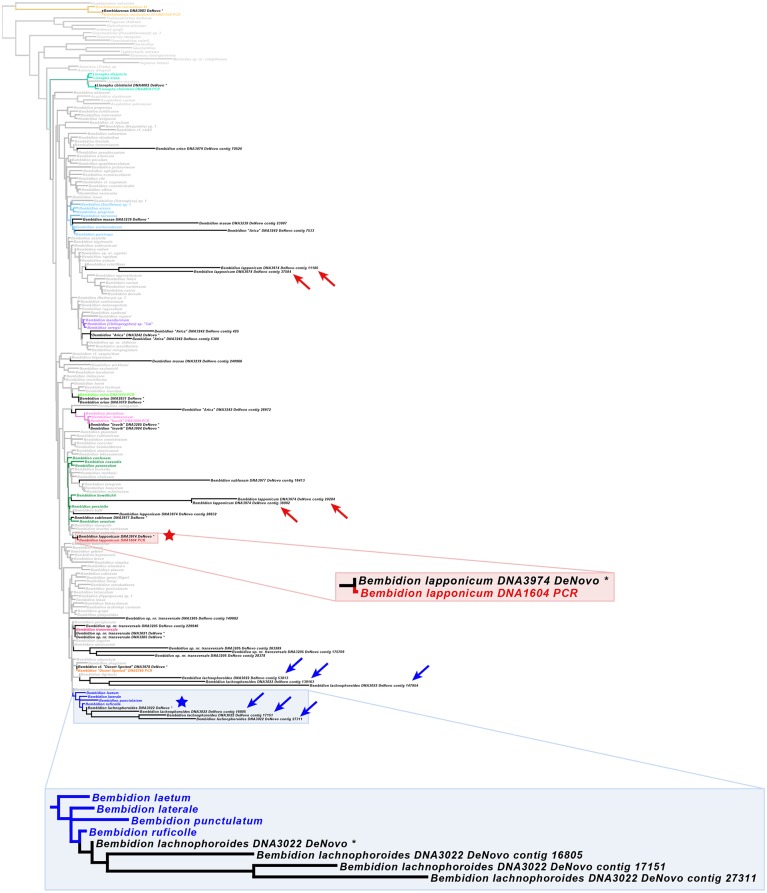
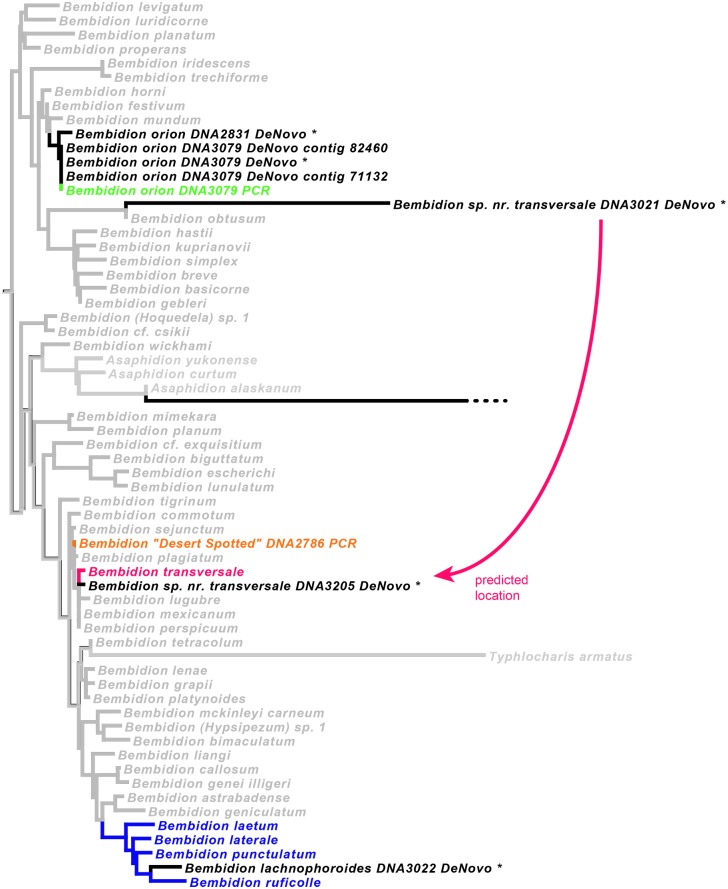
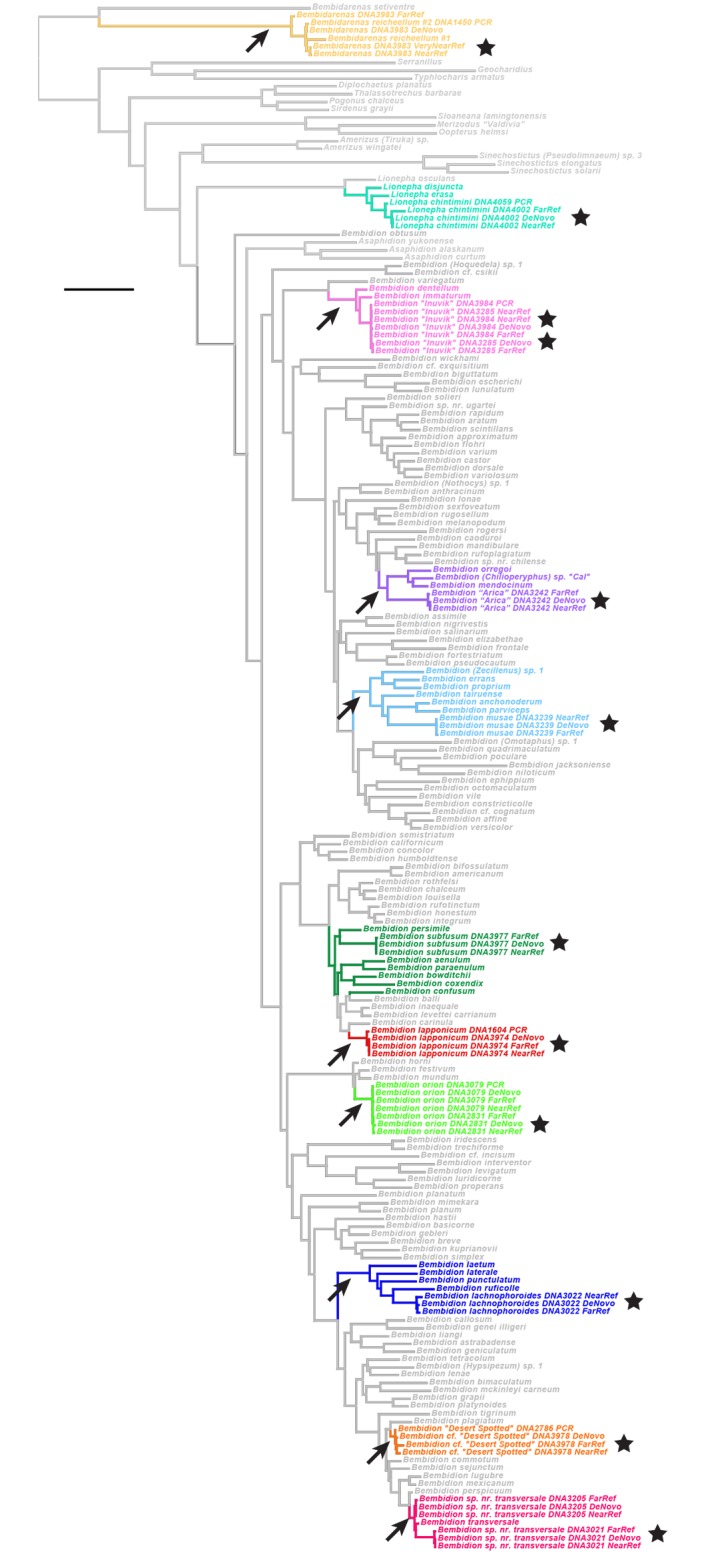
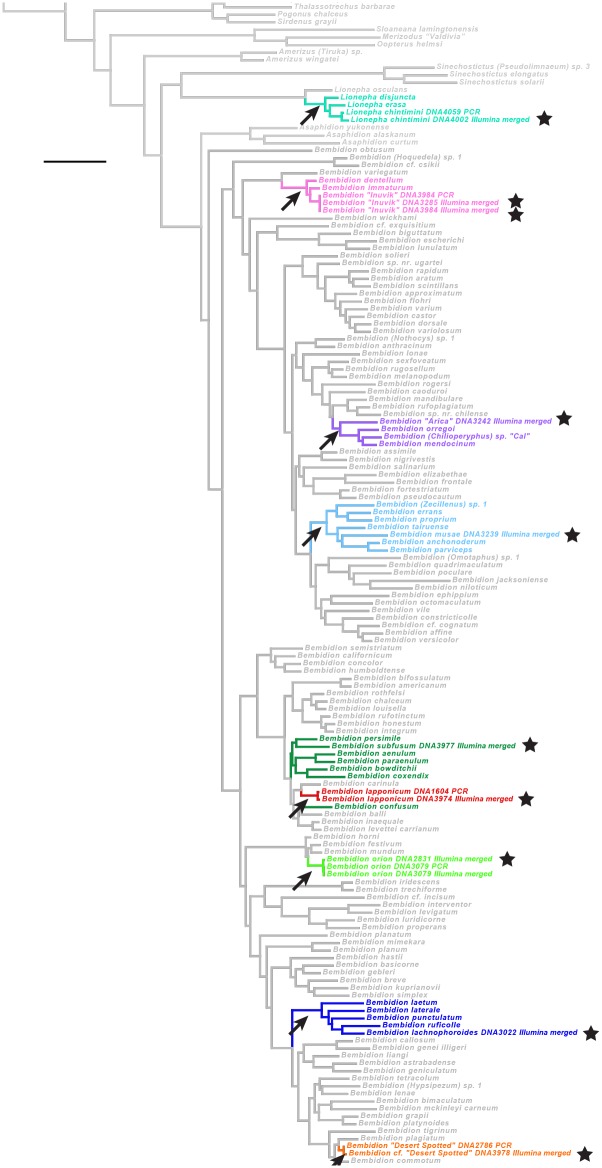
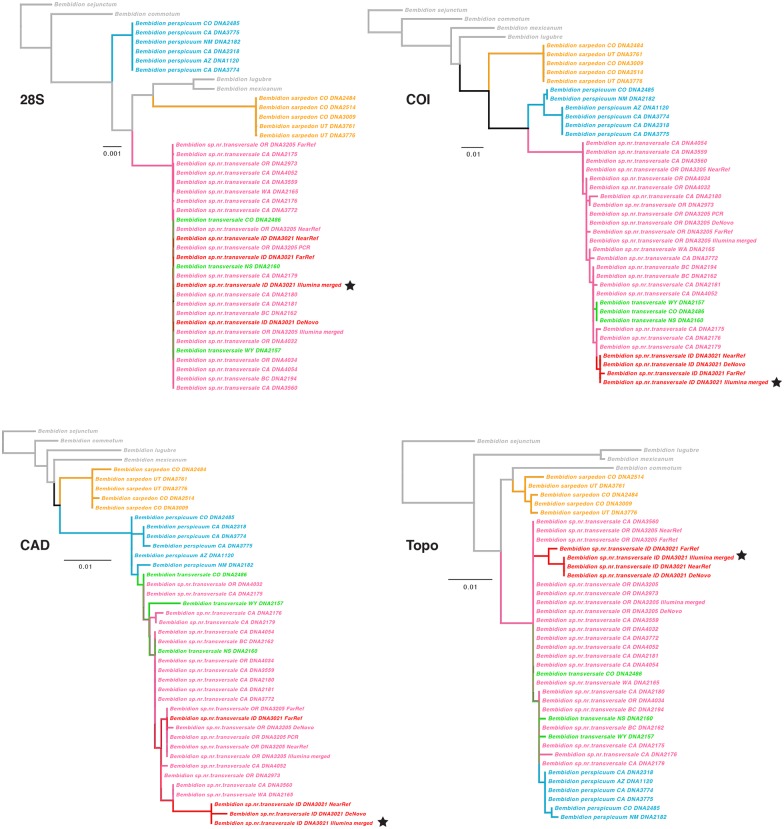
In this paper we explore high-throughput Illumina sequencing of nuclear protein-coding, ribosomal, and mitochondrial genes in small, dried insects stored in natural history collections. We sequenced one tenebrionid beetle and 12 carabid beetles ranging in size from 3.7 to 9.7 mm in length that have been stored in various museums for 4 to 84 years. Although we chose a number of old, small specimens for which we expected low sequence recovery, we successfully recovered at least some low-copy nuclear protein-coding