Institute of Molecular Biology and Biotechnology (IMBB), The University of Lahore (UOL), Lahore 54590, Pakistan.
The Steve and Cindy Rasmussen Institute for Genomic Medicine, Nationwide Children's Hospital, Columbus, OH 43205, USA.
Int J Mol Sci. 2022 Apr 22;23(9):4645. doi: 10.3390/ijms23094645.
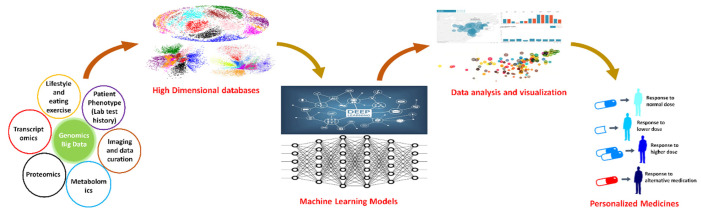
Big data in health care is a fast-growing field and a new paradigm that is transforming case-based studies to large-scale, data-driven research. As big data is dependent on the advancement of new data standards, technology, and relevant research, the future development of big data applications holds foreseeable promise in the modern day health care revolution. Enormously large, rapidly growing collections of biomedical omics-data (genomics, proteomics, transcriptomics, metabolomics, glycomics, etc.) and clinical data create major challenges and opportunities for their analysis and interpretation and open new computational gateways to address these issues. The design of new robust algorithms that are most suitable to properly analyze this big data by taking into account individual variability in genes has enabled the creation of precision (personalized) medicine. We reviewed and highlighted the significance of big data analytics for personalized medicine and health care by focusing mostly on machine learning perspectives on personalized medicine, genomic data models with respect to personalized medicine, the application of data mining algorithms for personalized medicine as well as the challenges we are facing right now in big data analytics.
医疗保健中的大数据是一个快速发展的领域和新范式,正在将基于案例的研究转变为大规模、数据驱动的研究。由于大数据依赖于新的数据标准、技术和相关研究的进步,因此大数据应用的未来发展在当今的医疗保健革命中具有可预见的前景。生物医学组学数据(基因组学、蛋白质组学、转录组学、代谢组学、糖组学等)和临床数据的大规模、快速增长,为它们的分析和解释带来了重大挑战和机遇,并为解决这些问题开辟了新的计算途径。设计新的稳健算法,通过考虑基因的个体变异性来正确分析这些大数据,从而实现了精准(个性化)医学。我们主要从个性化医学的机器学习角度、个性化医学的基因组学数据模型、个性化医学的数据挖掘算法的应用以及我们目前在大数据分析中面临的挑战等方面,综述并强调了大数据分析在个性化医学和医疗保健中的重要性。