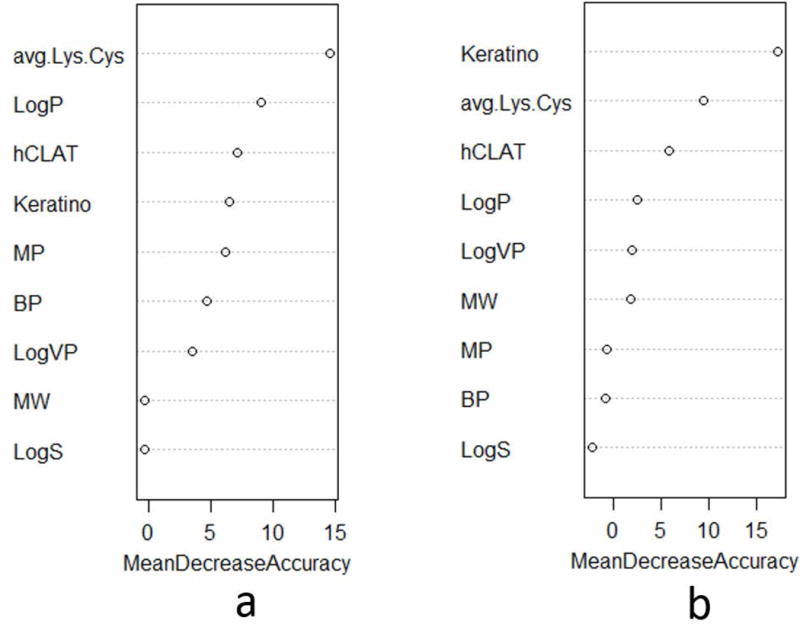
Zang Qingda, Paris Michael, Lehmann David M, Bell Shannon, Kleinstreuer Nicole, Allen David, Matheson Joanna, Jacobs Abigail, Casey Warren, Strickland Judy
ILS, Research Triangle Park, NC, 27709, USA.
EPA/NHEERL/EPHD/CIB, Research Triangle Park, NC, 27709, USA.
J Appl Toxicol. 2017 Jul;37(7):792-805. doi: 10.1002/jat.3424. Epub 2017 Jan 10.
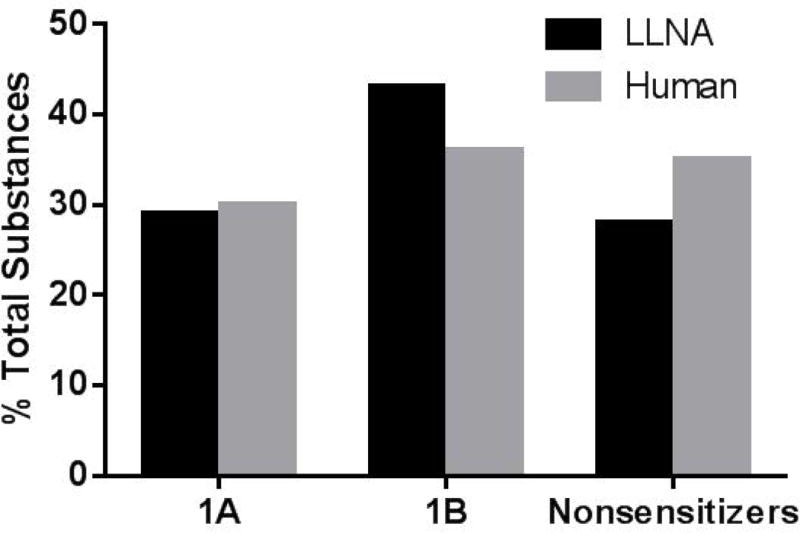
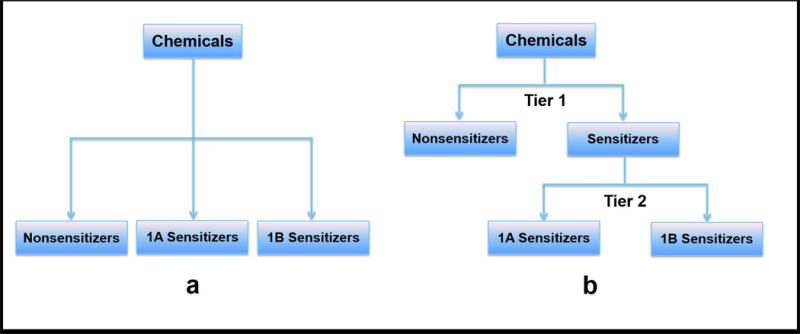
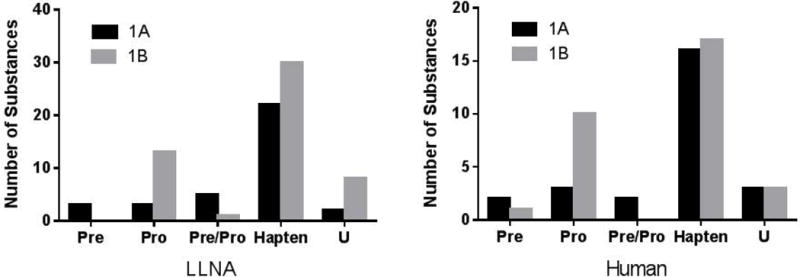
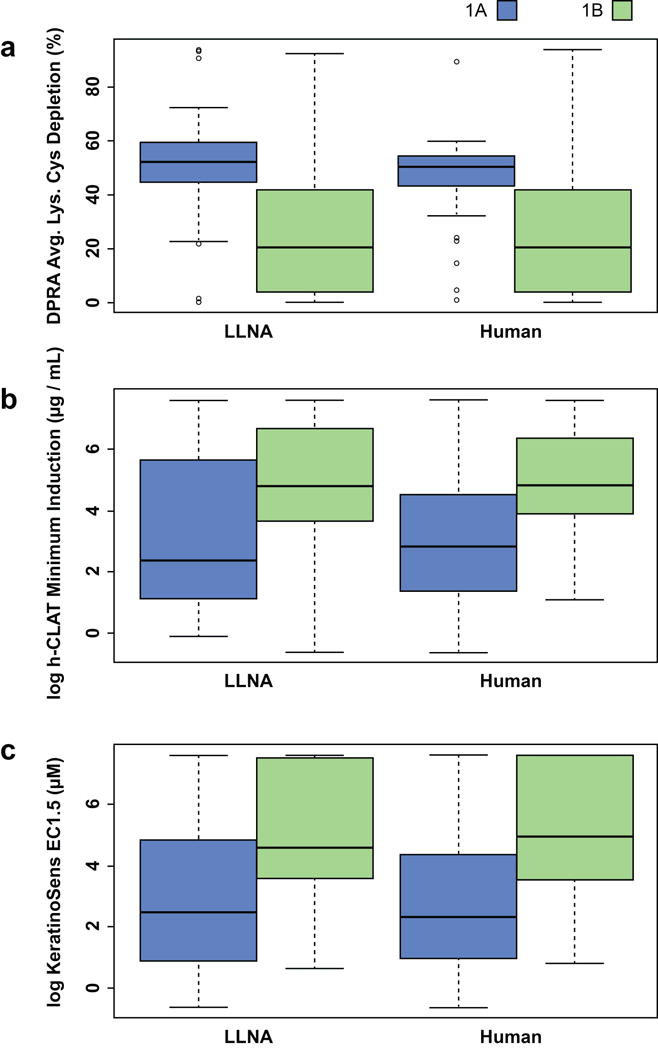
The replacement of animal use in testing for regulatory classification of skin sensitizers is a priority for US federal agencies that use data from such testing. Machine learning models that classify substances as sensitizers or non-sensitizers without using animal data have been developed and evaluated. Because some regulatory agencies require that sensitizers be further classified into potency categories, we developed statistical models to predict skin sensitization potency for murine local lymph node assay (LLNA) and human outcomes. Input variables for our models included six physicochemical properties and data from three non-animal test methods: direct peptide reactivity assay; human cell line activation test; and KeratinoSens™ assay. Models were built to predict three potency categories using four machine learning approaches and were validated using external test sets and leave-one-out