Computational Biology Department, School of Computer Science, Carnegie Mellon University, 5000 Forbes Avenue, Pittsburgh, PA 15213, USA.
Computational Biology Department, School of Computer Science, Carnegie Mellon University, 5000 Forbes Avenue, Pittsburgh, PA 15213, USA.
Cell Syst. 2016 Jul;3(1):35-42. doi: 10.1016/j.cels.2016.06.007. Epub 2016 Jul 21.
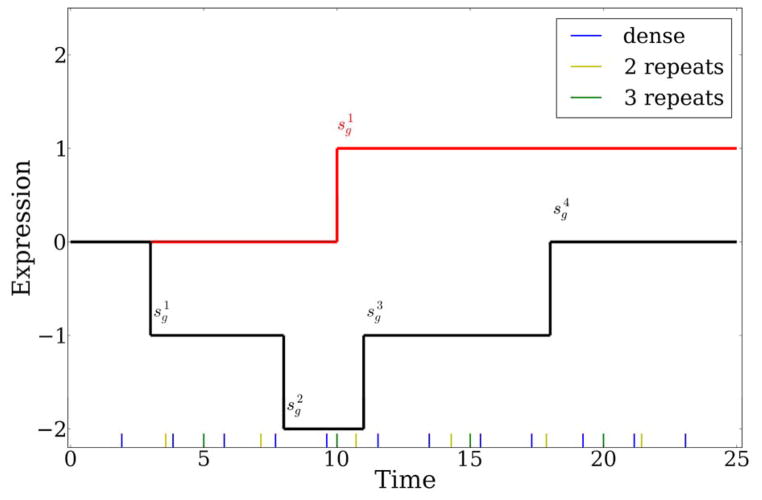
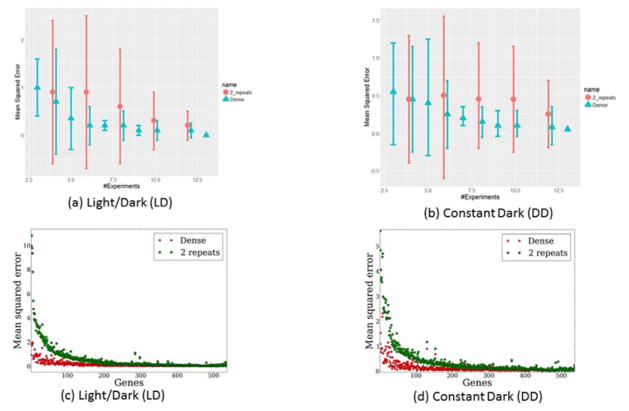
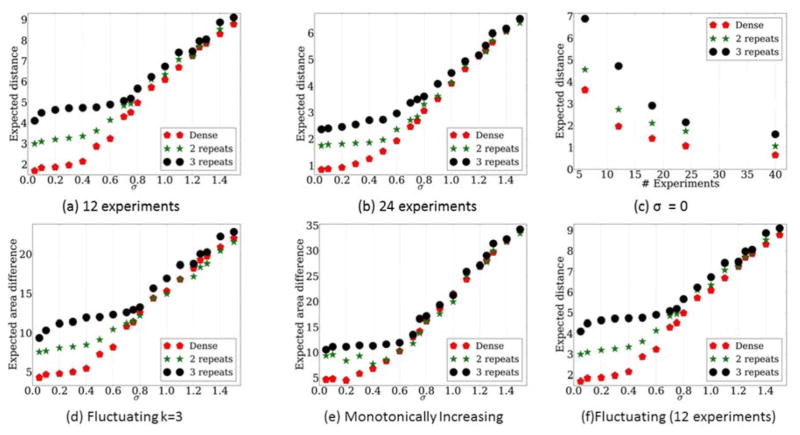
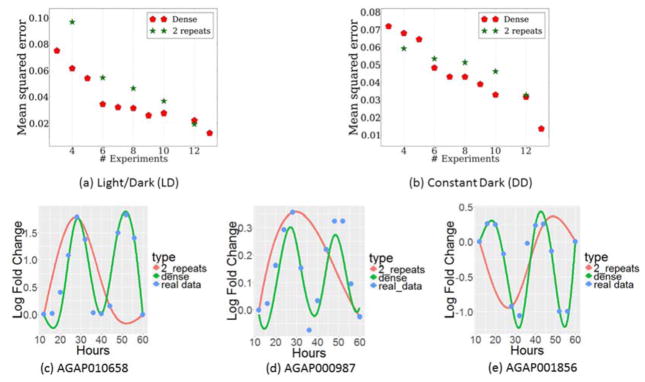
An important experimental design question for high-throughput time series studies is the number of replicates required for accurate reconstruction of the profiles. Due to budget and sample availability constraints, more replicates imply fewer time points and vice versa. We analyze the performance of dense and replicate sampling by developing a theoretical framework that focuses on a restricted yet expressive set of possible curves over a wide range of noise levels and by analyzing real expression data. For both the theoretical analysis and experimental data, we observe that, under reasonable noise levels, autocorrelations in the time series data allow dense sampling to better determine the correct levels of non-sampled points when compared to replicate sampling. A Java implementation of our framework can be used to determine the best replicate strategy given the expected noise. These results provide theoretical support to the large number of high-throughput time series experiments that do not use replicates.
对于高通量时间序列研究,一个重要的实验设计问题是为了准确重建曲线所需的重复样本数量。由于预算和样本可用性的限制,更多的重复样本意味着更少的时间点,反之亦然。我们通过开发一个理论框架来分析密集采样和重复采样的性能,该框架侧重于在广泛的噪声水平下对一组受限但表现力强的可能曲线进行分析,并通过分析真实的表达数据来进行分析。对于理论分析和实验数据,我们观察到,在合理的噪声水平下,时间序列数据中的自相关允许密集采样在与重复采样相比时更好地确定未采样点的正确水平。我们框架的 Java 实现可以根据预期的噪声来确定最佳的重复策略。这些结果为大量不使用重复样本的高通量时间序列实验提供了理论支持。