Haneuse Sebastien, Daniels Michael
Harvard T.H. Chan School of Public Health.
University of Texas-Austin.
EGEMS (Wash DC). 2016 Aug 31;4(1):1203. doi: 10.13063/2327-9214.1203. eCollection 2016.
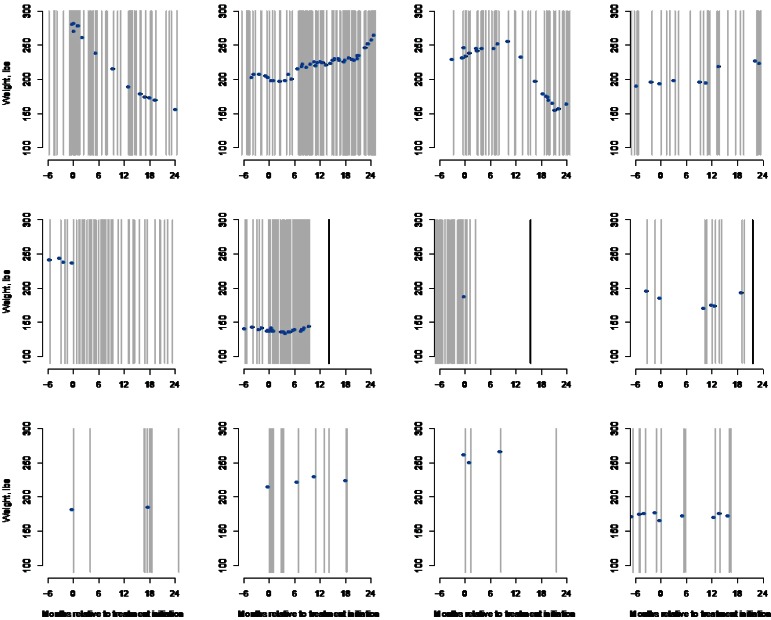
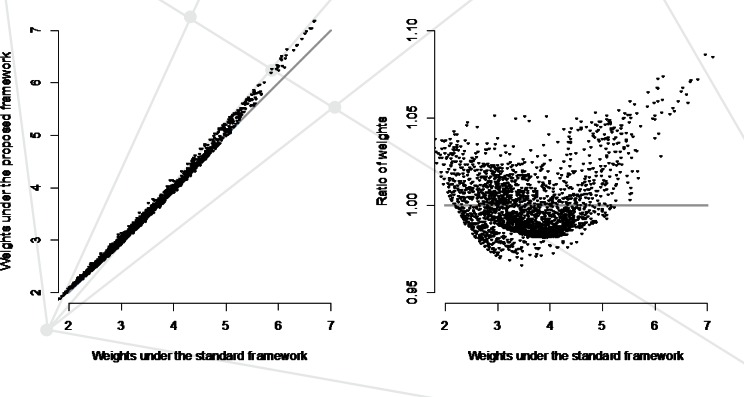
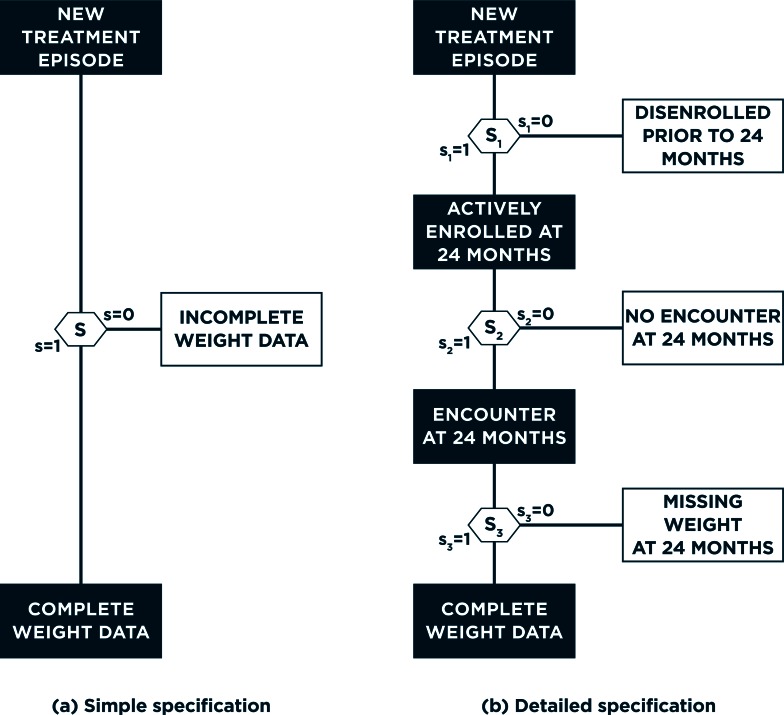
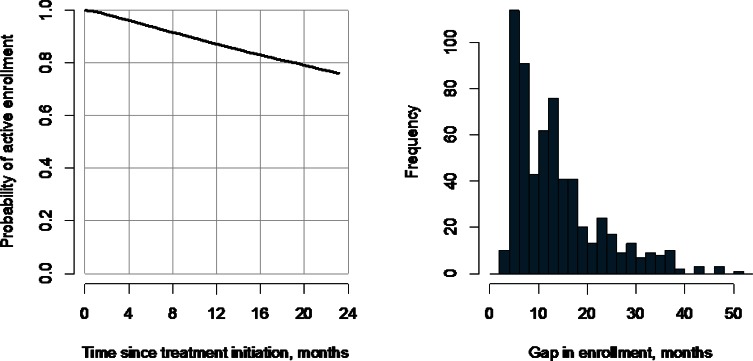
Electronic health records (EHR) data are increasingly seen as a resource for cost-effective comparative effectiveness research (CER). Since EHR data are collected primarily for clinical and/or billing purposes, their use for CER requires consideration of numerous methodologic challenges including the potential for confounding bias, due to a lack of randomization, and for selection bias, due to missing data. In contrast to the recent literature on confounding bias in EHR-based CER, virtually no attention has been paid to selection bias possibly due to the belief that standard methods for missing data can be readily-applied. Such methods, however, hinge on an overly simplistic view of the available/missing EHR data, so that their application in the EHR setting will often fail to completely control selection bias. Motivated by challenges we face in an on-going EHR-based comparative effectiveness