Sawatzky Richard, Ratner Pamela A, Kopec Jacek A, Wu Amery D, Zumbo Bruno D
School of Nursing, Trinity Western University, Langley, British Columbia, Canada.
Centre for Health Evaluation and Outcomes Science, Providence Health Care Research Institute, Vancouver, British Columbia, Canada.
PLoS One. 2016 Mar 1;11(3):e0150563. doi: 10.1371/journal.pone.0150563. eCollection 2016.
Computerized adaptive testing (CAT) utilizes latent variable measurement model parameters that are typically assumed to be equivalently applicable to all people. Biased latent variable scores may be obtained in samples that are heterogeneous with respect to a specified measurement model. We examined the implications of sample heterogeneity with respect to CAT-predicted patient-reported outcomes (PRO) scores for the measurement of pain.
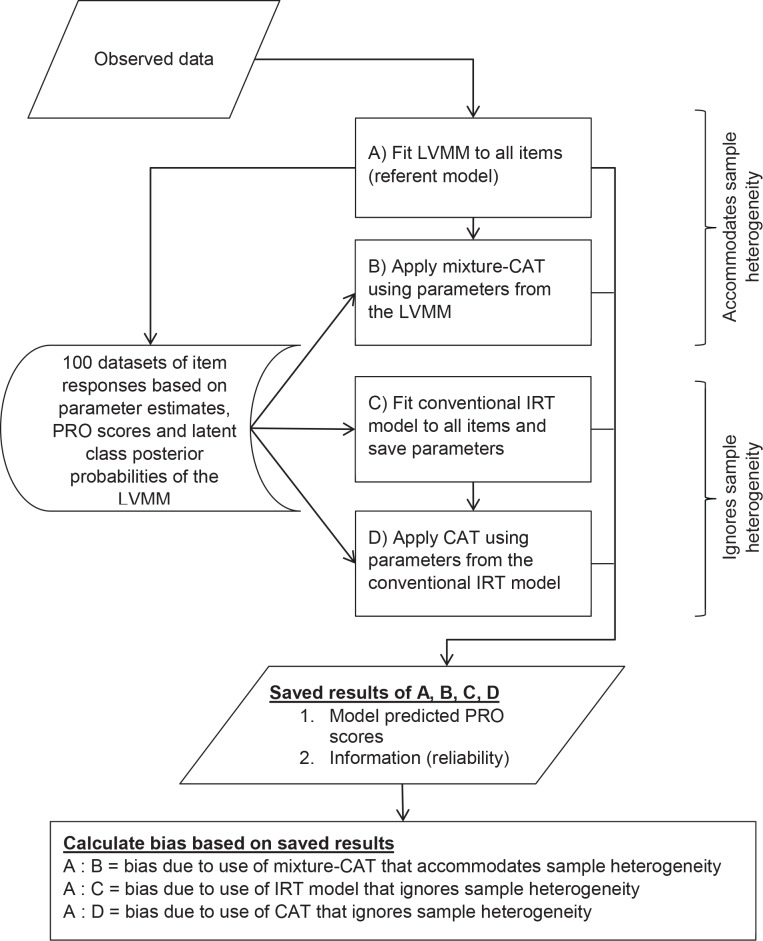
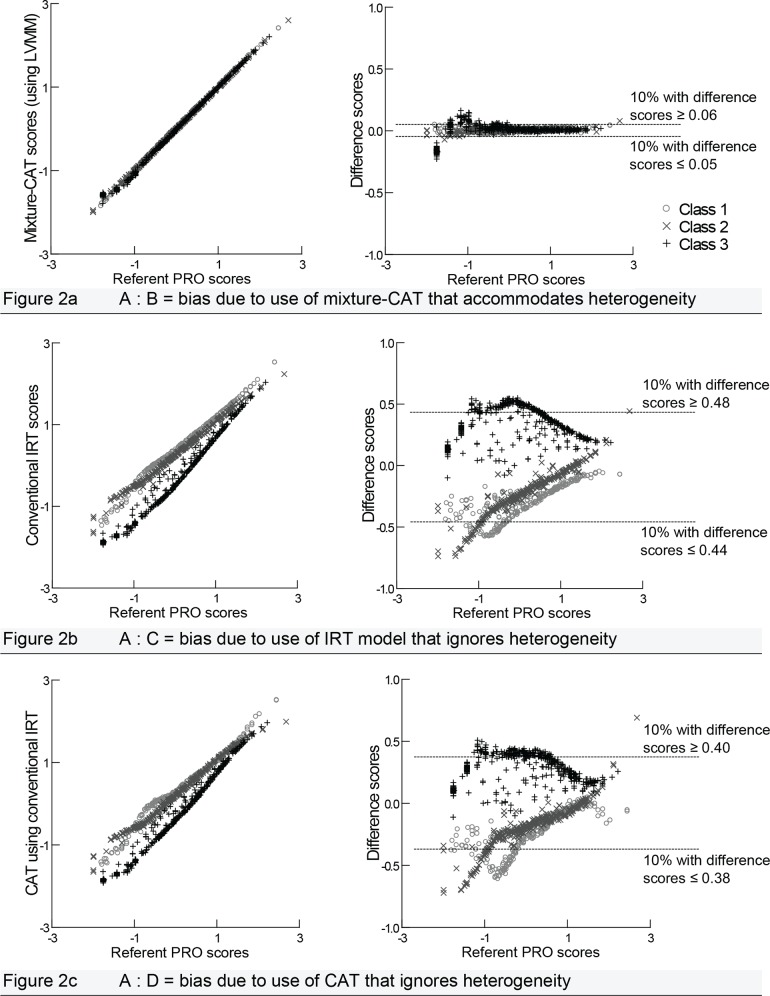
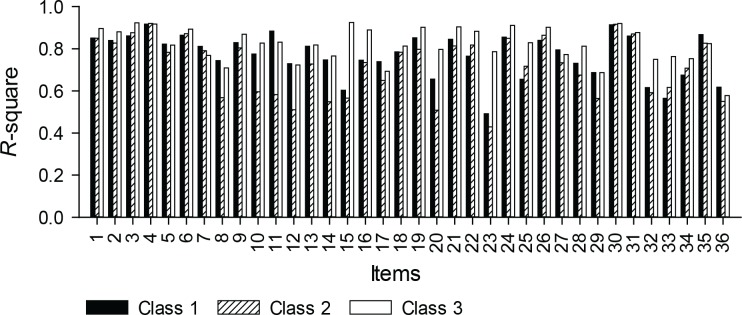
A latent variable mixture modeling (LVMM) analysis was conducted using data collected from a heterogeneous sample of people in British Columbia, Canada, who were administered the 36 pain domain items of the CAT-5D-QOL. The fitted LVMM was then used to produce data for a simulation analysis. We