cross-validation. A one-tiered strategy modeled all three categories of response together while a two-tiered strategy modeled sensitizer/non-sensitizer responses and then classified the sensitizers as strong or weak sensitizers. The two-tiered model using the support vector machine with all assay and physicochemical data inputs provided the best performance, yielding accuracy of 88% for prediction of LLNA outcomes (120 substances) and 81% for prediction of human test outcomes (87 substances). The best one-tiered model predicted LLNA outcomes with 78% accuracy and human outcomes with 75% accuracy. By comparison, the LLNA predicts human potency categories with 69% accuracy (60 of 87 substances correctly categorized). These results suggest that computational models using non-animal methods may provide valuable information for assessing skin sensitization potency. Copyright © 2017 John Wiley & Sons, Ltd.
对于使用此类测试数据的美国联邦机构而言,在皮肤致敏剂监管分类测试中替代动物实验是一项优先任务。现已开发并评估了不使用动物数据就能将物质分类为致敏剂或非致敏剂的机器学习模型。由于一些监管机构要求将致敏剂进一步分类为不同的效力类别,我们开发了统计模型来预测小鼠局部淋巴结试验(LLNA)和人体实验结果的皮肤致敏效力。我们模型的输入变量包括六种物理化学性质以及来自三种非动物测试方法的数据:直接肽反应性测定;人细胞系激活试验;以及KeratinoSens™ 测定。使用四种机器学习方法构建模型以预测三个效力类别,并使用外部测试集和留一法交叉验证进行验证。单层次策略同时对所有三类反应进行建模,而双层次策略先对致敏剂/非致敏剂反应进行建模,然后将致敏剂分类为强致敏剂或弱致敏剂。使用支持向量机并输入所有测定和物理化学数据的双层次模型表现最佳,预测LLNA结果(120种物质)的准确率为88%,预测人体测试结果(87种物质)的准确率为81%。最佳的单层次模型预测LLNA结果的准确率为78%,预测人体结果的准确率为75%。相比之下,LLNA预测人体效力类别的准确率为69%(87种物质中有60种分类正确)。这些结果表明,使用非动物方法的计算模型可能为评估皮肤致敏效力提供有价值的信息。版权所有© 2017约翰威立父子有限公司。