Jiang Yuxiang, Oron Tal Ronnen, Clark Wyatt T, Bankapur Asma R, D'Andrea Daniel, Lepore Rosalba, Funk Christopher S, Kahanda Indika, Verspoor Karin M, Ben-Hur Asa, Koo Da Chen Emily, Penfold-Brown Duncan, Shasha Dennis, Youngs Noah, Bonneau Richard, Lin Alexandra, Sahraeian Sayed M E, Martelli Pier Luigi, Profiti Giuseppe, Casadio Rita, Cao Renzhi, Zhong Zhaolong, Cheng Jianlin, Altenhoff Adrian, Skunca Nives, Dessimoz Christophe, Dogan Tunca, Hakala Kai, Kaewphan Suwisa, Mehryary Farrokh, Salakoski Tapio, Ginter Filip, Fang Hai, Smithers Ben, Oates Matt, Gough Julian, Törönen Petri, Koskinen Patrik, Holm Liisa, Chen Ching-Tai, Hsu Wen-Lian, Bryson Kevin, Cozzetto Domenico, Minneci Federico, Jones David T, Chapman Samuel, Bkc Dukka, Khan Ishita K, Kihara Daisuke, Ofer Dan, Rappoport Nadav, Stern Amos, Cibrian-Uhalte Elena, Denny Paul, Foulger Rebecca E, Hieta Reija, Legge Duncan, Lovering Ruth C, Magrane Michele, Melidoni Anna N, Mutowo-Meullenet Prudence, Pichler Klemens, Shypitsyna Aleksandra, Li Biao, Zakeri Pooya, ElShal Sarah, Tranchevent Léon-Charles, Das Sayoni, Dawson Natalie L, Lee David, Lees Jonathan G, Sillitoe Ian, Bhat Prajwal, Nepusz Tamás, Romero Alfonso E, Sasidharan Rajkumar, Yang Haixuan, Paccanaro Alberto, Gillis Jesse, Sedeño-Cortés Adriana E, Pavlidis Paul, Feng Shou, Cejuela Juan M, Goldberg Tatyana, Hamp Tobias, Richter Lothar, Salamov Asaf, Gabaldon Toni, Marcet-Houben Marina, Supek Fran, Gong Qingtian, Ning Wei, Zhou Yuanpeng, Tian Weidong, Falda Marco, Fontana Paolo, Lavezzo Enrico, Toppo Stefano, Ferrari Carlo, Giollo Manuel, Piovesan Damiano, Tosatto Silvio C E, Del Pozo Angela, Fernández José M, Maietta Paolo, Valencia Alfonso, Tress Michael L, Benso Alfredo, Di Carlo Stefano, Politano Gianfranco, Savino Alessandro, Rehman Hafeez Ur, Re Matteo, Mesiti Marco, Valentini Giorgio, Bargsten Joachim W, van Dijk Aalt D J, Gemovic Branislava, Glisic Sanja, Perovic Vladmir, Veljkovic Veljko, Veljkovic Nevena, Almeida-E-Silva Danillo C, Vencio Ricardo Z N, Sharan Malvika, Vogel Jörg, Kansakar Lakesh, Zhang Shanshan, Vucetic Slobodan, Wang Zheng, Sternberg Michael J E, Wass Mark N, Huntley Rachael P, Martin Maria J, O'Donovan Claire, Robinson Peter N, Moreau Yves, Tramontano Anna, Babbitt Patricia C, Brenner Steven E, Linial Michal, Orengo Christine A, Rost Burkhard, Greene Casey S, Mooney Sean D, Friedberg Iddo, Radivojac Predrag
Department of Computer Science and Informatics, Indiana University, Bloomington, IN, USA.
Buck Institute for Research on Aging, Novato, CA, USA.
Genome Biol. 2016 Sep 7;17(1):184. doi: 10.1186/s13059-016-1037-6.
