Park Sunghong, Lee Dong-Gi, Shin Hyunjung
Department of Industrial Engineering, Ajou University, 206 Worldcup-ro, Yeongtong-gu, Suwon, 16499, South Korea.
BMC Med Inform Decis Mak. 2017 May 18;17(Suppl 1):55. doi: 10.1186/s12911-017-0449-x.
Although drug discoveries can provide meaningful insights and significant enhancements in pharmaceutical field, the longevity and cost that it takes can be extensive where the success rate is low. In order to circumvent the problem, there has been increased interest in 'Drug Repositioning' where one searches for already approved drugs that have high potential of efficacy when applied to other diseases. To increase the success rate for drug repositioning, one considers stepwise screening and experiments based on biological reactions. Given the amount of drugs and diseases, however, the one-by-one procedure may be time consuming and expensive.
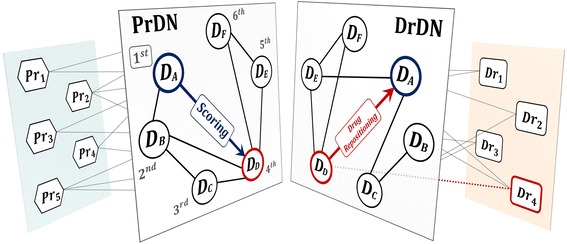
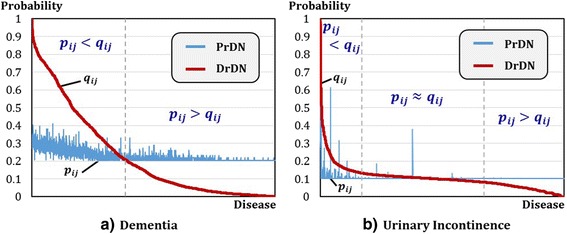
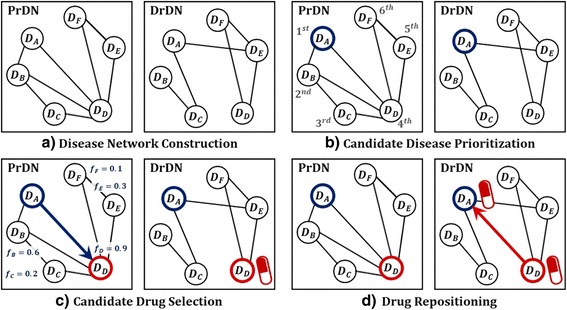
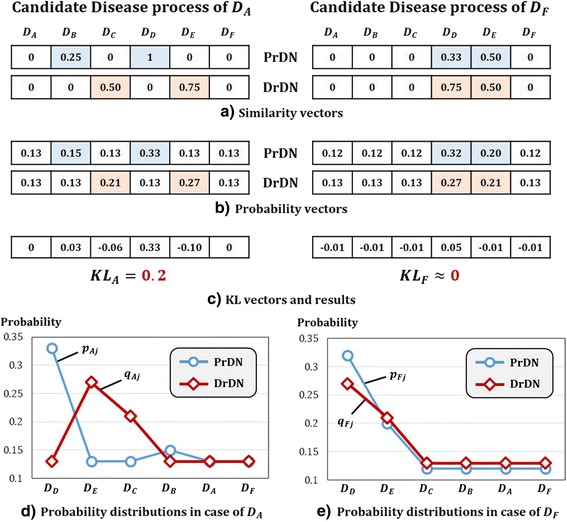
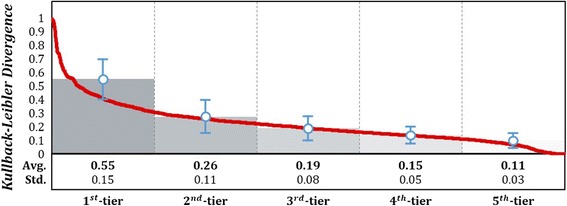
In this study, we propose a machine learning based approach for efficiently selecting candidate diseases and drugs. We assume that if two diseases are similar, then a drug for one disease can be effective against the other disease too. For the procedure, we first construct two disease networks; one with disease-protein association and the other with disease-drug information. If two networks are dissimilar, in a sense that the edge distribution of a disease node differ, it indicates high potential for repositioning new candidate drugs for that disease. The Kullback-Leibler divergence is employed to measure difference of connections in two constructed disease networks. Lastly, we perform repositioning of drugs to the top 20% ranked diseases.
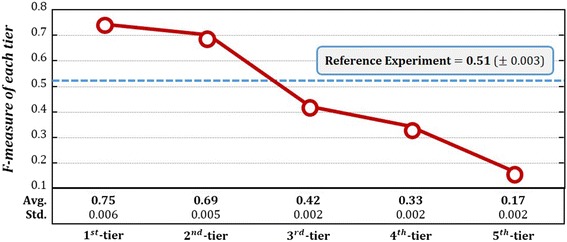
The results showed that F-measure of the proposed method was 0.75, outperforming 0.5 of greedy searching for the entire diseases. For the utility of the proposed method, it was applied to dementia and verified 75% accuracy for repositioned drugs assuming that there are not any known drugs to be used for dementia.
This research has novelty in that it discovers drugs with high potential of repositioning based on disease networks with the quantitative measure. Through the study, it is expected to produce profound insights for possibility of undiscovered drug repositioning.
尽管药物研发能够在制药领域提供有意义的见解并带来显著提升,但研发所需的时间和成本可能很长,且成功率较低。为解决这一问题,人们对“药物重新定位”的兴趣日益增加,即在已批准的药物中寻找应用于其他疾病时具有高效能潜力的药物。为提高药物重新定位的成功率,人们会基于生物反应进行逐步筛选和实验。然而,鉴于药物和疾病的数量众多,逐个进行的程序可能既耗时又昂贵。
在本研究中,我们提出一种基于机器学习的方法,用于高效选择候选疾病和药物。我们假设,如果两种疾病相似,那么针对一种疾病的药物对另一种疾病也可能有效。对于该程序,我们首先构建两个疾病网络;一个是疾病 - 蛋白质关联网络,另一个是疾病 - 药物信息网络。如果两个网络不同,从某种意义上说疾病节点的边分布不同,这表明为该疾病重新定位新候选药物的潜力很大。我们使用库尔贝克 - 莱布勒散度来衡量两个构建的疾病网络中连接的差异。最后,我们将药物重新定位到排名前20%的疾病。
结果表明,所提出方法的F值为0.75,优于对所有疾病进行贪心搜索得到的0.5。为验证所提出方法的实用性,将其应用于痴呆症,假设没有任何已知用于痴呆症的药物,结果显示重新定位药物的准确率为75%。
本研究的新颖之处在于,它基于疾病网络通过定量测量发现具有高重新定位潜力 的药物。通过这项研究,有望为未发现的药物重新定位的可能性产生深刻见解。