Starkweather Clara Kwon, Babayan Benedicte M, Uchida Naoshige, Gershman Samuel J
Center for Brain Science, Department of Molecular and Cellular Biology, Harvard University, Cambridge, Massachusetts, USA.
Center for Brain Science, Department of Psychology, Harvard University, Cambridge, Massachusetts, USA.
Nat Neurosci. 2017 Apr;20(4):581-589. doi: 10.1038/nn.4520. Epub 2017 Mar 6.
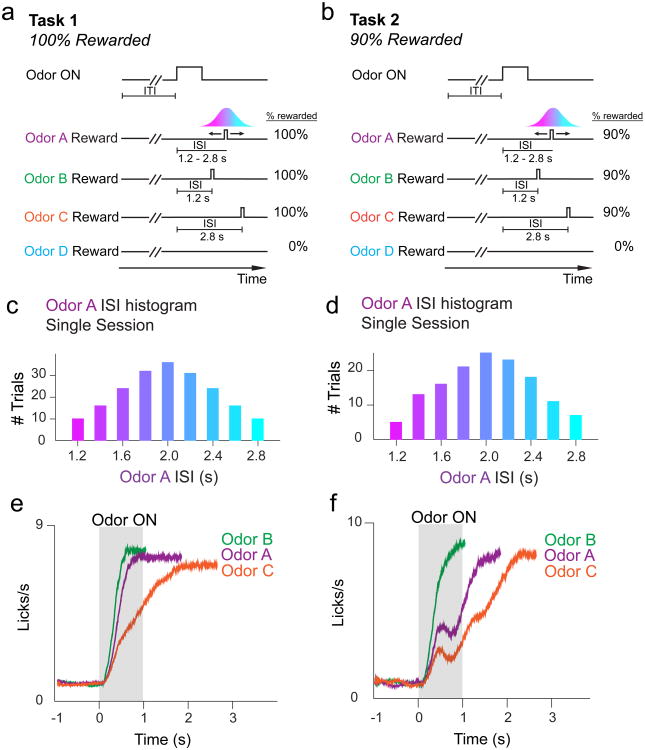
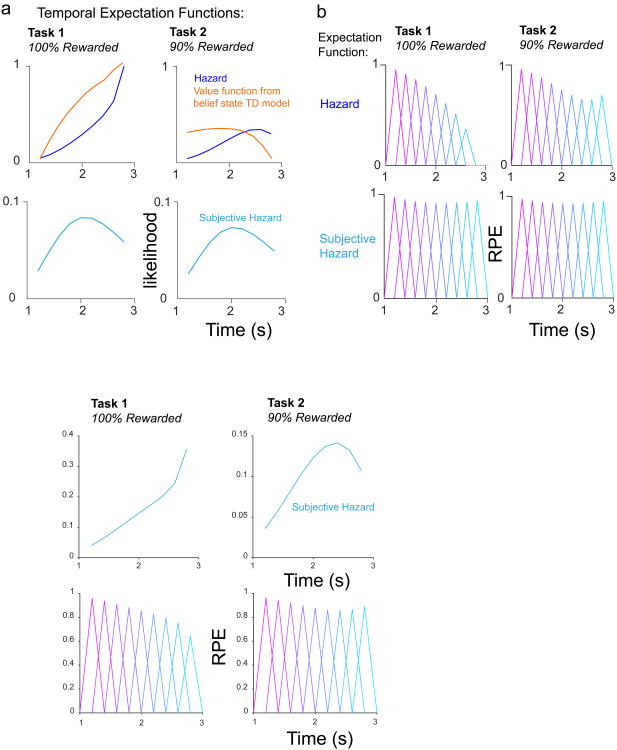
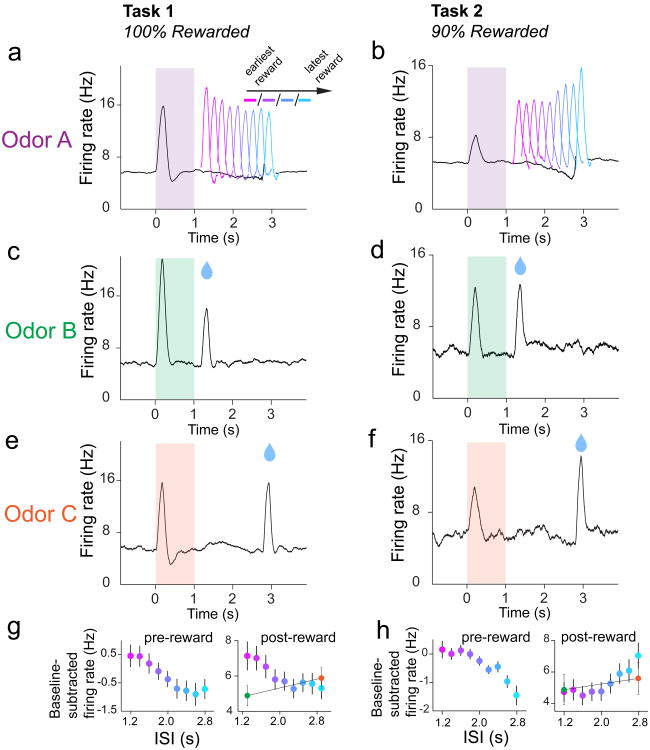
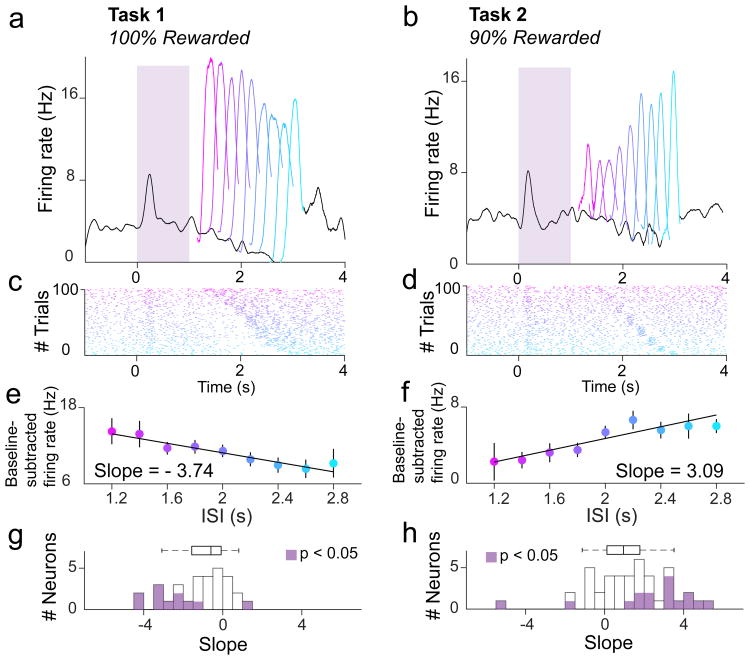
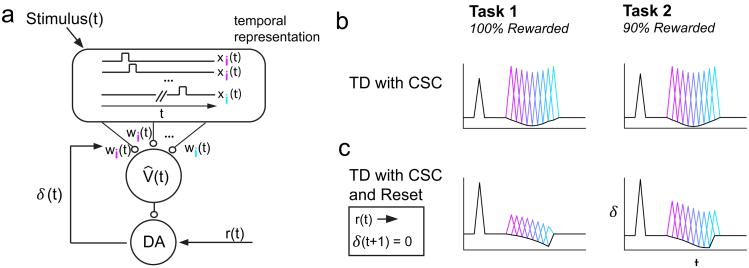
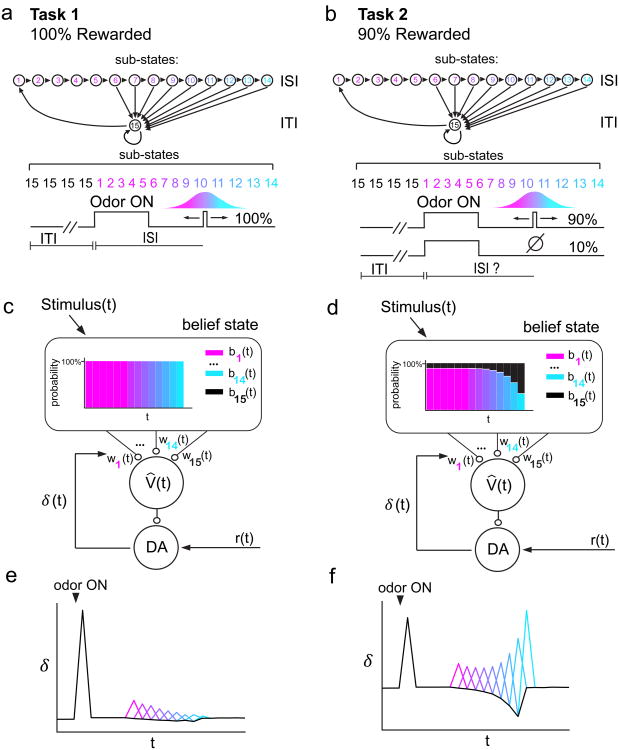
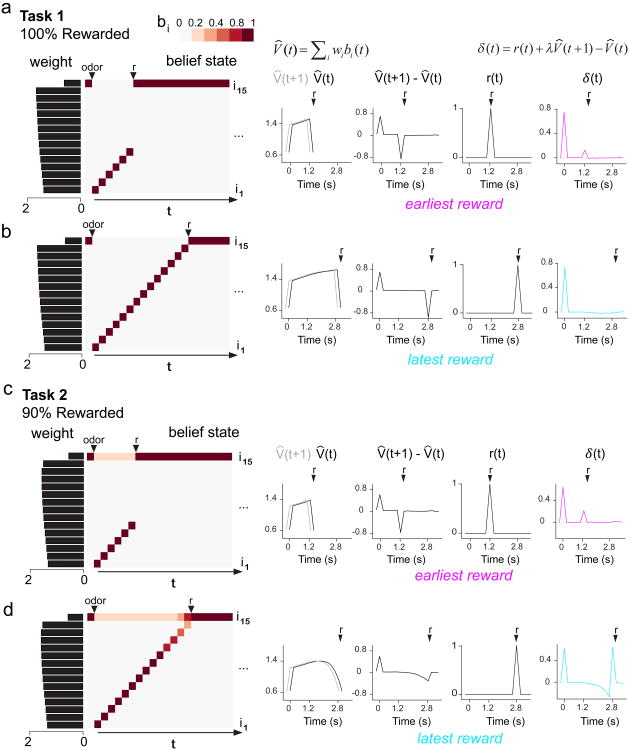
