Namjoshi Sanjeev V, Raab-Graham Kimberly F
Center for Learning and Memory, The University of Texas at Austin, AustinTX, USA; Institute for Cellular and Molecular Biology, The University of Texas at Austin, AustinTX, USA.
Center for Learning and Memory, The University of Texas at Austin, AustinTX, USA; Institute for Cellular and Molecular Biology, The University of Texas at Austin, AustinTX, USA; Department of Physiology and Pharmacology, Wake Forest Health Sciences, Medical Center Boulevard, Winston-SalemNC, USA.
Front Mol Neurosci. 2017 Feb 24;10:45. doi: 10.3389/fnmol.2017.00045. eCollection 2017.
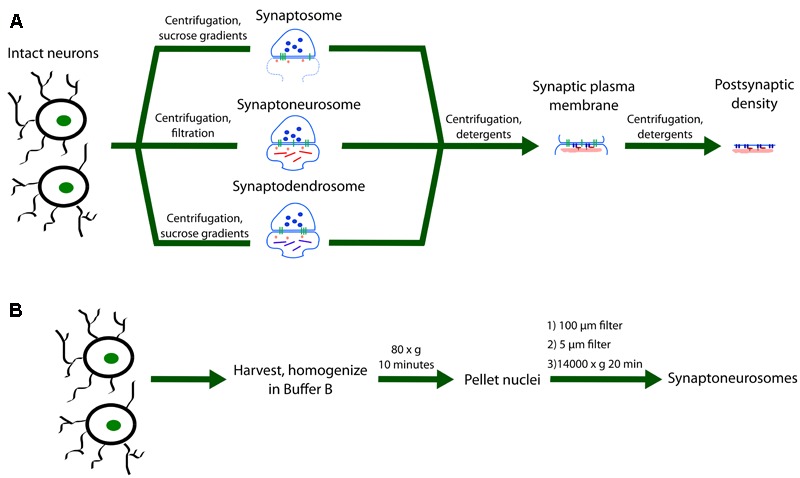
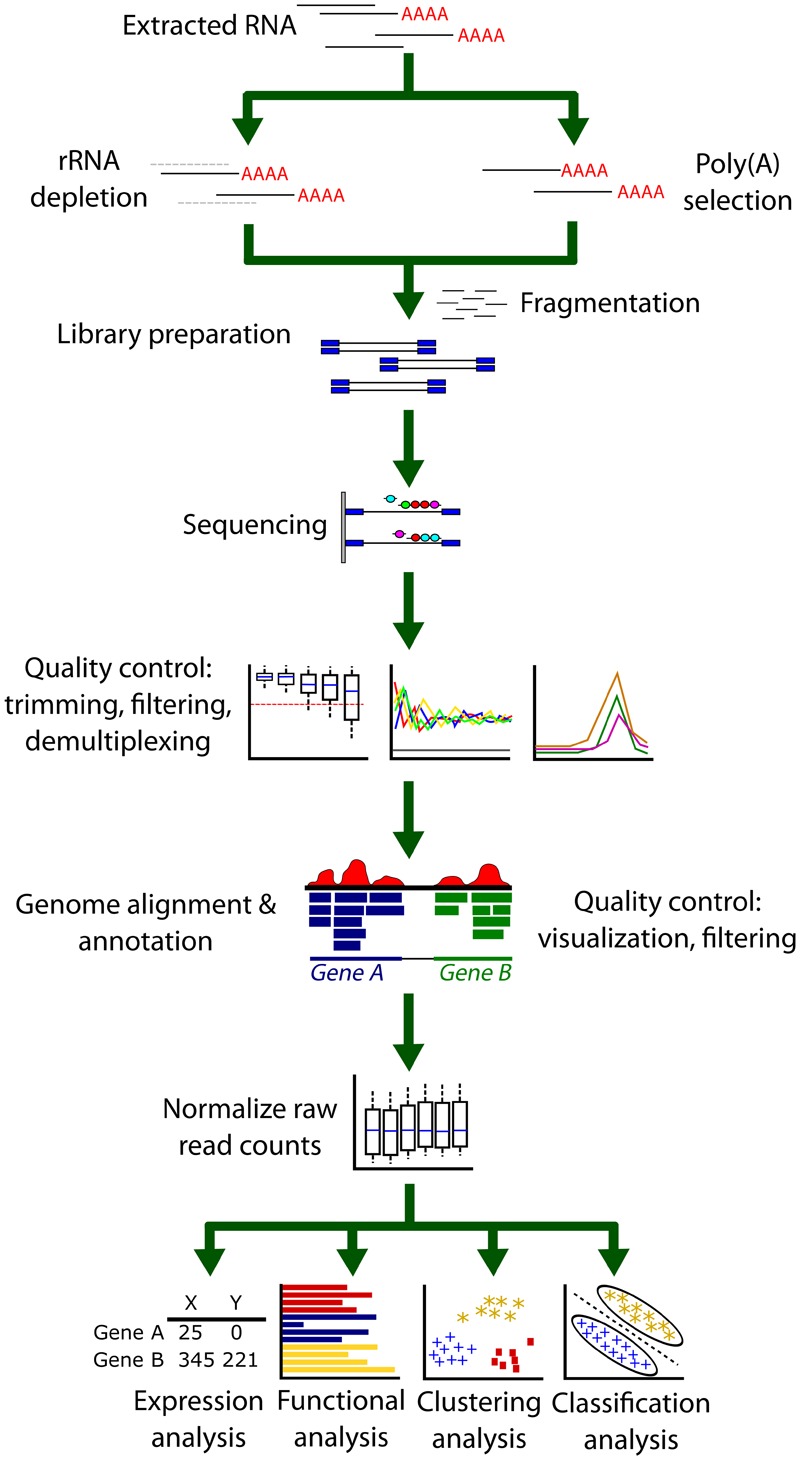
In the last decade, bioinformatic analyses of high-throughput proteomics and transcriptomics data have enabled researchers to gain insight into the molecular networks that may underlie lasting changes in synaptic efficacy. Development and utilization of these techniques have advanced the field of learning and memory significantly. It is now possible to move from the study of activity-dependent changes of a single protein to modeling entire network changes that require local protein synthesis. This data revolution has necessitated the development of alternative computational and statistical techniques to analyze and understand the patterns contained within. Thus, the focus of this review is to provide a synopsis of the journey and evolution toward big data techniques to