College of Computer and Information Science, Southwest University, Chongqing, China.
Sci Rep. 2017 Apr 21;7(1):1046. doi: 10.1038/s41598-017-01064-0.
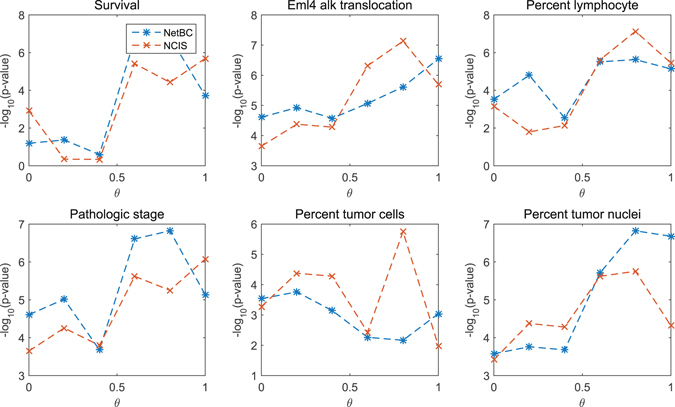
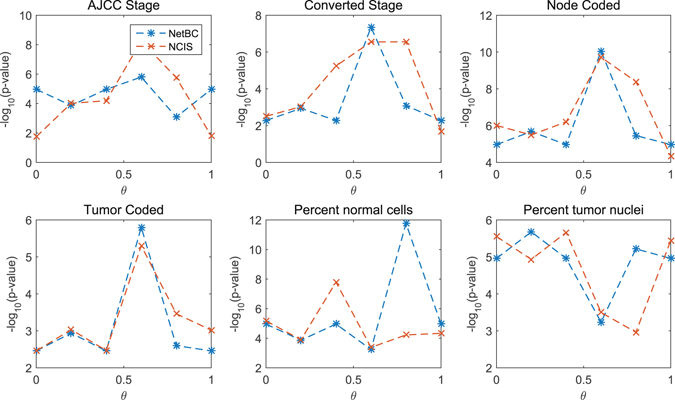
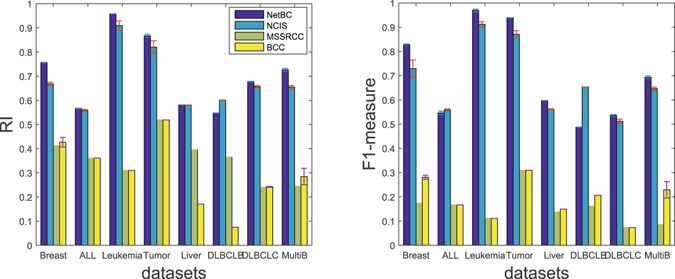
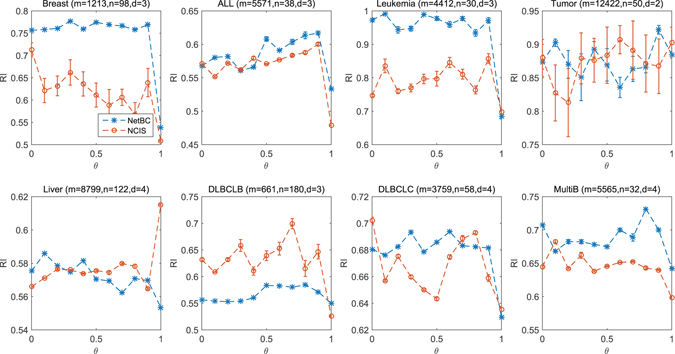
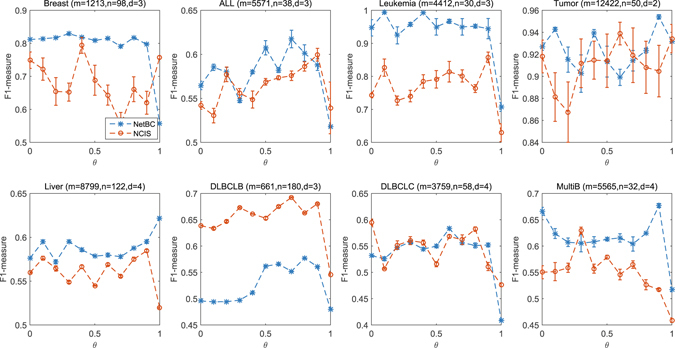
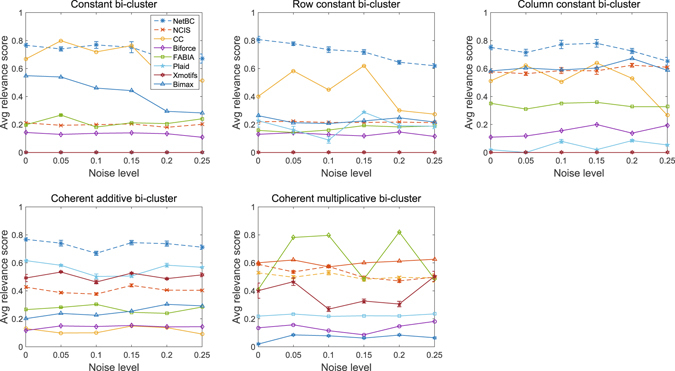
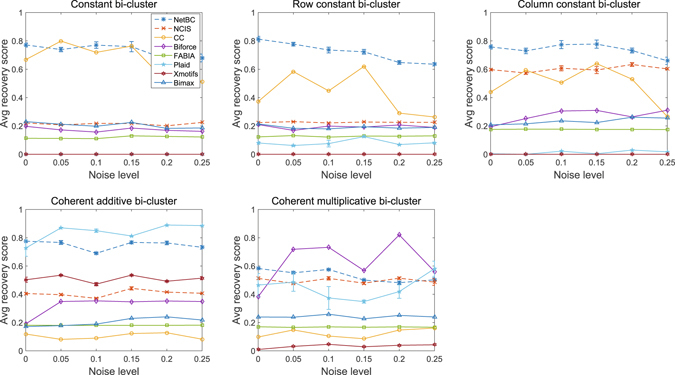
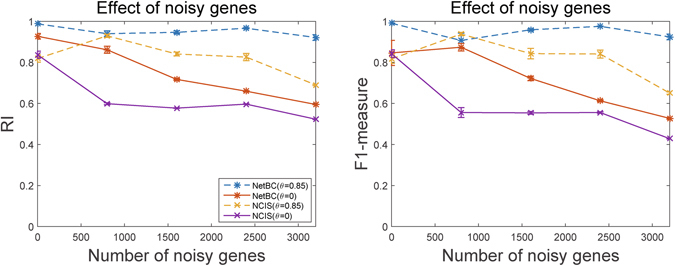
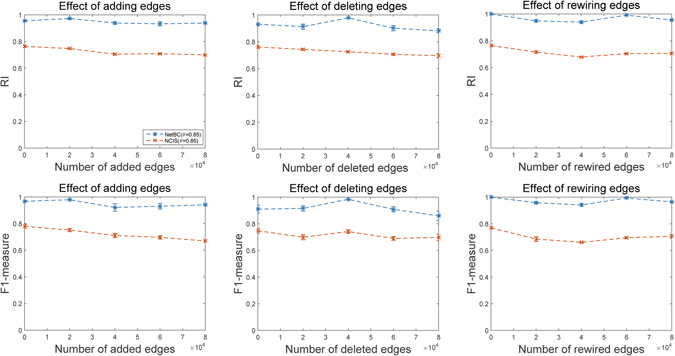
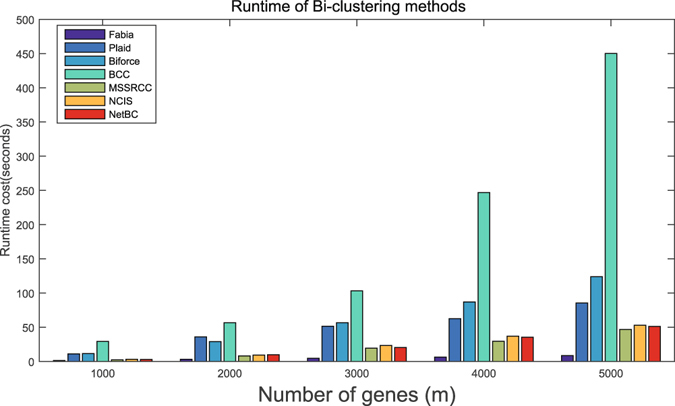
Bi-clustering is a widely used data mining technique for analyzing gene expression data. It simultaneously groups genes and samples of an input gene expression data matrix to discover bi-clusters that relevant samples exhibit similar gene expression profiles over a subset of genes. The discovered bi-clusters bring insights for categorization of cancer subtypes, gene treatments and others. Most existing bi-clustering approaches can only enumerate bi-clusters with constant values. Gene interaction networks can help