genes from all specimens. For example, in one 56-year-old beetle, 4.4 mm in length, our de novo assembly recovered about 63% of approximately 41,900 nucleotides in a target suite of 67 nuclear protein-coding gene fragments, and 70% using a reference-based assembly. Even in the least successfully sequenced carabid specimen, reference-based assembly yielded fragments that were at least 50% of the target length for 34 of 67 nuclear protein-coding gene fragments. Exploration of alternative references for reference-based assembly revealed few signs of bias created by the reference. For all specimens we recovered almost complete copies of ribosomal and mitochondrial genes. We verified the general accuracy of the sequences through comparisons with sequences obtained from PCR and Sanger sequencing, including of conspecific, fresh specimens, and through phylogenetic analysis that tested the placement of sequences in predicted regions. A few possible inaccuracies in the sequences were detected, but these rarely affected the phylogenetic placement of the samples. Although our sample sizes are low, an exploratory regression study suggests that the dominant factor in predicting success at recovering nuclear protein-coding genes is a high number of Illumina reads, with success at PCR of COI and killing by immersion in ethanol being secondary factors; in analyses of only high-read samples, the primary significant explanatory variable was body length, with small beetles being more successfully sequenced.
在本文中,我们探索了对保存在自然历史标本馆中的小型干燥昆虫的核蛋白编码基因、核糖体基因和线粒体基因进行高通量Illumina测序。我们对一只拟步甲科甲虫和12只步甲科甲虫进行了测序,这些甲虫体长在3.7至9.7毫米之间,保存在不同博物馆中已有4至84年。尽管我们选择了一些年代久远且体型较小的标本,预计其序列回收率较低,但我们成功地从所有标本中至少获得了一些低拷贝核蛋白编码基因。例如,在一只体长4.4毫米、保存了56年的甲虫中,我们的从头组装在一组67个核蛋白编码基因片段的目标序列中恢复了约41,900个核苷酸中的约63%,基于参考序列的组装则恢复了70%。即使在测序最不成功的步甲标本中,基于参考序列的组装也产生了片段,这些片段在67个核蛋白编码基因片段中的34个中至少达到了目标长度的50%。对基于参考序列组装的替代参考序列的探索显示,参考序列产生偏差的迹象很少。对于所有标本,我们几乎获得了核糖体基因和线粒体基因的完整拷贝。我们通过与从PCR和桑格测序获得的序列进行比较,包括与同种新鲜标本的序列比较,并通过系统发育分析来测试序列在预测区域中的位置,验证了序列的总体准确性。检测到序列中存在一些可能的不准确之处,但这些很少影响样本的系统发育位置。尽管我们的样本量较小,但一项探索性回归研究表明,预测核蛋白编码基因恢复成功的主要因素是大量的Illumina读数,COI基因PCR成功和通过乙醇浸泡致死是次要因素;在仅对高读数样本的分析中,主要的显著解释变量是体长,小型甲虫的测序更成功。