Colunga Eliana, Sims Clare E
Department of Psychology and Neuroscience, University of Colorado, Boulder.
Cogn Sci. 2017 Feb;41 Suppl 1(Suppl 1):73-95. doi: 10.1111/cogs.12409. Epub 2016 Nov 21.
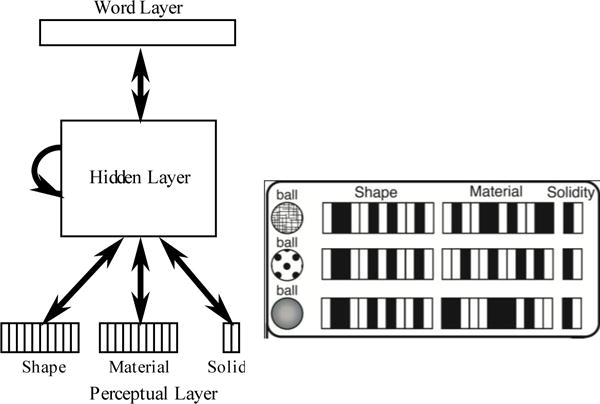
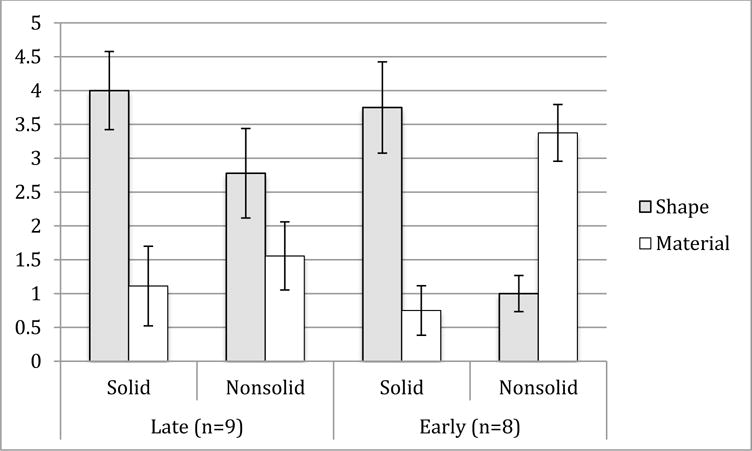
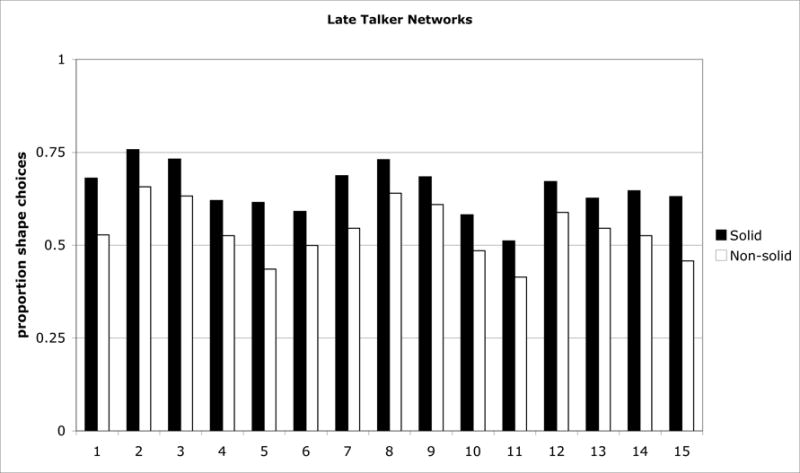
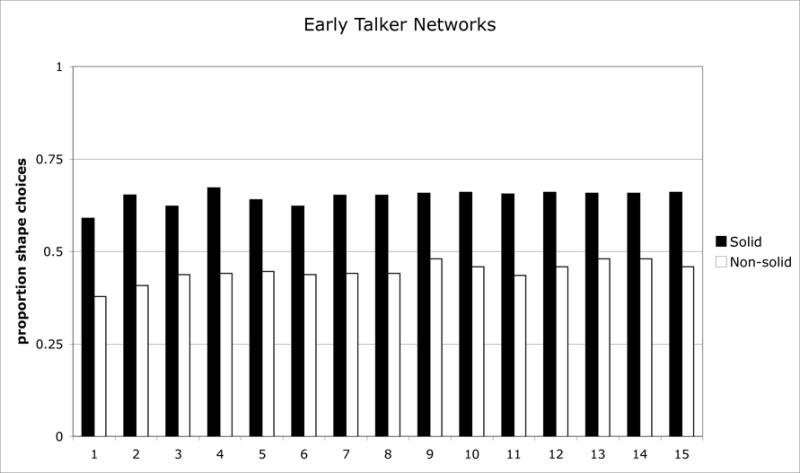
In typical development, word learning goes from slow and laborious to fast and seemingly effortless. Typically developing 2-year-olds seem to intuit the whole range of things in a category from hearing a single instance named-they have word-learning biases. This is not the case for children with relatively small vocabularies (late talkers). We present a computational model that accounts for the emergence of word-learning biases in children at both ends of the vocabulary spectrum based solely on vocabulary structure. The results of Experiment 1 show that late-talkers' and early-talkers' noun vocabularies have different structures and that neural networks trained on the vocabularies of individual late talkers acquire different word-learning biases than those trained on early-talker vocabularies. These models make novel predictions about the word-learning biases in these two populations. Experiment 2 tests these predictions on late- and early-talking toddlers in a novel noun generalization task.
在典型的语言发展过程中,词汇学习从缓慢且费力逐渐变得快速且看似轻松。典型发展的2岁儿童似乎仅通过听到一个被命名的实例就能直观地理解一个类别中的所有事物——他们具有词汇学习偏向。词汇量相对较小的儿童(说话较晚的孩子)则并非如此。我们提出了一个计算模型,该模型仅基于词汇结构就能解释词汇量处于两个极端的儿童中词汇学习偏向的出现。实验1的结果表明,说话较晚的孩子和说话较早的孩子的名词词汇结构不同,并且在个别说话较晚的孩子的词汇上训练的神经网络与在说话较早的孩子的词汇上训练的神经网络获得的词汇学习偏向不同。这些模型对这两类人群的词汇学习偏向做出了新颖的预测。实验2在一项新颖的名词泛化任务中对说话较晚和较早的幼儿测试了这些预测。