Kim Yoonsang, Huang Jidong, Emery Sherry
Health Media Collaboratory, Institute for Health Research and Policy, University of Illinois at Chicago, Chicago, IL, United States.
J Med Internet Res. 2016 Feb 26;18(2):e41. doi: 10.2196/jmir.4738.
Social media have transformed the communications landscape. People increasingly obtain news and health information online and via social media. Social media platforms also serve as novel sources of rich observational data for health research (including infodemiology, infoveillance, and digital disease detection detection). While the number of studies using social data is growing rapidly, very few of these studies transparently outline their methods for collecting, filtering, and reporting those data. Keywords and search filters applied to social data form the lens through which researchers may observe what and how people communicate about a given topic. Without a properly focused lens, research conclusions may be biased or misleading. Standards of reporting data sources and quality are needed so that data scientists and consumers of social media research can evaluate and compare methods and findings across studies.
We aimed to develop and apply a framework of social media data collection and quality assessment and to propose a reporting standard, which researchers and reviewers may use to evaluate and compare the quality of social data across studies.
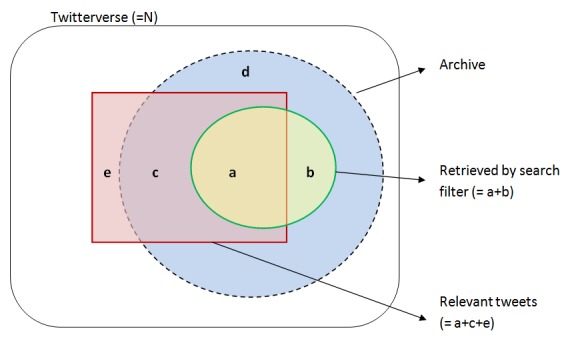
We propose a conceptual framework consisting of three major steps in collecting social media data: develop, apply, and validate search filters. This framework is based on two criteria: retrieval precision (how much of retrieved data is relevant) and retrieval recall (how much of the relevant data is retrieved). We then discuss two conditions that estimation of retrieval precision and recall rely on--accurate human coding and full data collection--and how to calculate these statistics in cases that deviate from the two ideal conditions. We then apply the framework on a real-world example using approximately 4 million tobacco-related tweets collected from the Twitter firehose.
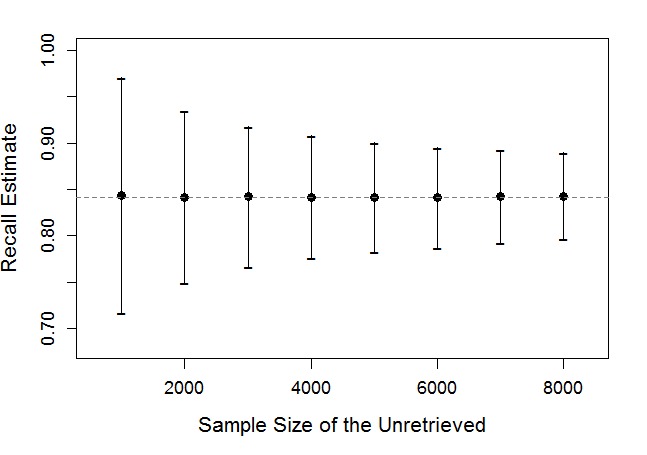
We developed and applied a search filter to retrieve e-cigarette-related tweets from the archive based on three keyword categories: devices, brands, and behavior. The search filter retrieved 82,205 e-cigarette-related tweets from the archive and was validated. Retrieval precision was calculated above 95% in all cases. Retrieval recall was 86% assuming ideal conditions (no human coding errors and full data collection), 75% when unretrieved messages could not be archived, 86% assuming no false negative errors by coders, and 93% allowing both false negative and false positive errors by human coders.
This paper sets forth a conceptual framework for the filtering and quality evaluation of social data that addresses several common challenges and moves toward establishing a standard of reporting social data. Researchers should clearly delineate data sources, how data were accessed and collected, and the search filter building process and how retrieval precision and recall were calculated. The proposed framework can be adapted to other public social media platforms.
社交媒体改变了通信格局。人们越来越多地通过网络和社交媒体获取新闻和健康信息。社交媒体平台也成为健康研究(包括信息流行病学、信息监测和数字疾病检测)丰富观测数据的新来源。虽然使用社交数据的研究数量正在迅速增长,但这些研究中很少有透明地概述其收集、筛选和报告这些数据的方法。应用于社交数据的关键词和搜索过滤器构成了研究人员观察人们就给定主题进行何种交流以及如何交流的视角。如果没有一个聚焦得当的视角,研究结论可能会有偏差或产生误导。因此需要数据来源和质量的报告标准,以便数据科学家和社交媒体研究的使用者能够评估和比较各项研究的方法及结果。
我们旨在开发并应用一个社交媒体数据收集和质量评估框架,并提出一项报告标准,研究人员和评审人员可据此评估和比较各项研究中社交数据的质量。
我们提出一个概念框架,其中包括收集社交媒体数据的三个主要步骤:开发、应用和验证搜索过滤器。该框架基于两个标准:检索精度(检索到的数据中有多少是相关的)和检索召回率(检索到的相关数据有多少)。然后我们讨论了检索精度和召回率估计所依赖的两个条件——准确的人工编码和完整的数据收集,以及在偏离这两个理想条件的情况下如何计算这些统计数据。然后我们将该框架应用于一个实际例子,使用从Twitter实时数据流中收集的约400万条与烟草相关的推文。
我们开发并应用了一个搜索过滤器,根据设备、品牌和行为这三个关键词类别,从存档中检索与电子烟相关的推文。该搜索过滤器从存档中检索到82,205条与电子烟相关的推文,并经过了验证。在所有情况下,检索精度计算结果均高于95%。在理想条件下(无人工编码错误且数据收集完整),检索召回率为86%;当未检索到的消息无法存档时,召回率为75%;假设编码人员无假阴性错误时,召回率为86%;允许人工编码人员同时存在假阴性和假阳性错误时,召回率为93%。
本文提出了一个用于社交数据筛选和质量评估的概念框架,该框架解决了几个常见挑战,并朝着建立社交数据报告标准迈进。研究人员应清晰地描述数据来源、数据的获取和收集方式、搜索过滤器的构建过程以及检索精度和召回率的计算方法。所提出的框架可适用于其他公共社交媒体平台。