A major bottleneck in our understanding of the molecular underpinnings of life is the assignment of function to proteins. While molecular experiments provide the most reliable annotation of proteins, their relatively low throughput and restricted purview have led to an increasing role for computational function prediction. However, assessing methods for protein function prediction and tracking progress in the field remain challenging.
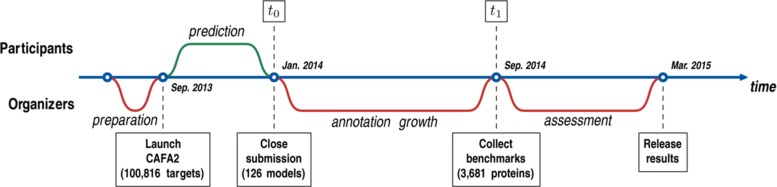
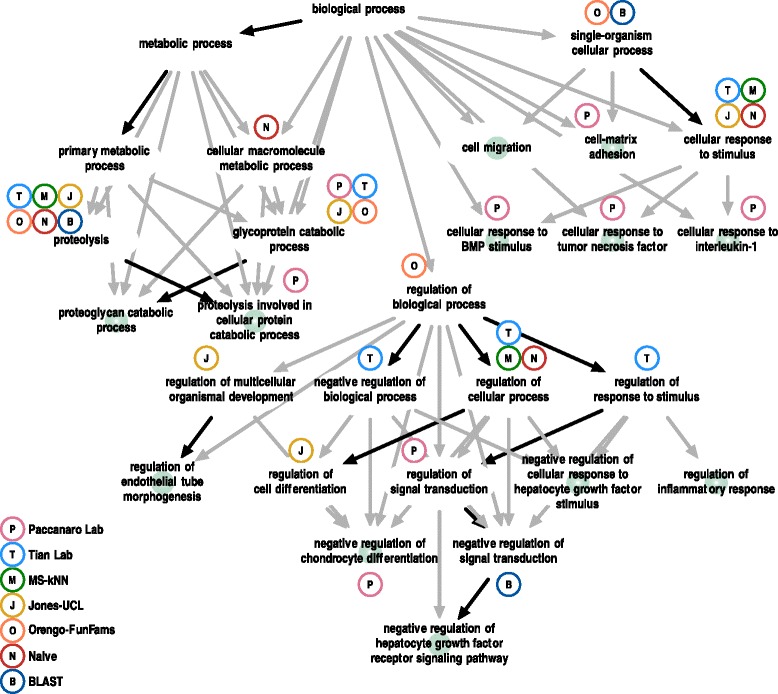
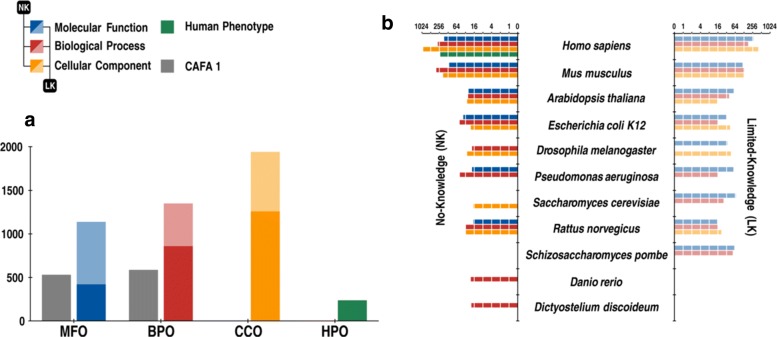
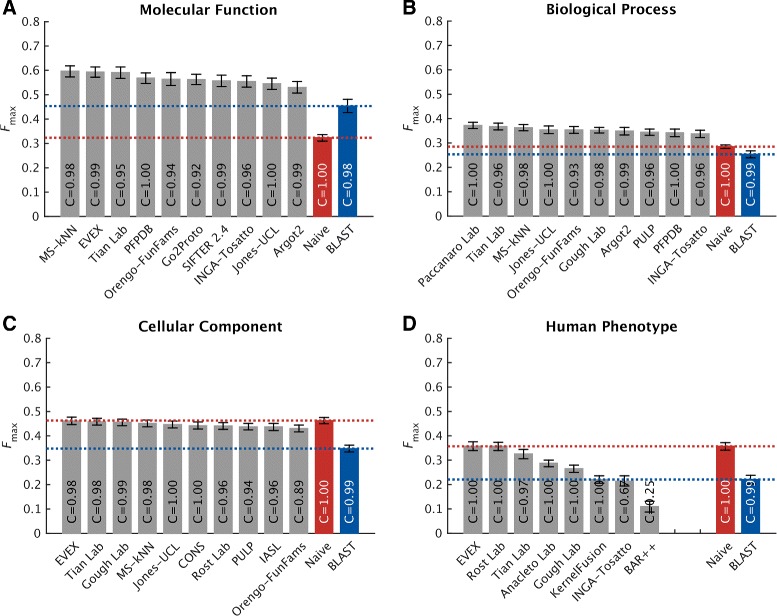
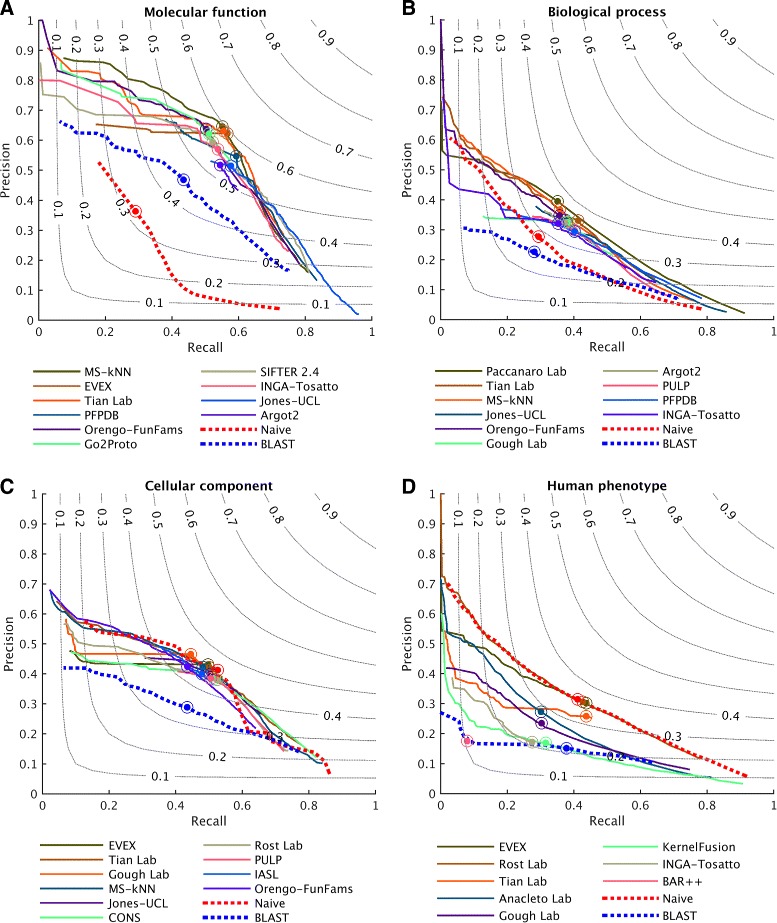
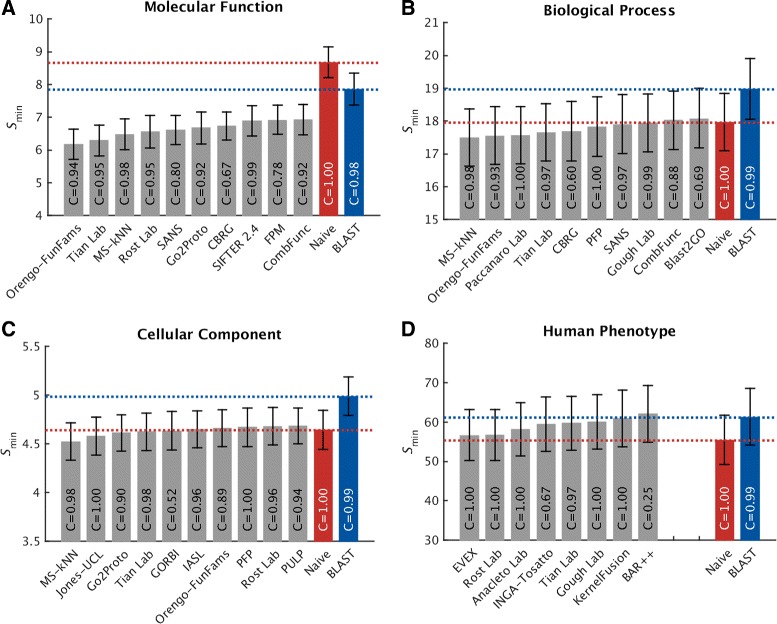
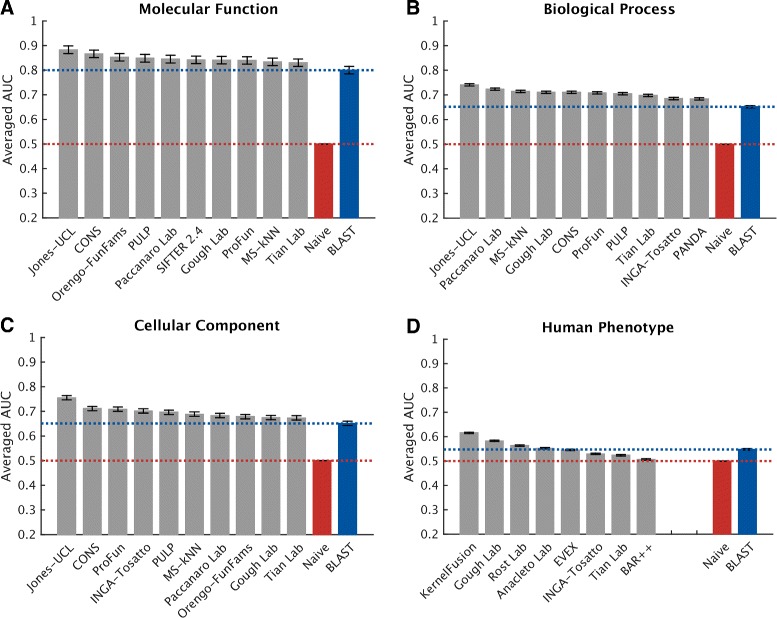
