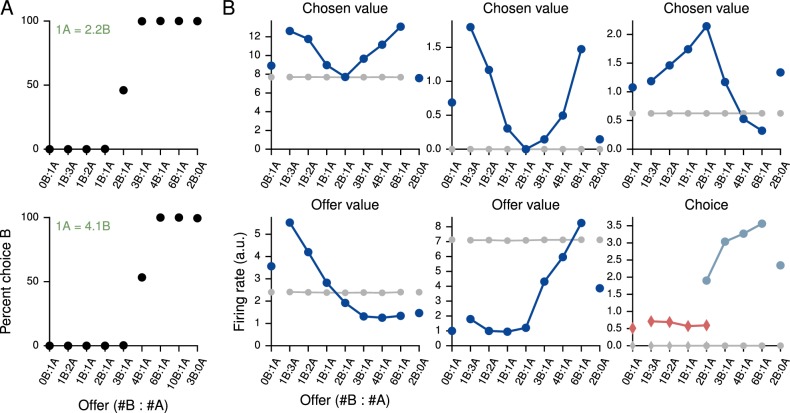
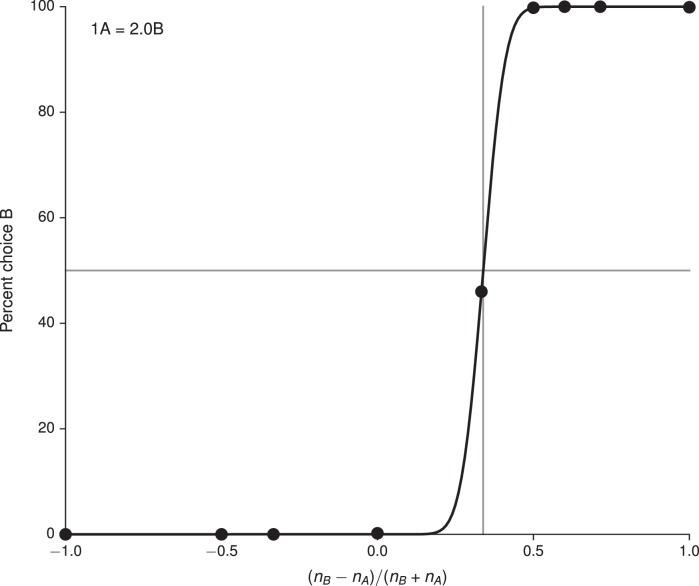
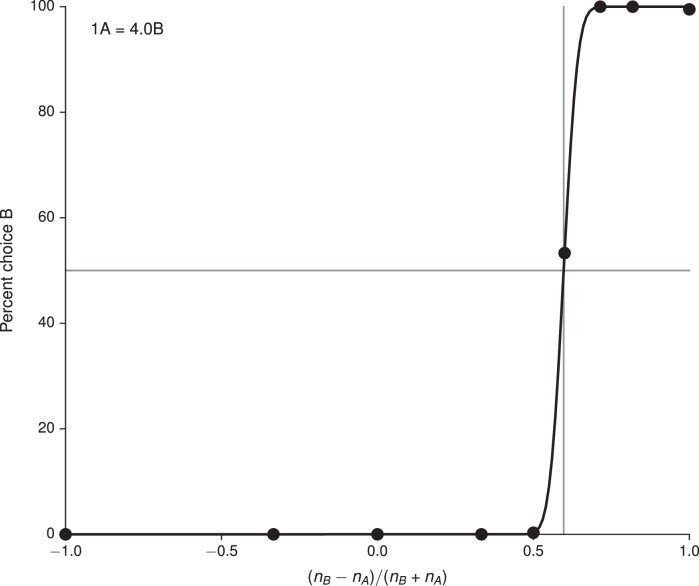
Song H Francis, Yang Guangyu R, Wang Xiao-Jing
Center for Neural Science, New York University, New York, United States.
NYU-ECNU Institute of Brain and Cognitive Science, NYU Shanghai, Shanghai, China.
Elife. 2017 Jan 13;6:e21492. doi: 10.7554/eLife.21492.
