ATR Computational Neuroscience Laboratories, 2-2-2 Hikaridai, Seika, Soraku, Kyoto 619-0288, Japan.
Graduate School of Informatics, Kyoto University, Yoshida-honmachi, Sakyo-ku, Kyoto 606-8501, Japan.
Nat Commun. 2017 May 22;8:15037. doi: 10.1038/ncomms15037.
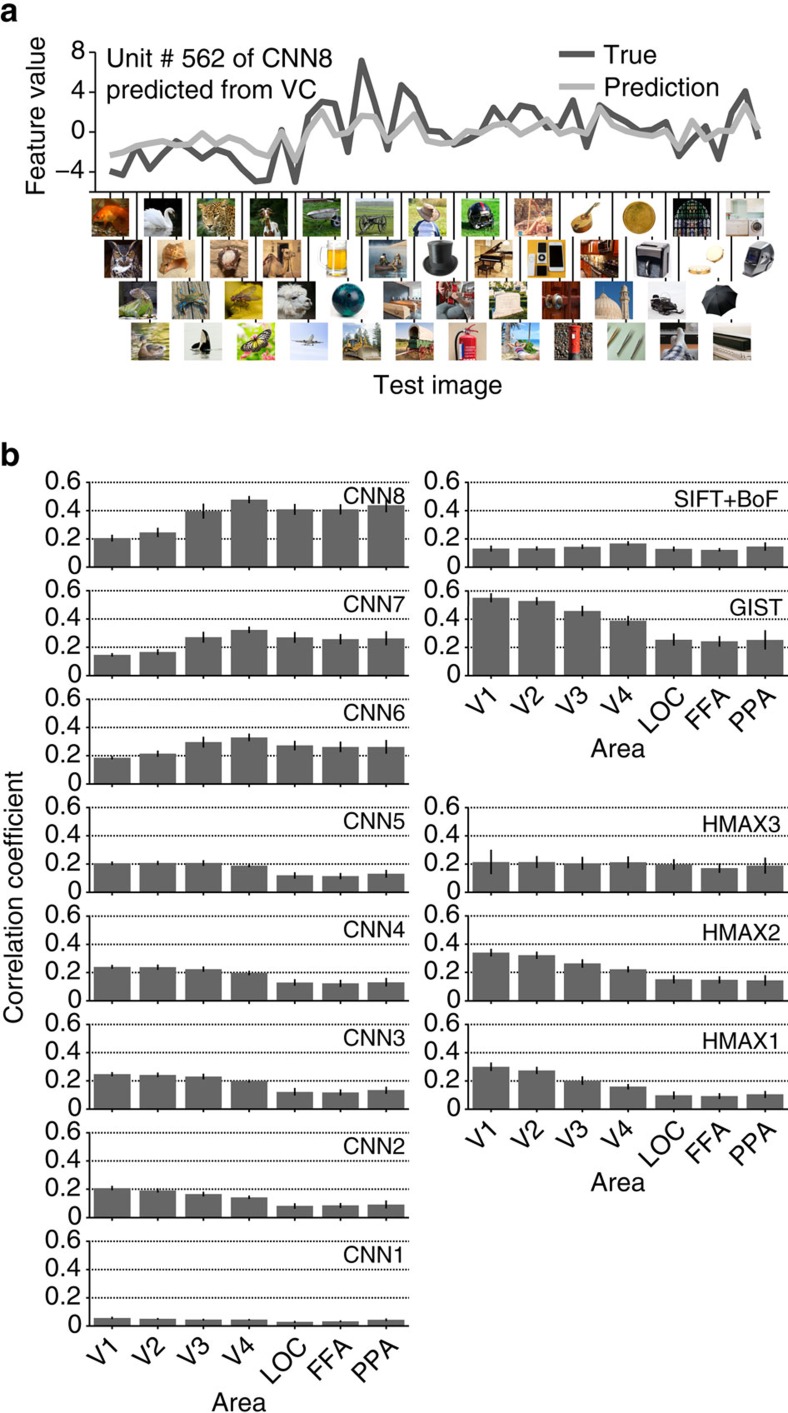
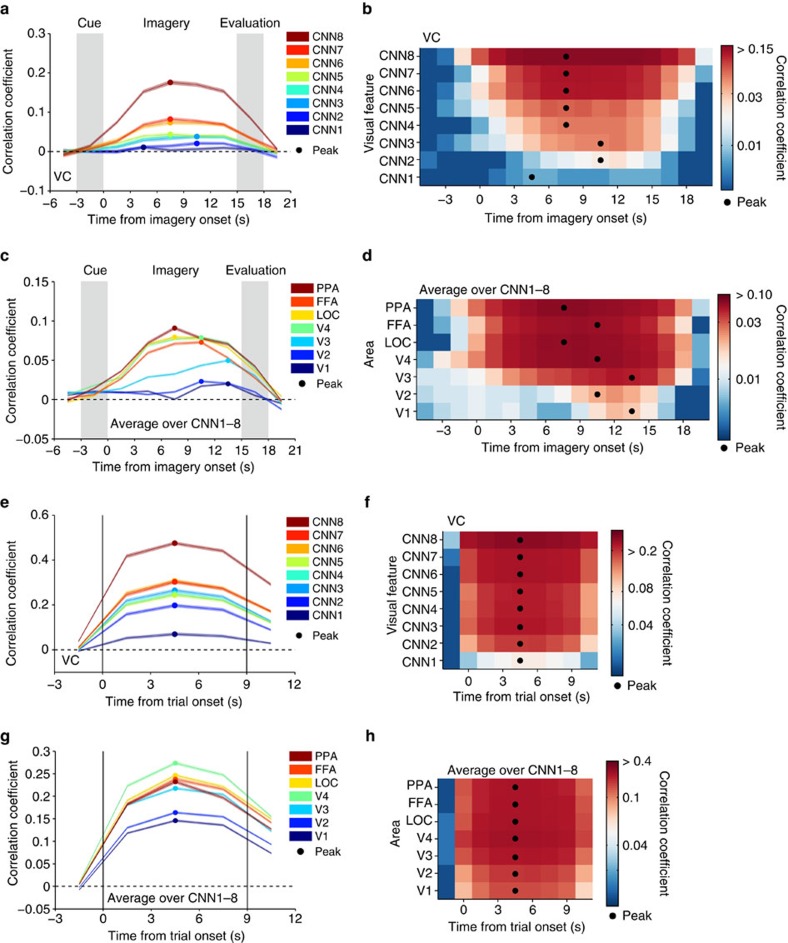
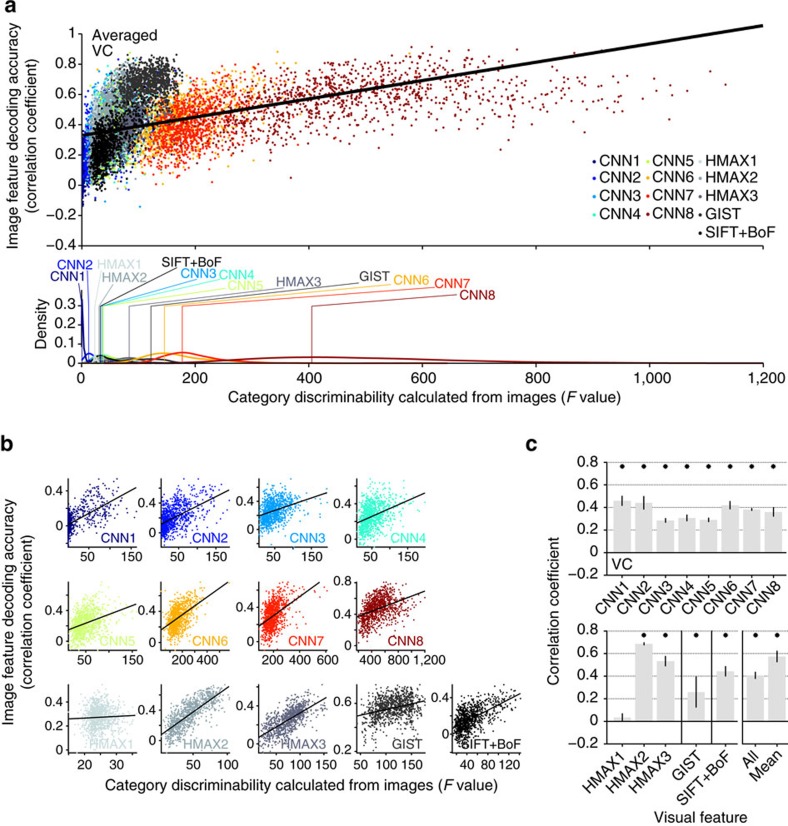
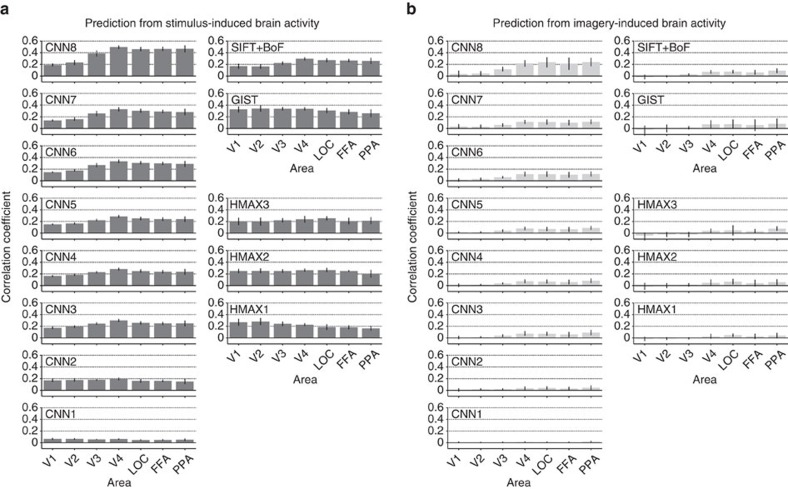
Object recognition is a key function in both human and machine vision. While brain decoding of seen and imagined objects has been achieved, the prediction is limited to training examples. We present a decoding approach for arbitrary objects using the machine vision principle that an object category is represented by a set of features rendered invariant through hierarchical processing. We show that visual features, including those derived from a deep convolutional neural network, can be predicted from fMRI patterns, and that greater accuracy is achieved for low-/high-level features with lower-/higher-level visual areas, respectively. Predicted features are used to identify seen/imagined object categories (extending beyond decoder training) from a set of computed features for numerous object images. Furthermore, decoding of imagined objects reveals progressive recruitment of higher-to-lower visual representations. Our results demonstrate a homology between human and machine vision and its utility for brain-based information retrieval.
物体识别是人类和机器视觉的关键功能。虽然已经实现了对所见和想象物体的大脑解码,但预测仅限于训练示例。我们提出了一种使用机器视觉原理的任意物体解码方法,即物体类别由一组通过分层处理呈现不变的特征表示。我们表明,视觉特征,包括来自深度卷积神经网络的特征,可以从 fMRI 模式中预测出来,并且低/高级特征分别具有较低/较高的视觉区域可以实现更高的准确性。预测特征可用于从一组计算的特征中识别所见/想象的物体类别(扩展到解码器训练之外)。此外,想象物体的解码揭示了较高到较低视觉表示的逐步招募。我们的结果表明人类和机器视觉之间具有同源性,并且它可用于基于大脑的信息检索。