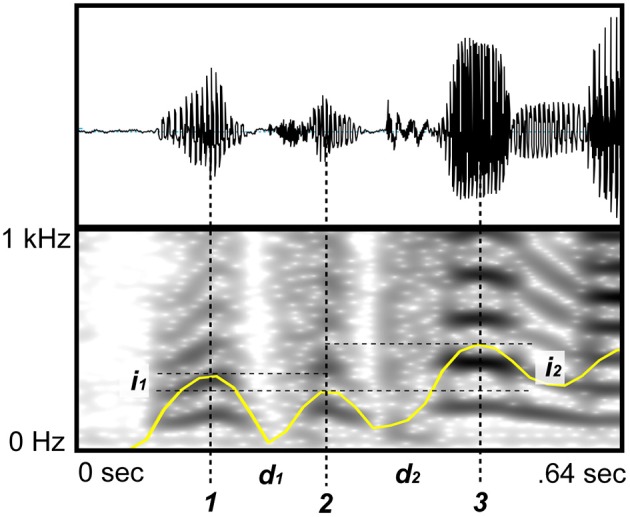
Jadoul Yannick, Ravignani Andrea, Thompson Bill, Filippi Piera, de Boer Bart
Artificial Intelligence Lab, Vrije Universiteit Brussel Brussels, Belgium.
Front Hum Neurosci. 2016 Dec 2;10:586. doi: 10.3389/fnhum.2016.00586. eCollection 2016.
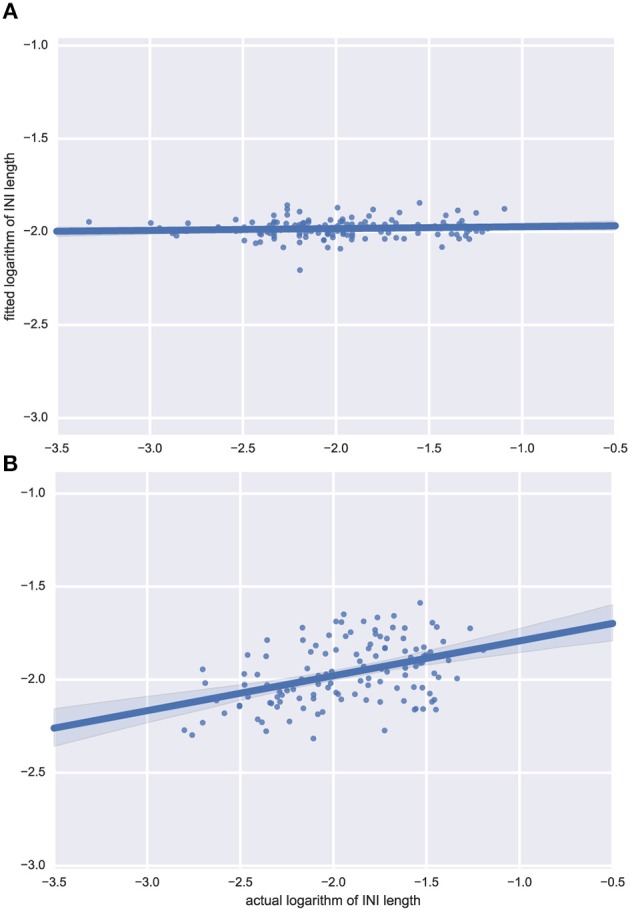
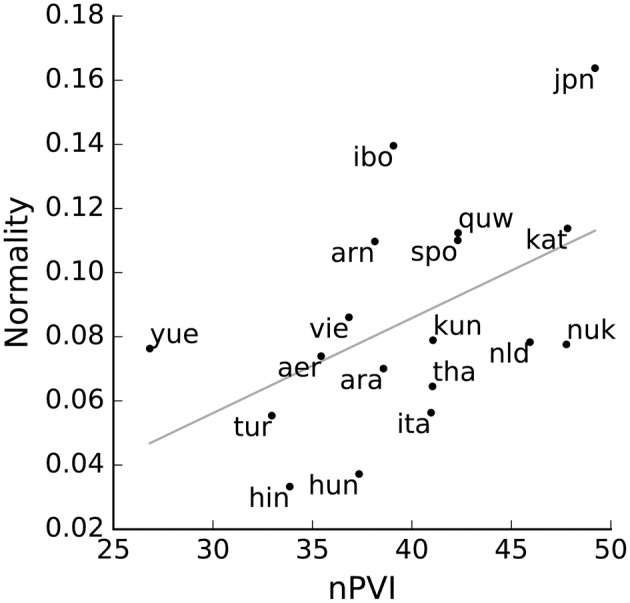
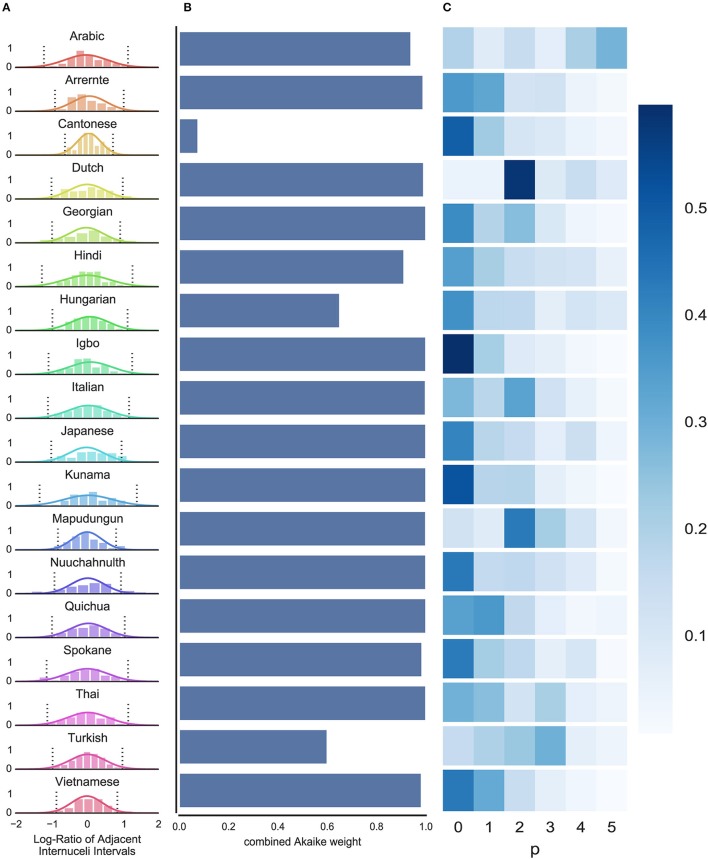
Temporal regularities in speech, such as interdependencies in the timing of speech events, are thought to scaffold early acquisition of the building blocks in speech. By providing on-line clues to the location and duration of upcoming syllables, temporal structure may aid segmentation and clustering of continuous speech into separable units. This hypothesis tacitly assumes that learners exploit in the temporal structure of speech. Existing measures of speech timing tend to focus on first-order regularities among adjacent units, and are overly sensitive to idiosyncrasies in the data they describe. Here, we compare several statistical methods on a sample of 18 languages, testing whether syllable occurrence is predictable over time. Rather than looking for differences between languages, we aim to find across languages (using clearly defined acoustic, rather than orthographic, measures), temporal predictability in