Wu Xiuyun, Sawatzky Richard, Hopman Wilma, Mayo Nancy, Sajobi Tolulope T, Liu Juxin, Prior Jerilynn, Papaioannou Alexandra, Josse Robert G, Towheed Tanveer, Davison K Shawn, Lix Lisa M
School of Public Health, University of Alberta, Edmonton, AB, Canada.
School of Public Health and Health Management, Weifang Medical University, Weifang, Shandong Province, China.
Health Qual Life Outcomes. 2017 May 15;15(1):102. doi: 10.1186/s12955-017-0674-0.
Comparisons of population health status using self-report measures such as the SF-36 rest on the assumption that the measured items have a common interpretation across sub-groups. However, self-report measures may be sensitive to differential item functioning (DIF), which occurs when sub-groups with the same underlying health status have a different probability of item response. This study tested for DIF on the SF-36 physical functioning (PF) and mental health (MH) sub-scales in population-based data using latent variable mixture models (LVMMs).
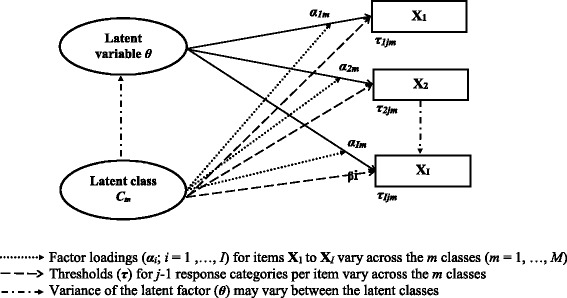
Data were from the Canadian Multicentre Osteoporosis Study (CaMos), a prospective national cohort study. LVMMs were applied to the ten PF and five MH SF-36 items. A standard two-parameter graded response model with one latent class was compared to multi-class LVMMs. Multivariable logistic regression models with pseudo-class random draws characterized the latent classes on demographic and health variables.
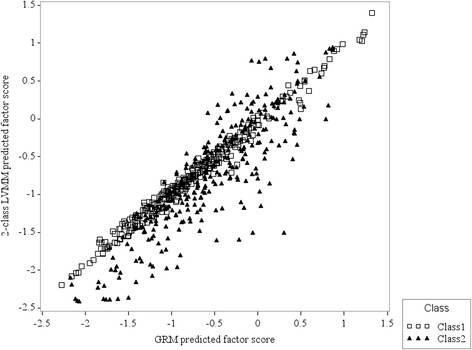
The CaMos cohort consisted of 9423 respondents. A three-class LVMM fit the PF sub-scale, with class proportions of 0.59, 0.24, and 0.17. For the MH sub-scale, a two-class model fit the data, with class proportions of 0.69 and 0.31. For PF items, the probabilities of reporting greater limitations were consistently higher in classes 2 and 3 than class 1. For MH items, respondents in class 2 reported more health problems than in class 1. Differences in item thresholds and factor loadings between one-class and multi-class models were observed for both sub-scales. Demographic and health variables were associated with class membership.
This study revealed DIF in population-based SF-36 data; the results suggest that PF and MH sub-scale scores may not be comparable across sub-groups defined by demographic and health status variables, although effects were frequently small to moderate in size. Evaluation of DIF should be a routine step when analysing population-based self-report data to ensure valid comparisons amongst sub-groups.
使用诸如SF-36等自我报告测量方法对人群健康状况进行比较,其依据的假设是所测量的项目在各个亚组中具有共同的解释。然而,自我报告测量方法可能对差异项目功能(DIF)敏感,当具有相同潜在健康状况的亚组对项目做出反应的概率不同时,就会出现DIF。本研究使用潜在变量混合模型(LVMMs)在基于人群的数据中测试SF-36身体功能(PF)和心理健康(MH)子量表的DIF。
数据来自加拿大多中心骨质疏松症研究(CaMos),这是一项前瞻性全国队列研究。LVMMs应用于SF-36的10个PF项目和5个MH项目。将具有一个潜在类别的标准双参数等级反应模型与多类别LVMMs进行比较。具有伪类随机抽样的多变量逻辑回归模型对人口统计学和健康变量的潜在类别进行了特征描述。
CaMos队列由9423名受访者组成。一个三类LVMMs适合PF子量表,类别比例分别为0.59、0.24和0.17。对于MH子量表,一个两类模型适合数据,类别比例分别为0.69和0.31。对于PF项目,在第2类和第3类中报告更大限制的概率始终高于第1类。对于MH项目,第2类中的受访者报告的健康问题比第1类更多。在两个子量表中均观察到单类模型和多类模型之间项目阈值和因子载荷的差异。人口统计学和健康变量与类别归属相关。
本研究揭示了基于人群的SF-36数据中的DIF;结果表明,尽管影响大小通常为小到中等,但PF和MH子量表得分在由人口统计学和健康状况变量定义的亚组之间可能不可比。在分析基于人群的自我报告数据时,对DIF的评估应作为一个常规步骤,以确保亚组之间的有效比较。