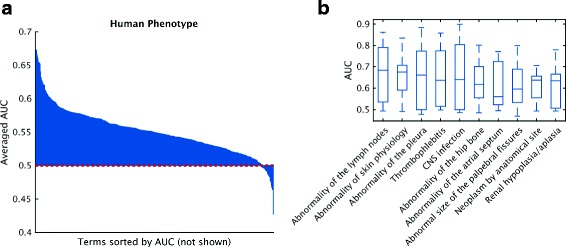
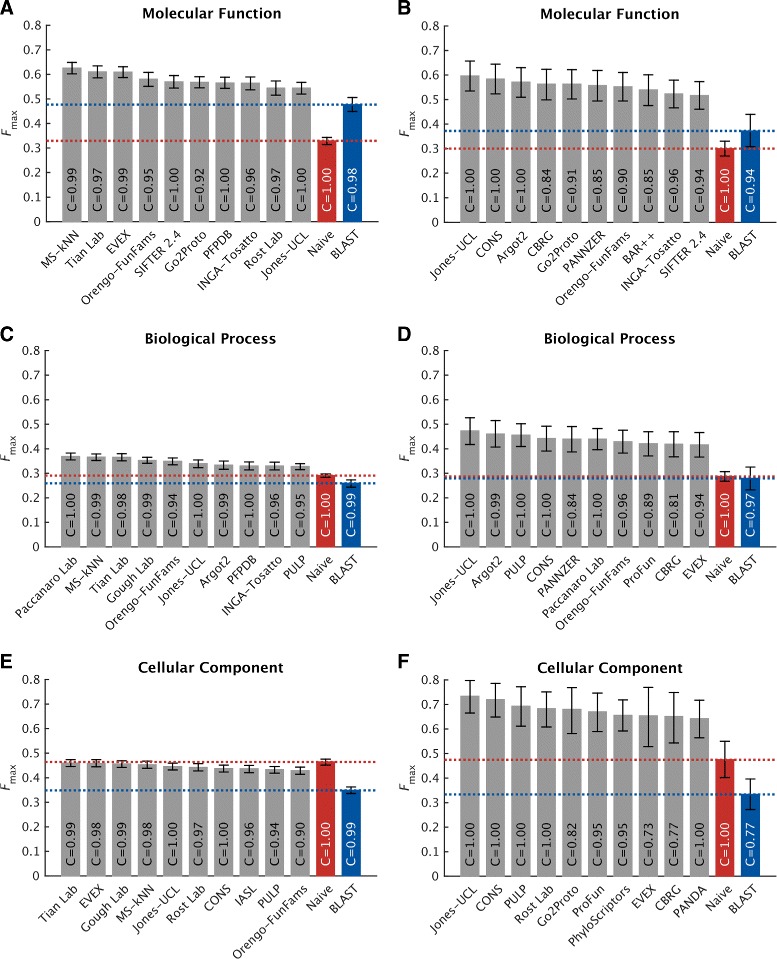
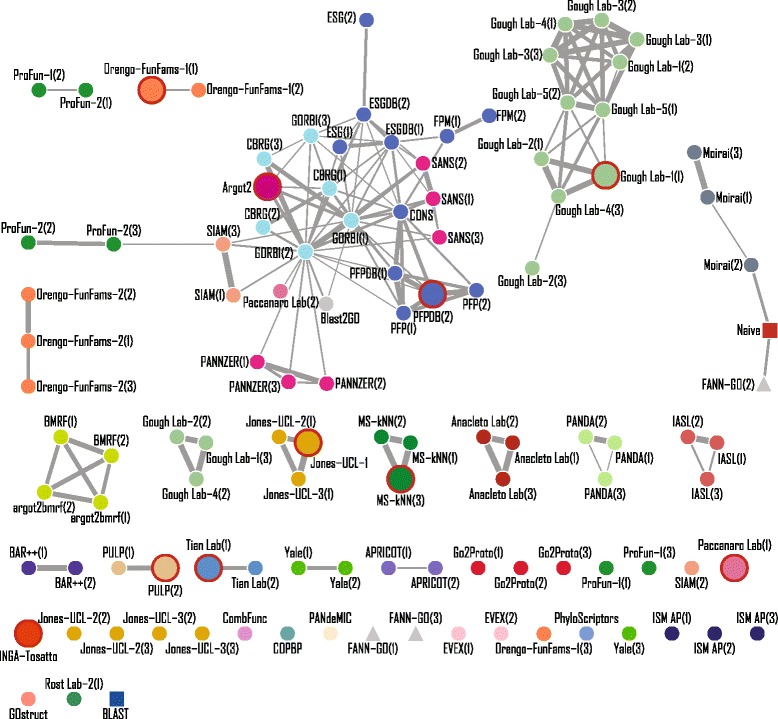
We conducted the second critical assessment of functional annotation (CAFA), a timed challenge to assess computational methods that automatically assign protein function. We evaluated 126 methods from 56 research groups for their ability to predict biological functions using Gene Ontology and gene-disease associations using Human Phenotype Ontology on a set of 3681 proteins from 18 species. CAFA2 featured expanded analysis compared with CAFA1, with regards to data set size, variety, and assessment metrics. To review progress in the field, the analysis compared the best methods from CAFA1 to those of CAFA2.