the speech signal which could be exploited by a language learner. First, we analyse distributional regularities using two novel techniques: a Bayesian ideal learner analysis, and a simple distributional measure. Second, we model temporal structure-regularities arising in an ordered of syllable timings-testing the hypothesis that non-adjacent temporal structures may explain the gap between subjectively-perceived temporal regularities, and the absence of universally-accepted lower-order objective measures. Together, our analyses provide limited evidence for predictability at different time scales, though higher-order predictability is difficult to reliably infer. We conclude that temporal predictability in speech may well arise from a combination of individually weak perceptual cues at multiple structural levels, but is challenging to pinpoint.
语音中的时间规律,比如语音事件时间上的相互依存关系,被认为是早期语音构建模块习得的支架。通过为即将出现的音节的位置和时长提供在线线索,时间结构可能有助于将连续语音分割和聚类成可分离的单元。这一假设默认学习者会利用语音的时间结构。现有的语音计时测量往往侧重于相邻单元之间的一阶规律,并且对它们所描述的数据中的特质过于敏感。在这里,我们在18种语言的样本上比较了几种统计方法,测试音节出现是否随时间可预测。我们的目标不是寻找语言之间的差异,而是(使用明确界定的声学而非正字法测量)在各种语言中找到语言学习者可以利用的语音信号中的时间可预测性。首先,我们使用两种新技术分析分布规律:贝叶斯理想学习者分析和一种简单的分布测量。其次,我们对音节计时顺序中出现的时间结构规律进行建模——检验非相邻时间结构可能解释主观感知的时间规律与缺乏普遍接受的低阶客观测量之间差距的假设。我们的分析共同提供了不同时间尺度上可预测性的有限证据,尽管高阶可预测性难以可靠推断。我们得出结论,语音中的时间可预测性很可能源于多个结构层面上各自微弱的感知线索的组合,但很难精确确定。