study of choice of antidepressant treatment and long-term weight change, we propose a new general framework for selection bias in EHR-based CER. Crucially, the framework provides structure within which researchers can consider the complex interplay between numerous decisions, made by patients and health care providers, which give rise to health-related information being recorded in the EHR system, as well as the wide variability across EHR systems themselves. This, in turn, provides structure within which: (i) the transparency of assumptions regarding missing data can be enhanced, (ii) factors relevant to each decision can be elicited, and (iii) statistical methods can be better aligned with the complexity of the data.
电子健康记录(EHR)数据越来越被视为开展具有成本效益的比较效果研究(CER)的一种资源。由于EHR数据主要是为临床和/或计费目的而收集的,将其用于CER需要考虑众多方法学挑战,包括因缺乏随机化而导致的混杂偏倚可能性,以及因存在缺失数据而导致的选择偏倚可能性。与近期关于基于EHR的CER中混杂偏倚的文献形成对照的是,可能由于人们认为缺失数据的标准方法可以轻易应用,所以几乎没有人关注选择偏倚问题。然而,此类方法依赖于对可用/缺失的EHR数据的过于简单化观点,以至于它们在EHR环境中的应用往往无法完全控制选择偏倚。受我们在一项正在进行的基于EHR的抗抑郁治疗选择与长期体重变化比较效果研究中所面临挑战的启发,我们针对基于EHR的CER中的选择偏倚提出了一个新的通用框架。至关重要的是,该框架提供了一种架构,研究人员可以在此架构内考虑患者和医疗服务提供者做出的众多决策之间的复杂相互作用,这些决策导致与健康相关的信息被记录在EHR系统中,以及EHR系统本身之间的广泛差异。反过来,这又提供了一种架构,在此架构内:(i)可以增强关于缺失数据的假设的透明度,(ii)可以引出与每个决策相关的因素,并且(iii)统计方法可以更好地与数据的复杂性相匹配。