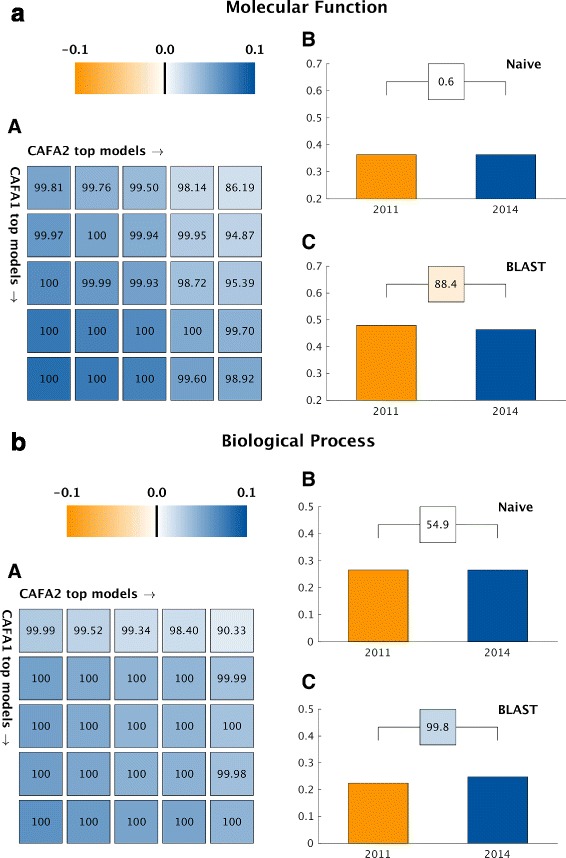
The top-performing methods in CAFA2 outperformed those from CAFA1. This increased accuracy can be attributed to a combination of the growing number of experimental annotations and improved methods for function prediction. The assessment also revealed that the definition of top-performing algorithms is ontology specific, that different performance metrics can be used to probe the nature of accurate predictions, and the relative diversity of predictions in the biological process and human phenotype ontologies. While there was methodological improvement between CAFA1 and CAFA2, the interpretation of results and usefulness of individual methods remain context-dependent.
我们在理解生命分子基础方面的一个主要瓶颈是蛋白质功能的分配。虽然分子实验能提供最可靠的蛋白质注释,但它们相对较低的通量和有限的范围导致计算功能预测的作用日益增加。然而,评估蛋白质功能预测方法并跟踪该领域的进展仍然具有挑战性。
我们进行了第二次功能注释关键评估(CAFA),这是一项限时挑战,用于评估自动分配蛋白质功能的计算方法。我们评估了来自56个研究小组的126种方法,这些方法利用基因本体论预测生物功能,并利用人类表型本体论对来自18个物种的3681种蛋白质的基因 - 疾病关联进行预测。与CAFA1相比,CAFA2在数据集大小、多样性和评估指标方面进行了扩展分析。为了回顾该领域的进展,分析将CAFA1中的最佳方法与CAFA2中的方法进行了比较。
CAFA2中表现最佳的方法优于CAFA1中的方法。这种准确性的提高可归因于实验注释数量的增加和功能预测方法的改进。评估还表明,表现最佳的算法的定义是特定于本体的,不同的性能指标可用于探究准确预测的本质,以及生物过程和人类表型本体中预测的相对多样性。虽然CAFA1和CAFA2之间在方法上有所改进,但结果的解释和个别方法的有用性仍然依赖于上下文。