address still unanswered questions regarding how synapses are modified to strengthen neuronal circuits. We first review the seminal studies that demonstrated the pivotal role played by local mRNA translation as the mechanism underlying the enhancement of enduring synaptic activity. In the interest of those who are new to the field, we provide a brief overview of molecular biology and biochemical techniques utilized for sample preparation to identify locally translated proteins using RNA sequencing and proteomics, as well as the computational approaches used to analyze these data. While many mRNAs have been identified, few have been shown to be locally synthesized. To this end, we review techniques currently being utilized to visualize new protein synthesis, a task that has proven to be the most difficult aspect of the field. Finally, we provide examples of future applications to test the physiological relevance of locally synthesized proteins identified by big data approaches.
在过去十年中,对高通量蛋白质组学和转录组学数据的生物信息学分析使研究人员能够深入了解可能构成突触效能持久变化基础的分子网络。这些技术的开发和应用极大地推动了学习与记忆领域的发展。现在,有可能从研究单个蛋白质的活性依赖性变化转向对需要局部蛋白质合成的整个网络变化进行建模。这场数据革命促使人们开发替代的计算和统计技术,以分析和理解其中包含的模式。因此,本综述的重点是概述在大数据技术方面的历程和发展,以解决关于突触如何被修饰以强化神经回路的仍未解答的问题。我们首先回顾一些开创性研究,这些研究证明了局部mRNA翻译作为增强持久突触活动的机制所起的关键作用。为了让该领域的新手有所了解,我们简要概述了用于样本制备的分子生物学和生化技术,这些技术利用RNA测序和蛋白质组学来鉴定局部翻译的蛋白质,以及用于分析这些数据的计算方法。虽然已经鉴定出许多mRNA,但很少有被证明是在局部合成的。为此,我们回顾目前用于可视化新蛋白质合成的技术,这一任务已被证明是该领域最困难的方面。最后,我们提供未来应用的示例,以测试通过大数据方法鉴定的局部合成蛋白质的生理相关性。