Lienemann Brianna A, Unger Jennifer B, Cruz Tess Boley, Chu Kar-Hai
Department of Preventive Medicine, Keck School of Medicine, University of Southern California, Los Angeles, CA, United States.
J Med Internet Res. 2017 Mar 31;19(3):e91. doi: 10.2196/jmir.7022.
As Twitter has grown in popularity to 313 million monthly active users, researchers have increasingly been using it as a data source for tobacco-related research.
The objective of this systematic review was to assess the methodological approaches of categorically coded tobacco Twitter data and make recommendations for future studies.
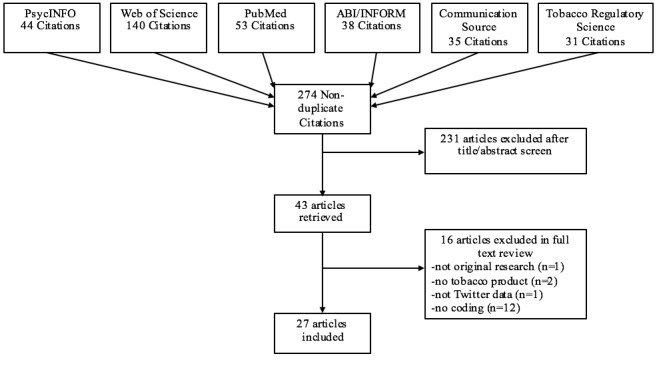
Data sources included PsycINFO, Web of Science, PubMed, ABI/INFORM, Communication Source, and Tobacco Regulatory Science. Searches were limited to peer-reviewed journals and conference proceedings in English from January 2006 to July 2016. The initial search identified 274 articles using a Twitter keyword and a tobacco keyword. One coder reviewed all abstracts and identified 27 articles that met the following inclusion criteria: (1) original research, (2) focused on tobacco or a tobacco product, (3) analyzed Twitter data, and (4) coded Twitter data categorically. One coder extracted data collection and coding methods.
E-cigarettes were the most common type of Twitter data analyzed, followed by specific tobacco campaigns. The most prevalent data sources were Gnip and Twitter's Streaming application programming interface (API). The primary methods of coding were hand-coding and machine learning. The studies predominantly coded for relevance, sentiment, theme, user or account, and location of user.
Standards for data collection and coding should be developed to be able to more easily compare and replicate tobacco-related Twitter results. Additional recommendations include the following: sample Twitter's databases multiple times, make a distinction between message attitude and emotional tone for sentiment, code images and URLs, and analyze user profiles. Being relatively novel and widely used among adolescents and black and Hispanic individuals, Twitter could provide a rich source of tobacco surveillance data among vulnerable populations.
随着推特的用户数量日益增长,每月活跃用户达3.13亿,研究人员越来越多地将其用作烟草相关研究的数据源。
本系统评价的目的是评估对推特上烟草数据进行分类编码的方法,并为未来研究提出建议。
数据来源包括心理学文摘数据库(PsycINFO)、科学引文索引(Web of Science)、医学期刊数据库(PubMed)、商业经济管理数据库(ABI/INFORM)、传播源数据库(Communication Source)和烟草监管科学数据库。搜索范围限于2006年1月至2016年7月期间以英文发表的同行评审期刊和会议论文。初步搜索通过使用推特关键词和烟草关键词识别出274篇文章。一名编码人员审阅了所有摘要,并确定了27篇符合以下纳入标准的文章:(1)原创研究;(2)聚焦于烟草或烟草制品;(3)分析推特数据;(4)对推特数据进行分类编码。一名编码人员提取了数据收集和编码方法。
电子烟是分析的推特数据中最常见的类型,其次是特定的烟草宣传活动。最普遍的数据来源是Gnip和推特的流式应用程序编程接口(API)。编码的主要方法是手工编码和机器学习。这些研究主要针对相关性、情感、主题、用户或账户以及用户位置进行编码。
应制定数据收集和编码标准,以便更轻松地比较和复制与烟草相关的推特研究结果。其他建议包括:多次对推特数据库进行采样;区分情感方面的信息态度和情感基调;对图像和网址进行编码;分析用户资料。推特相对新颖且在青少年以及黑人和西班牙裔人群中广泛使用,它可以为弱势群体提供丰富的烟草监测数据来源。