Tanwar Umesh K, Pruthi Vikas, Randhawa Gursharn S
Department of Biotechnology, Indian Institute of Technology Roorkee Roorkee, India.
Front Plant Sci. 2017 Feb 2;8:91. doi: 10.3389/fpls.2017.00091. eCollection 2017.
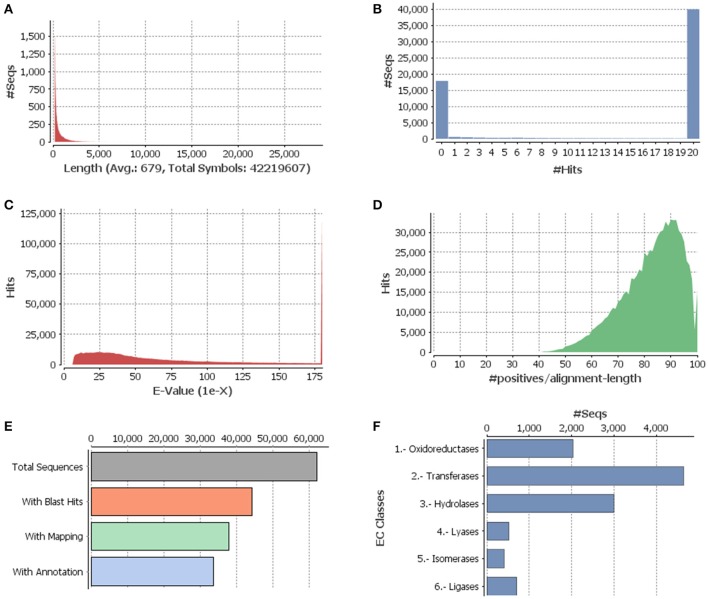
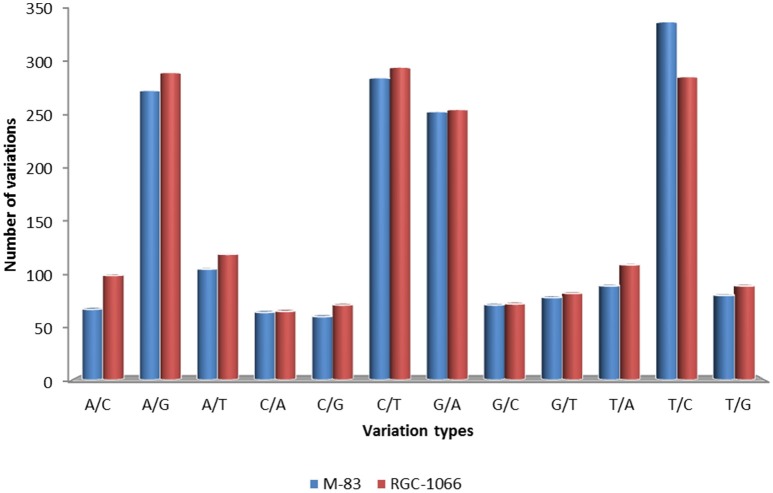
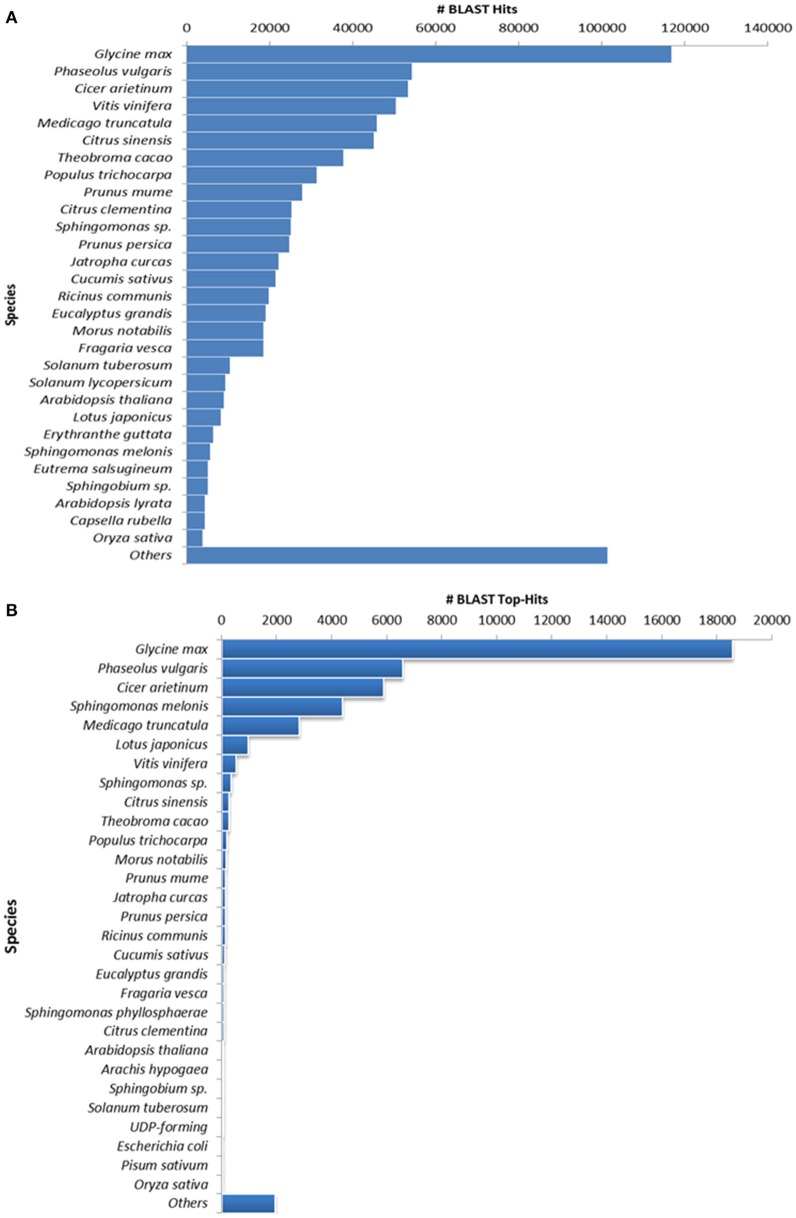
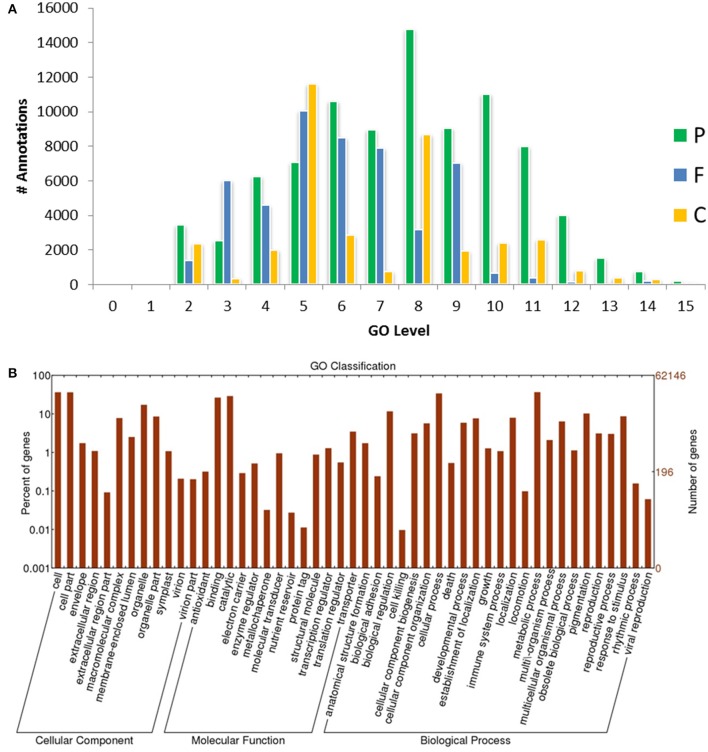
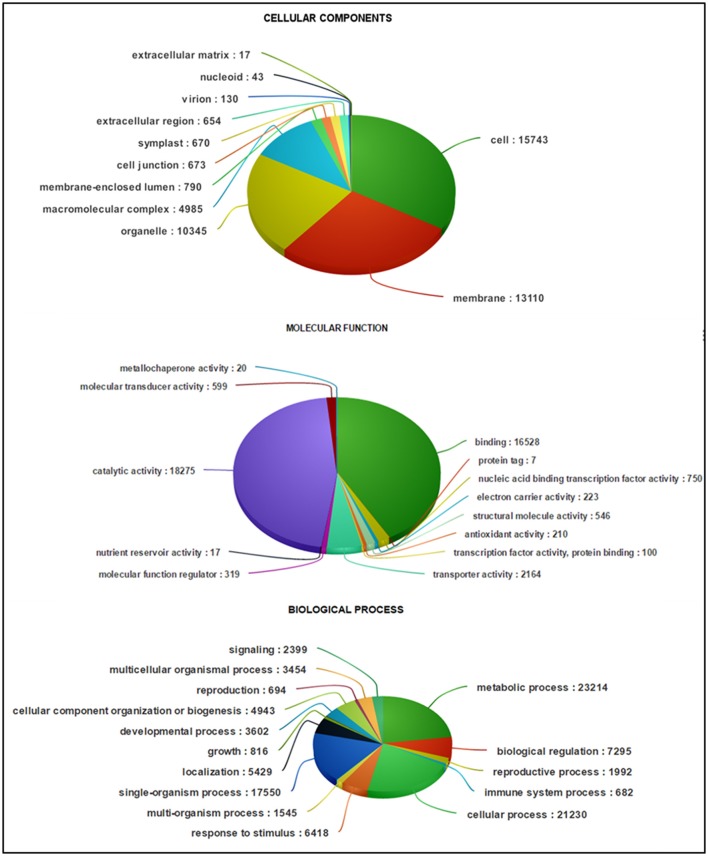
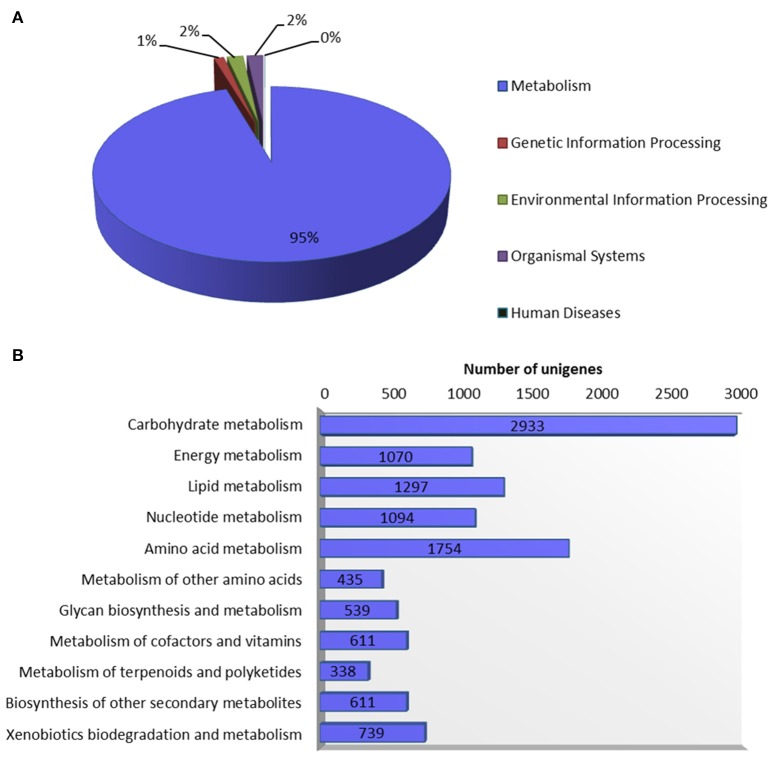
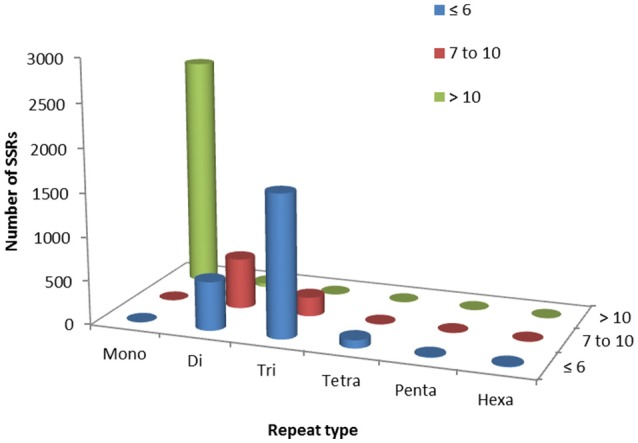
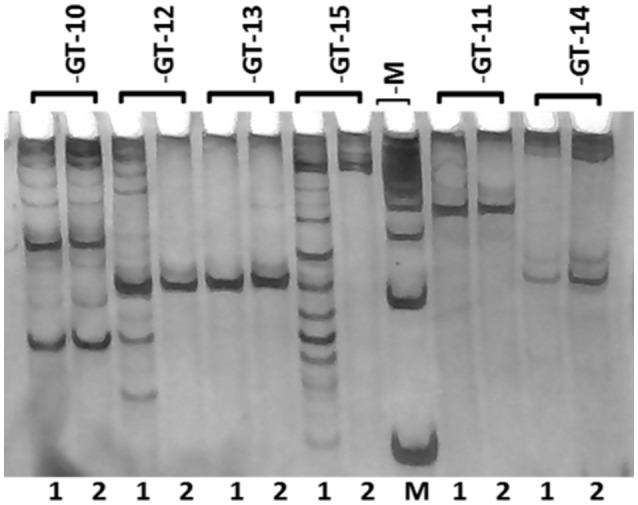
Genetic improvement in industrially important guar (, L. Taub.) crop has been hindered due to the lack of sufficient genomic or transcriptomic