to understand the pattern of cancer subtypes, but they are rarely integrated with gene expression data for exploring cancer subtypes. In this paper, we propose a novel method called Network-aided Bi-Clustering (NetBC). NetBC assigns weights to genes based on the structure of gene interaction network, and it iteratively optimizes sum-squared residue to obtain the row and column indicative matrices of bi-clusters by matrix factorization. NetBC can not only efficiently discover bi-clusters with constant values, but also bi-clusters with coherent trends. Empirical study on large-scale cancer gene expression datasets demonstrates that NetBC can more accurately discover cancer subtypes than other related algorithms.
双聚类是一种广泛使用的数据挖掘技术,用于分析基因表达数据。它同时对基因和输入基因表达数据矩阵的样本进行分组,以发现相关样本在基因子集上表现出相似的基因表达谱的双聚类。发现的双聚类为癌症亚型的分类、基因治疗等提供了深入的了解。大多数现有的双聚类方法只能枚举具有恒定值的双聚类。基因相互作用网络有助于理解癌症亚型的模式,但它们很少与基因表达数据集成以探索癌症亚型。在本文中,我们提出了一种称为基于网络的双聚类(NetBC)的新方法。NetBC 根据基因相互作用网络的结构为基因分配权重,并通过矩阵分解迭代优化平方和残差,以获得双聚类的行和列指示矩阵。NetBC 不仅可以有效地发现具有恒定值的双聚类,还可以发现具有一致趋势的双聚类。在大规模癌症基因表达数据集上的实证研究表明,NetBC 可以比其他相关算法更准确地发现癌症亚型。