Capuccini Marco, Ahmed Laeeq, Schaal Wesley, Laure Erwin, Spjuth Ola
Department of Information Technology, Uppsala University, Box 337, 75105 Uppsala, Sweden.
Department of Pharmaceutical Biosciences, Uppsala University, Box 591, 75124 Uppsala, Sweden.
J Cheminform. 2017 Mar 6;9:15. doi: 10.1186/s13321-017-0204-4. eCollection 2017.
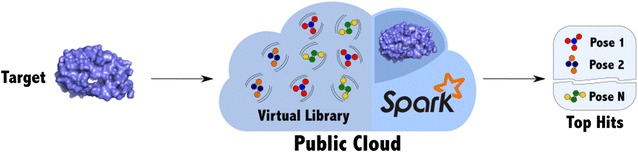
Structure-based virtual screening is an in-silico method to screen a target receptor against a virtual molecular library. Applying docking-based screening to large molecular libraries can be computationally expensive, however it constitutes a trivially parallelizable task. Most of the available parallel implementations are based on message passing interface, relying on low failure rate hardware and fast network connection. Google's MapReduce revolutionized large-scale analysis, enabling the processing of massive datasets on commodity hardware and cloud resources, providing transparent scalability and fault tolerance at the software level. Open source implementations of MapReduce include Apache Hadoop and the more recent Apache Spark.
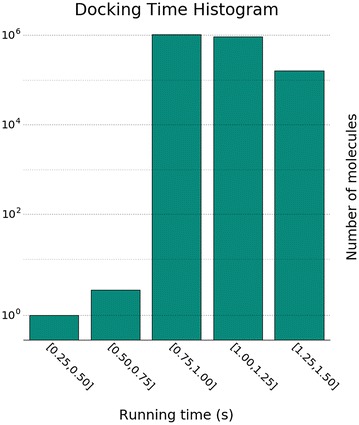
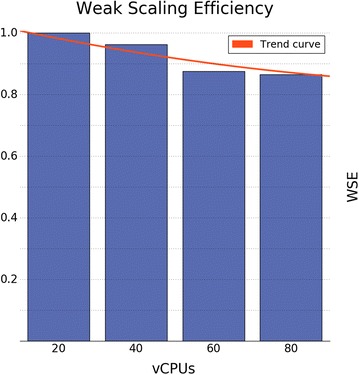
We developed a method to run existing docking-based screening software on distributed cloud resources, utilizing the MapReduce approach. We benchmarked our method, which is implemented in Apache Spark, docking a publicly available target receptor against [Formula: see text]2.2 M compounds. The performance experiments show a good parallel efficiency (87%) when running in a public cloud environment.
Our method enables parallel Structure-based virtual screening on public cloud resources or commodity computer clusters. The degree of scalability that we achieve allows for trying out our method on relatively small libraries first and then to scale to larger libraries. Our implementation is named Spark-VS and it is freely available as open source from GitHub (https://github.com/mcapuccini/spark-vs).Graphical abstract.
基于结构的虚拟筛选是一种针对虚拟分子库筛选目标受体的计算机模拟方法。将基于对接的筛选应用于大型分子库在计算上可能成本高昂,但其构成了一项极易并行化的任务。大多数现有的并行实现基于消息传递接口,依赖低故障率硬件和快速网络连接。谷歌的MapReduce彻底改变了大规模分析,能够在商用硬件和云资源上处理海量数据集,在软件层面提供透明的可扩展性和容错能力。MapReduce的开源实现包括Apache Hadoop和更新的Apache Spark。
我们开发了一种利用MapReduce方法在分布式云资源上运行现有基于对接的筛选软件的方法。我们对我们在Apache Spark中实现的方法进行了基准测试,将一个公开可用的目标受体与220万个化合物进行对接。性能实验表明,在公共云环境中运行时具有良好的并行效率(87%)。
我们的方法能够在公共云资源或商用计算机集群上进行基于结构的并行虚拟筛选。我们实现的可扩展性程度允许先在相对较小的库上试用我们的方法,然后再扩展到更大的库。我们的实现名为Spark-VS,可从GitHub(https://github.com/mcapuccini/spark-vs)作为开源软件免费获取。图形摘要。