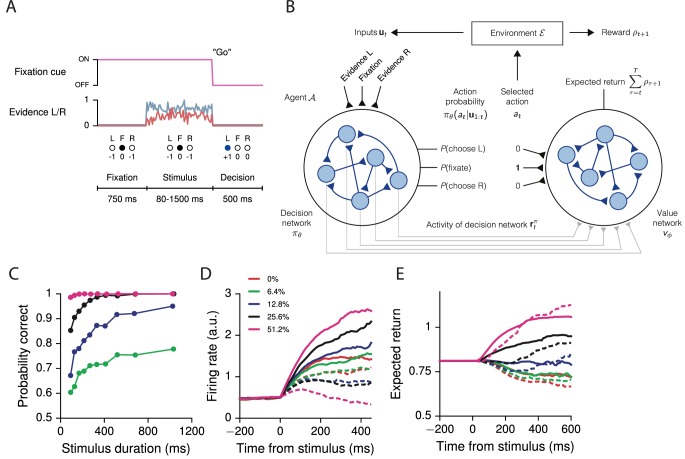
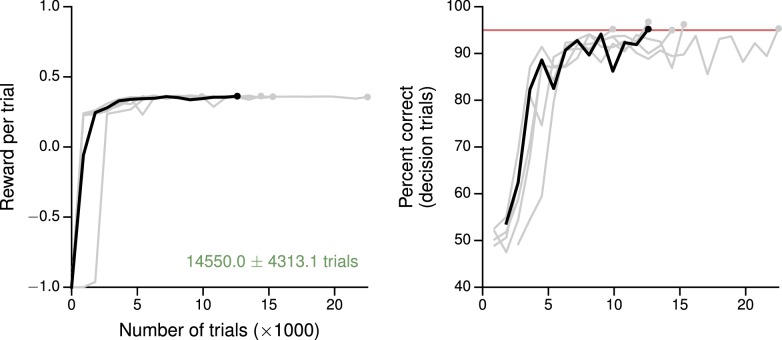
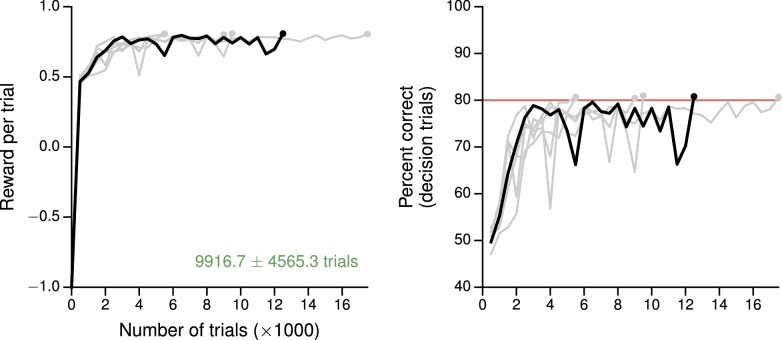
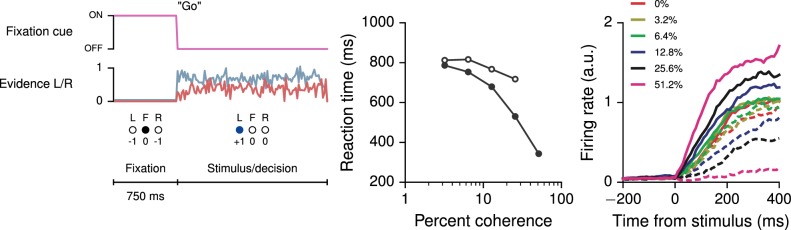
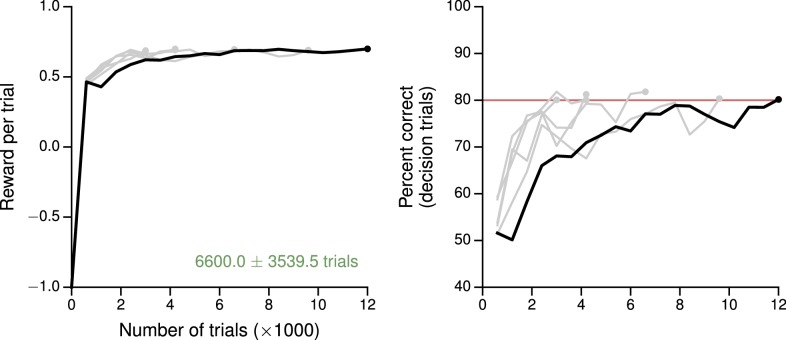
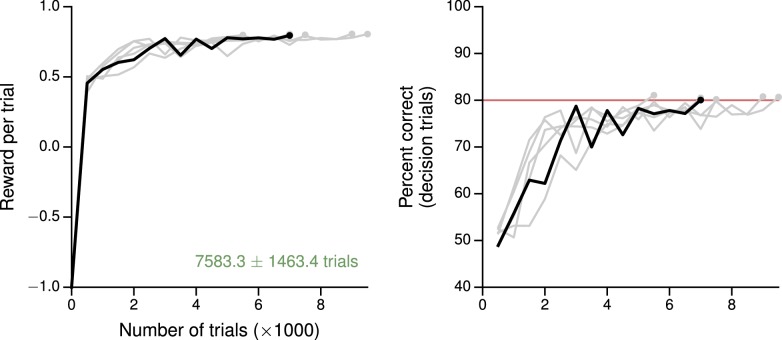
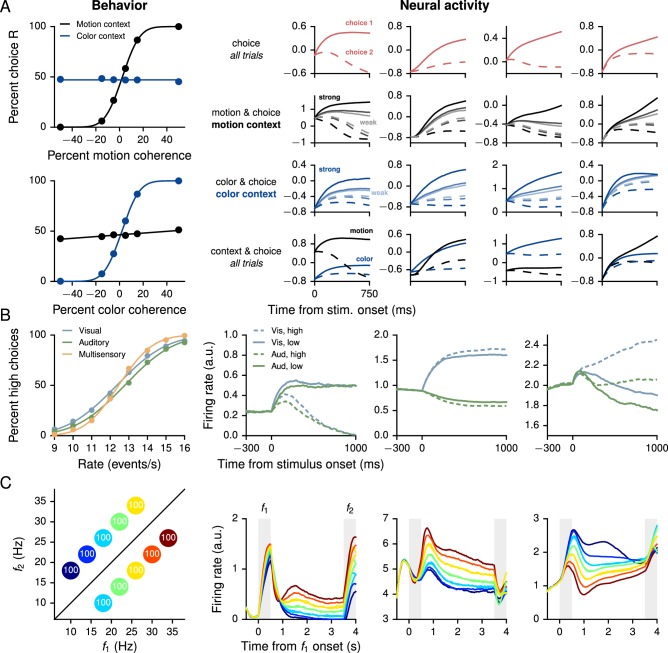
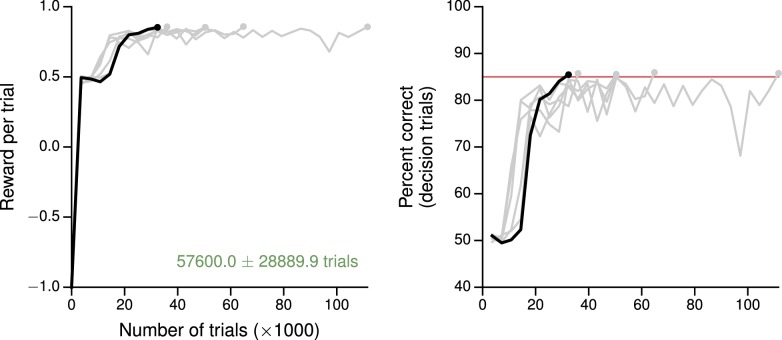
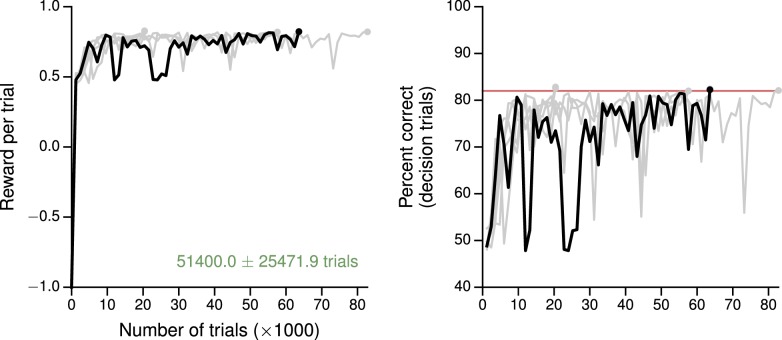
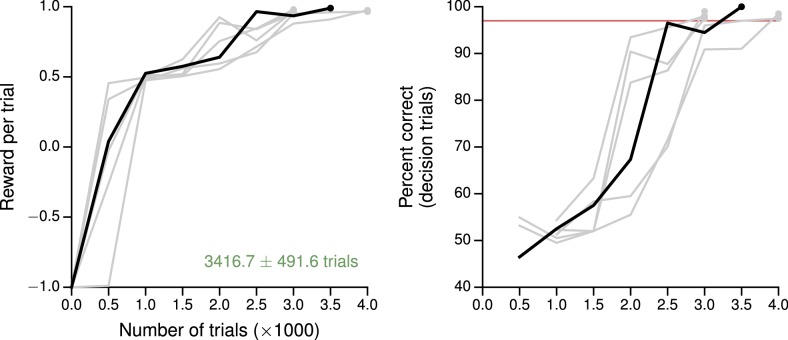
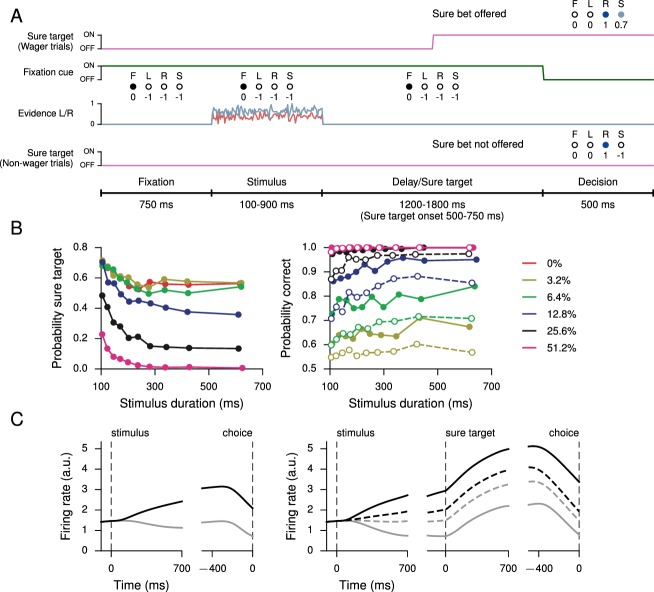
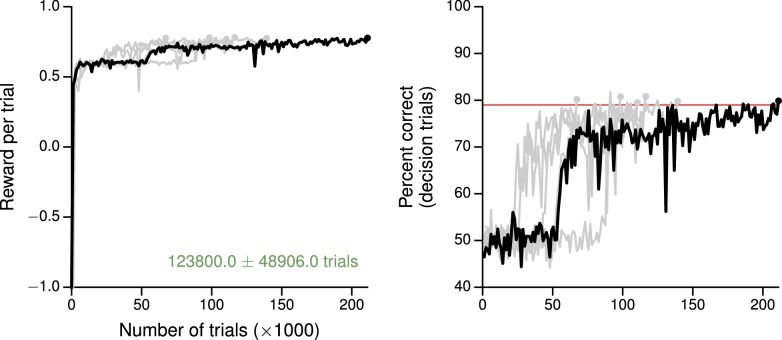
Trained neural network models, which exhibit features of neural activity recorded from behaving animals, may provide insights into the