Midbrain dopamine neurons signal reward prediction error (RPE), or actual minus expected reward. The temporal difference (TD) learning model has been a cornerstone in understanding how dopamine RPEs could drive associative learning. Classically, TD learning imparts value to features that serially track elapsed time relative to observable stimuli. In the real world, however, sensory stimuli provide ambiguous information about the hidden state of the environment, leading to the proposal that TD learning might instead compute a value signal based on an inferred distribution of hidden states (a 'belief state'). Here we asked whether dopaminergic signaling supports a TD learning framework that operates over hidden states. We found that dopamine signaling showed a notable difference between two tasks that differed only with respect to whether reward was delivered in a deterministic manner. Our results favor an associative learning rule that combines cached values with hidden-state inference.
中脑多巴胺神经元发出奖励预测误差(RPE)信号,即实际奖励减去预期奖励。时间差(TD)学习模型一直是理解多巴胺RPE如何驱动联想学习的基石。传统上,TD学习赋予与可观察刺激相关的、按顺序跟踪经过时间的特征以价值。然而,在现实世界中,感觉刺激提供了关于环境隐藏状态的模糊信息,这导致有人提出TD学习可能反而基于隐藏状态的推断分布(“信念状态”)来计算价值信号。在这里,我们研究了多巴胺能信号是否支持在隐藏状态上运行的TD学习框架。我们发现,多巴胺信号在两个仅在奖励是否以确定性方式发放方面有所不同的任务之间表现出显著差异。我们的结果支持一种将缓存值与隐藏状态推断相结合的联想学习规则。