Sun Tanlin, Zhou Bo, Lai Luhua, Pei Jianfeng
Center for Quantitative Biology, Academy for Advanced Interdisciplinary Studies, Peking University, Beijing, 100871, China.
Beijing National Laboratory for Molecular Science, State Key Laboratory for Structural Chemistry of Unstable and Stable Species, College of Chemistry and Molecular Engineering, Peking University, Beijing, 100871, China.
BMC Bioinformatics. 2017 May 25;18(1):277. doi: 10.1186/s12859-017-1700-2.
Protein-protein interactions (PPIs) are critical for many biological processes. It is therefore important to develop accurate high-throughput methods for identifying PPI to better understand protein function, disease occurrence, and therapy design. Though various computational methods for predicting PPI have been developed, their robustness for prediction with external datasets is unknown. Deep-learning algorithms have achieved successful results in diverse areas, but their effectiveness for PPI prediction has not been tested.
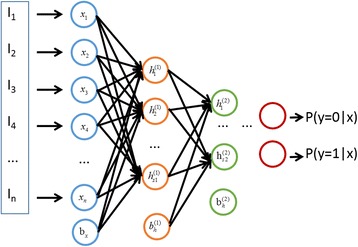
We used a stacked autoencoder, a type of deep-learning algorithm, to study the sequence-based PPI prediction. The best model achieved an average accuracy of 97.19% with 10-fold cross-validation. The prediction accuracies for various external datasets ranged from 87.99% to 99.21%, which are superior to those achieved with previous methods.
To our knowledge, this research is the first to apply a deep-learning algorithm to sequence-based PPI prediction, and the results demonstrate its potential in this field.
蛋白质-蛋白质相互作用(PPI)对许多生物学过程至关重要。因此,开发准确的高通量方法来识别PPI对于更好地理解蛋白质功能、疾病发生和治疗设计非常重要。尽管已经开发了各种预测PPI的计算方法,但它们在外部数据集上预测的稳健性尚不清楚。深度学习算法在不同领域取得了成功,但它们在PPI预测中的有效性尚未得到测试。
我们使用了一种深度学习算法——堆叠自编码器来研究基于序列的PPI预测。最佳模型在10折交叉验证中平均准确率达到97.19%。各种外部数据集的预测准确率在87.99%至99.21%之间,优于以前方法所取得的结果。
据我们所知,本研究首次将深度学习算法应用于基于序列的PPI预测,结果证明了其在该领域的潜力。