circuit mechanisms of cognitive functions through systematic analysis of network activity and connectivity. However, in contrast to the graded error signals commonly used to train networks through supervised learning, animals learn from reward feedback on definite actions through reinforcement learning. Reward maximization is particularly relevant when optimal behavior depends on an animal's internal judgment of confidence or subjective preferences. Here, we implement reward-based training of recurrent neural networks in which a value network guides learning by using the activity of the decision network to predict future reward. We show that such models capture behavioral and electrophysiological findings from well-known experimental paradigms. Our work provides a unified framework for investigating diverse cognitive and value-based computations, and predicts a role for value representation that is essential for learning, but not executing, a task.
经过训练的神经网络模型展现出从行为动物身上记录到的神经活动特征,通过对网络活动和连通性的系统分析,可能会为认知功能的神经回路机制提供见解。然而,与通常用于通过监督学习训练网络的渐变误差信号不同,动物通过强化学习从对明确行动的奖励反馈中学习。当最优行为取决于动物对信心或主观偏好的内部判断时,奖励最大化尤为重要。在此,我们实现了循环神经网络的基于奖励的训练,其中价值网络通过利用决策网络的活动来预测未来奖励来指导学习。我们表明,此类模型捕捉了来自著名实验范式的行为和电生理结果。我们的工作为研究各种认知和基于价值的计算提供了一个统一的框架,并预测了价值表征在学习而非执行任务中所起的关键作用。