Belgrave Danielle, Henderson John, Simpson Angela, Buchan Iain, Bishop Christopher, Custovic Adnan
Department of Paediatrics, Imperial College, London, United Kingdom.
School of Social and Community Medicine, Faculty of Health Sciences, University of Bristol, Bristol, United Kingdom.
J Allergy Clin Immunol. 2017 Feb;139(2):400-407. doi: 10.1016/j.jaci.2016.11.003. Epub 2016 Nov 18.
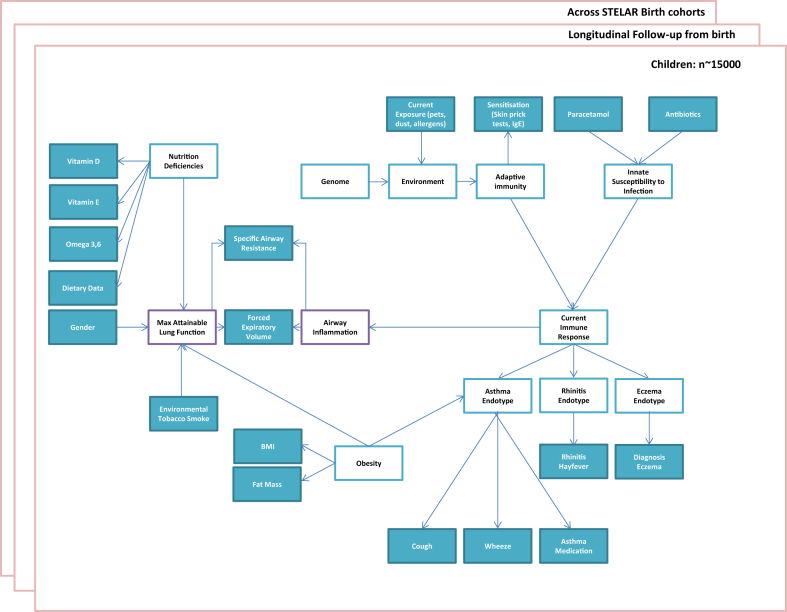
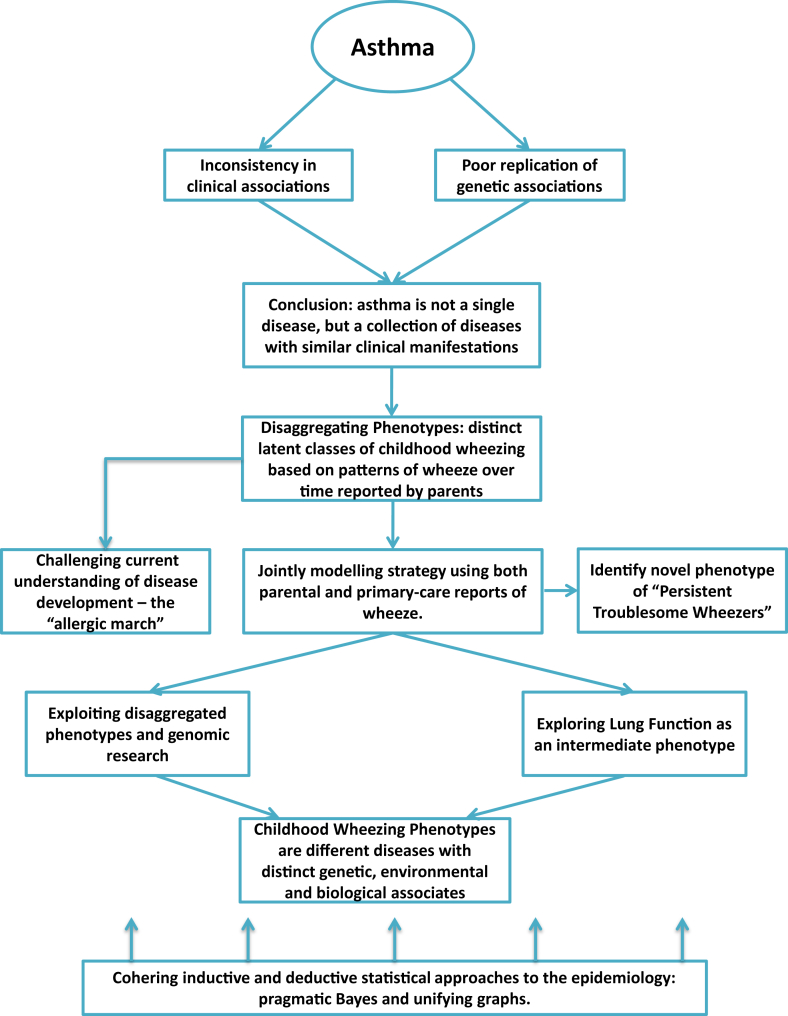
We are facing a major challenge in bridging the gap between identifying subtypes of asthma to understand causal mechanisms and translating this knowledge into personalized prevention and management strategies. In recent years, "big data" has been sold as a panacea for generating hypotheses and driving new frontiers of health care; the idea that the data must and will speak for themselves is fast becoming a new dogma. One of the dangers of ready accessibility of health care data and computational tools for data analysis is that the process of data mining can become uncoupled from the scientific process of clinical interpretation, understanding the provenance of the data, and external validation. Although advances in computational methods can be valuable for using unexpected structure in data to generate hypotheses, there remains a need for testing hypotheses and interpreting results with scientific rigor. We argue for combining data- and hypothesis-driven methods in a careful synergy, and the importance of carefully characterized birth and patient cohorts with genetic, phenotypic, biological, and molecular data in this process cannot be overemphasized. The main challenge on the road ahead is to harness bigger health care data in ways that produce meaningful clinical interpretation and to translate this into better diagnoses and properly personalized prevention and treatment plans. There is a pressing need for cross-disciplinary research with an integrative approach to data science, whereby basic scientists, clinicians, data analysts, and epidemiologists work together to understand the heterogeneity of asthma.
在弥合识别哮喘亚型以了解因果机制与将这些知识转化为个性化预防和管理策略之间的差距方面,我们正面临一项重大挑战。近年来,“大数据”被吹捧为生成假设和推动医疗保健新前沿的万灵药;认为数据必须且将会自行说明问题的观点正迅速成为一种新的教条。医疗保健数据和数据分析计算工具易于获取带来的一个危险在于,数据挖掘过程可能会与临床解释、理解数据来源以及外部验证的科学过程脱节。尽管计算方法的进步对于利用数据中意外的结构来生成假设可能很有价值,但仍然需要以科学的严谨性来检验假设和解释结果。我们主张将数据驱动和假设驱动的方法谨慎地协同结合起来,并且在此过程中,具有精心表征的出生和患者队列以及遗传、表型、生物学和分子数据的重要性再怎么强调也不为过。未来道路上的主要挑战是利用更大的医疗保健数据,以产生有意义的临床解释,并将其转化为更好的诊断以及恰当的个性化预防和治疗方案。迫切需要采用跨学科研究以及数据科学的综合方法,基础科学家、临床医生、数据分析师和流行病学家共同努力,以了解哮喘的异质性。