evaluated bias by comparing the referent PRO scores of the LVMM with PRO scores predicted by a "conventional" CAT (ignoring heterogeneity) and a LVMM-based "mixture" CAT (accommodating heterogeneity).
The LVMM analysis indicated support for three latent classes with class proportions of 0.25, 0.30 and 0.45, which suggests that the sample was heterogeneous. The simulation analyses revealed differences between the referent PRO scores and the PRO scores produced by the "conventional" CAT. The "mixture" CAT produced PRO scores that were nearly equivalent to the referent scores.
Bias in PRO scores based on latent variable models may result when population heterogeneity is ignored. Improved accuracy could be obtained by using CATs that are parameterized using LVMM.
计算机自适应测试(CAT)利用潜在变量测量模型参数,通常假定这些参数对所有人都同等适用。在相对于特定测量模型而言具有异质性的样本中,可能会获得有偏差的潜在变量分数。我们研究了样本异质性对CAT预测的患者报告结局(PRO)分数在疼痛测量方面的影响。
使用从加拿大不列颠哥伦比亚省的异质人群样本中收集的数据进行潜在变量混合建模(LVMM)分析,这些人接受了CAT-5D-QOL的36个疼痛领域项目的测试。然后,使用拟合的LVMM生成数据进行模拟分析。我们通过将LVMM的参考PRO分数与“传统”CAT(忽略异质性)和基于LVMM的“混合”CAT(考虑异质性)预测的PRO分数进行比较来评估偏差。
LVMM分析表明支持三个潜在类别,类别比例分别为0.25、0.30和0.45,这表明样本是异质的。模拟分析揭示了参考PRO分数与“传统”CAT产生的PRO分数之间的差异。“混合”CAT产生的PRO分数几乎与参考分数相等。
当忽略总体异质性时,基于潜在变量模型的PRO分数可能会产生偏差。使用通过LVMM进行参数化的CAT可以提高准确性。