National Institute of Informatics, 2-1-2 Hitotsubashi, Chiyoda-ku, Tokyo 101-8430, Japan.
JST, ERATO, Kawarabayashi large graph project, c/o Global Research Center for Big Data Mathematics, NII, 2-1-2 Hitotsubashi, Chiyoda-ku, Tokyo 101-8430, Japan.
Sci Rep. 2017 Jan 10;7:39275. doi: 10.1038/srep39275.
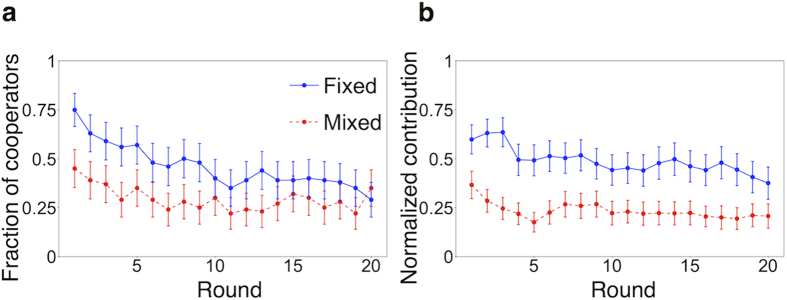
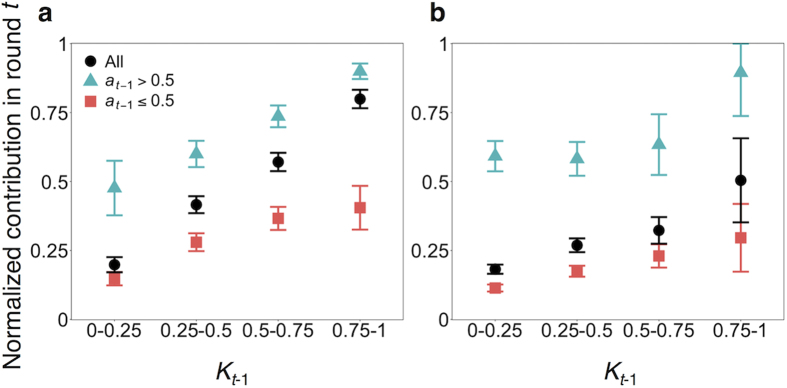
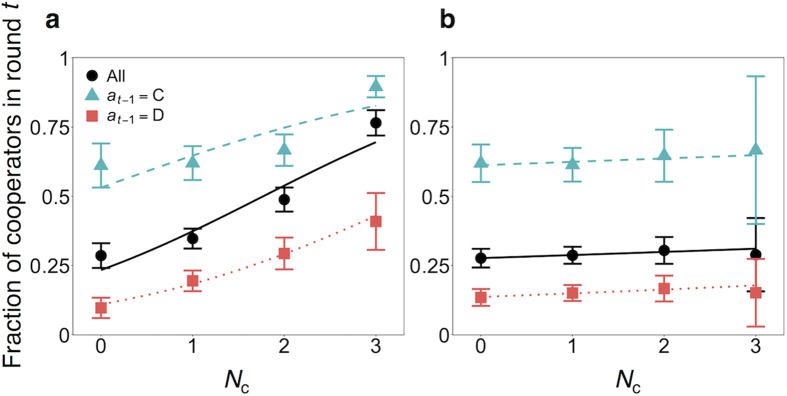
In social dilemma games, human participants often show conditional cooperation (CC) behavior or its variant called moody conditional cooperation (MCC), with which they basically tend to cooperate when many other peers have previously cooperated. Recent computational studies showed that CC and MCC behavioral patterns could be explained by reinforcement learning. In the present study, we use a repeated multiplayer prisoner's dilemma game and the repeated public goods game played by human participants to examine whether MCC is observed across different types of game and the possibility that reinforcement learning explains observed behavior. We observed MCC behavior in both games, but the MCC that we observed was different from that observed in the past experiments. In the present study, whether or not a focal participant cooperated previously affected the overall level of cooperation, instead of changing the tendency of cooperation in response to cooperation of other participants in the previous time step. We found that, across different conditions, reinforcement learning models were approximately as accurate as a MCC model in describing the experimental results. Consistent with the previous computational studies, the present results suggest that reinforcement learning may be a major proximate mechanism governing MCC behavior.
在社会困境博弈中,人类参与者通常表现出条件合作(CC)行为或其变体称为情绪化条件合作(MCC),即当许多其他同伴之前合作时,他们基本上倾向于合作。最近的计算研究表明,CC 和 MCC 行为模式可以用强化学习来解释。在本研究中,我们使用重复的多人囚徒困境博弈和人类参与者玩的重复公共物品博弈,来检验 MCC 是否在不同类型的博弈中存在,以及强化学习是否可以解释观察到的行为。我们在两种游戏中都观察到了 MCC 行为,但我们观察到的 MCC 与过去实验中观察到的不同。在本研究中,焦点参与者之前是否合作会影响整体合作水平,而不是根据前一个时间步的其他参与者的合作来改变合作的趋势。我们发现,在不同的条件下,强化学习模型在描述实验结果方面与 MCC 模型一样准确。与之前的计算研究一致,本研究结果表明,强化学习可能是支配 MCC 行为的主要近因机制。