resources. In this study, RNA-Seq technology was employed to characterize the transcriptome of leaf tissues from two guar varieties, namely, M-83 and RGC-1066. Approximately 30 million high-quality pair-end reads of each variety generated by Illumina HiSeq platform were used for assembly by Trinity program. A total of 62,146 non-redundant unigenes with an average length of 679 bp were obtained. The quality assessment of assembled unigenes revealed 87.50% of complete and 97.18% partial core eukaryotic genes (CEGs). Sequence similarity analyses and annotation of the unigenes against non-redundant protein (Nr) and Gene Ontology (GO) databases identified 175,882 GO annotations. A total of 11,308 guar unigenes were annotated with various enzyme codes (EC) and categorized in six categories with 55 subclasses. The annotation of biochemical pathways resulted in a total of 11,971 unigenes assigned with 145 KEGG maps and 1759 enzyme codes. The species distribution analysis of the unigenes showed highest similarity with genes. A total of 5773 potential simple sequence repeats (SSRs) and 3594 high-quality single nucleotide polymorphisms (SNPs) were identified. Out of 20 randomly selected SSRs for wet laboratory validation, 13 showed consistent PCR amplification in both guar varieties. studies identified 145 polymorphic SSR markers in two varieties. To the best of our knowledge, this is the first report on transcriptome analysis and SNPs identification in guar till date.
