Malsiner-Walli Gertraud, Frühwirth-Schnatter Sylvia, Grün Bettina
Department of Applied Statistics, Johannes Kepler University, Linz, Austria.
Institute of Statistics and Mathematics, Wirtschaftsuniversität, Wien, Austria.
J Comput Graph Stat. 2017 Apr 3;26(2):285-295. doi: 10.1080/10618600.2016.1200472. Epub 2017 Apr 24.
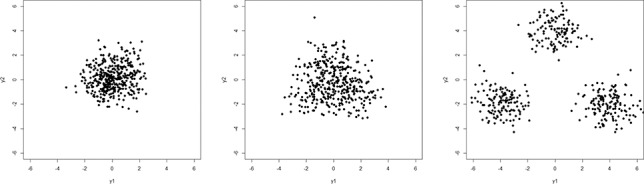
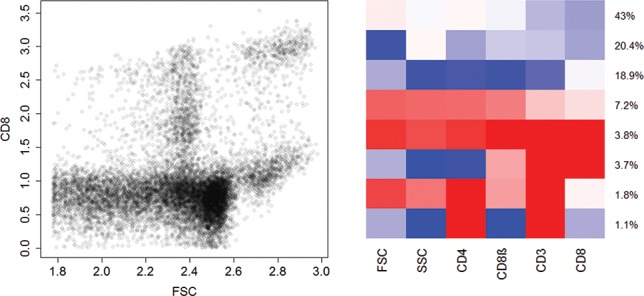
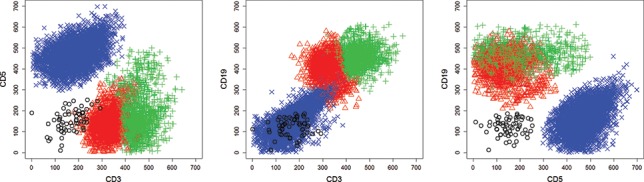
The use of a finite mixture of normal distributions in model-based clustering allows us to capture non-Gaussian data clusters. However, identifying the clusters from the normal components is challenging and in general either achieved by imposing constraints on the model or by using post-processing procedures. Within the Bayesian framework, we propose a different approach based on sparse finite mixtures to achieve identifiability. We specify a hierarchical prior, where the hyperparameters are carefully selected such that they are reflective of the cluster structure aimed at. In addition, this prior allows us to estimate the model using standard MCMC sampling methods. In combination with a post-processing approach which resolves the label switching issue and results in an identified model, our approach allows us to simultaneously (1) determine the number of clusters, (2) flexibly approximate the cluster distributions in a semiparametric way using finite mixtures of normals and (3) identify cluster-specific parameters and classify observations. The proposed approach is illustrated in two simulation studies and on benchmark datasets. Supplementary materials for this article are available online.
在基于模型的聚类中使用正态分布的有限混合,使我们能够捕捉非高斯数据聚类。然而,从正态分量中识别聚类具有挑战性,通常要么通过对模型施加约束,要么通过使用后处理程序来实现。在贝叶斯框架内,我们提出了一种基于稀疏有限混合的不同方法来实现可识别性。我们指定了一个层次先验,其中超参数经过精心选择,使其反映目标聚类结构。此外,这个先验允许我们使用标准的MCMC采样方法来估计模型。结合一种解决标签切换问题并得到已识别模型的后处理方法,我们的方法使我们能够同时(1)确定聚类的数量,(2)使用正态分布的有限混合以半参数方式灵活地近似聚类分布,以及(3)识别特定于聚类的参数并对观测值进行分类。所提出的方法在两个模拟研究和基准数据集上进行了说明。本文的补充材料可在线获取。