由于缺乏足够的基因组或转录组资源,具有重要工业价值的瓜尔豆(Cyamopsis tetragonoloba (L.) Taub.)作物的遗传改良受到了阻碍。在本研究中,采用RNA测序技术对两个瓜尔豆品种M-83和RGC-1066的叶片组织转录组进行了表征。利用Illumina HiSeq平台为每个品种生成了约3000万个高质量的双末端 reads,用于通过Trinity程序进行组装。共获得了62146个非冗余单基因,平均长度为679 bp。对组装的单基因进行质量评估,发现87.50%的基因是完整的,97.18%的基因是部分核心真核基因(CEGs)。通过对单基因与非冗余蛋白质(Nr)和基因本体(GO)数据库进行序列相似性分析和注释,确定了175882个GO注释。共有11308个瓜尔豆单基因被标注了各种酶代码(EC),并分为6类55个亚类。对生化途径的注释共产生了11971个单基因,这些单基因被分配到145个KEGG图谱和1759个酶代码中。单基因的物种分布分析显示与鹰嘴豆属基因的相似性最高。共鉴定出5773个潜在的简单序列重复(SSR)和3594个高质量的单核苷酸多态性(SNP)。在随机选择的20个用于湿实验室验证的SSR中,有13个在两个瓜尔豆品种中均显示出一致的PCR扩增。研究在两个品种中鉴定出145个多态性SSR标记。据我们所知,这是迄今为止关于瓜尔豆转录组分析和SNP鉴定的第一份报告。