Tong Tong, Ledig Christian, Guerrero Ricardo, Schuh Andreas, Koikkalainen Juha, Tolonen Antti, Rhodius Hanneke, Barkhof Frederik, Tijms Betty, Lemstra Afina W, Soininen Hilkka, Remes Anne M, Waldemar Gunhild, Hasselbalch Steen, Mecocci Patrizia, Baroni Marta, Lötjönen Jyrki, Flier Wiesje van der, Rueckert Daniel
Department of Computing, Imperial College London, London, UK; Laboratory for Computational Neuroimaging, Athinoula A. Martinos Center for Biomedical Imaging, MGH/Harvard Medical School, Charlestown, USA.
Department of Computing, Imperial College London, London, UK.
Neuroimage Clin. 2017 Jun 12;15:613-624. doi: 10.1016/j.nicl.2017.06.012. eCollection 2017.
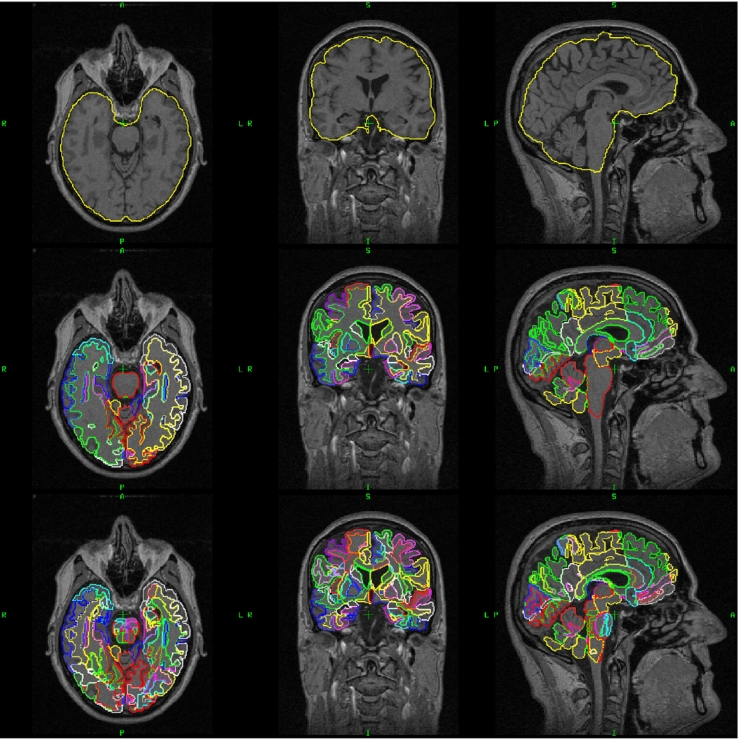
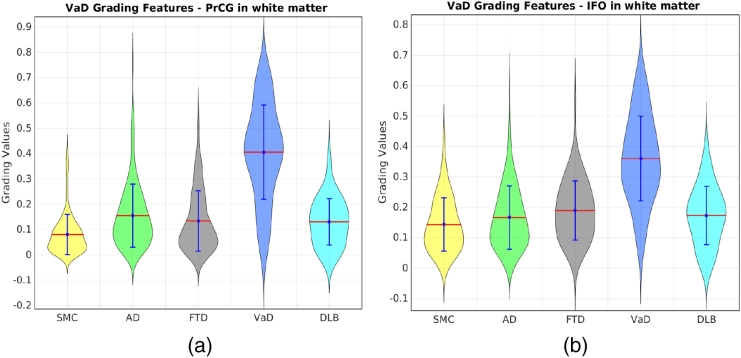
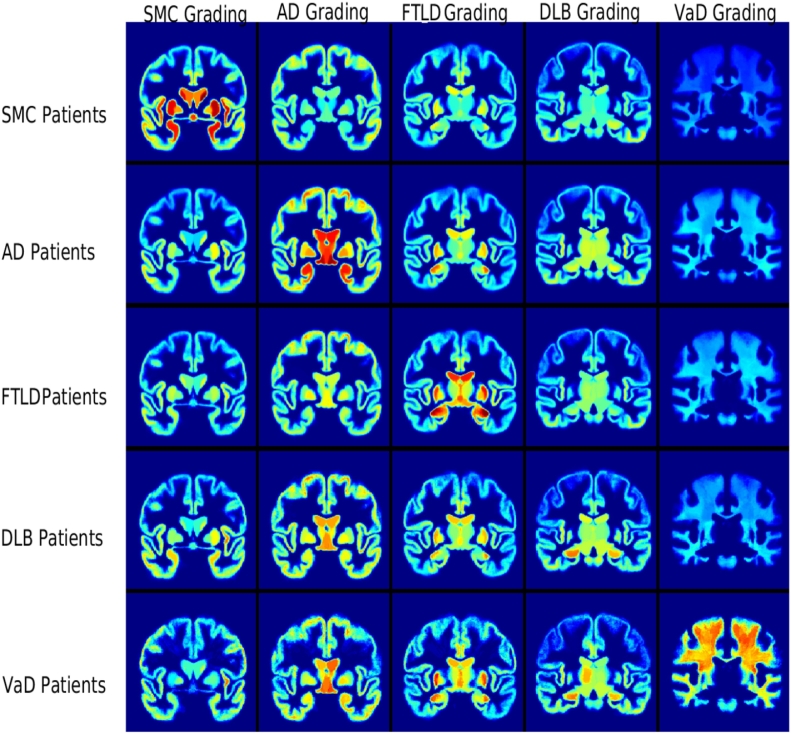
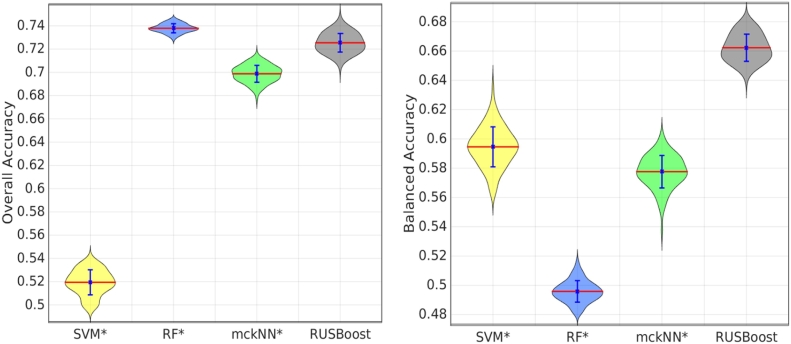
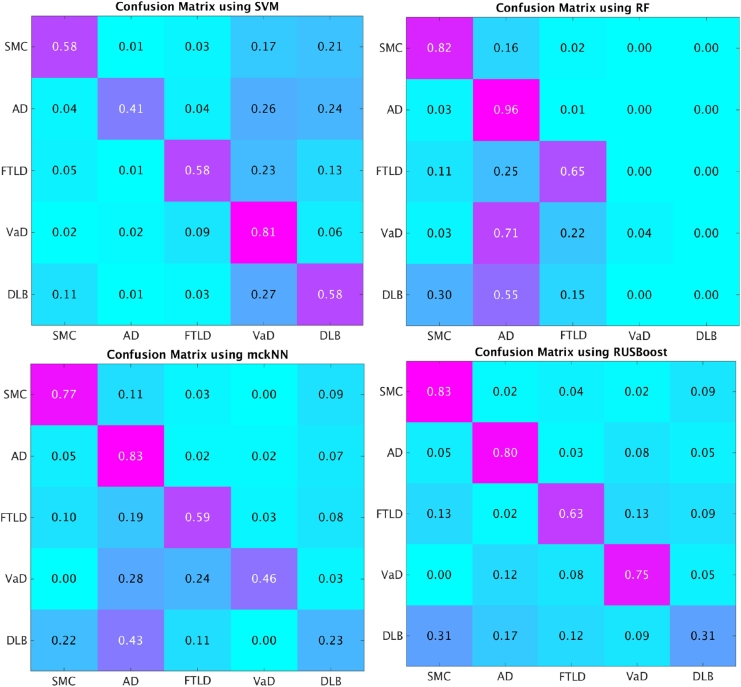
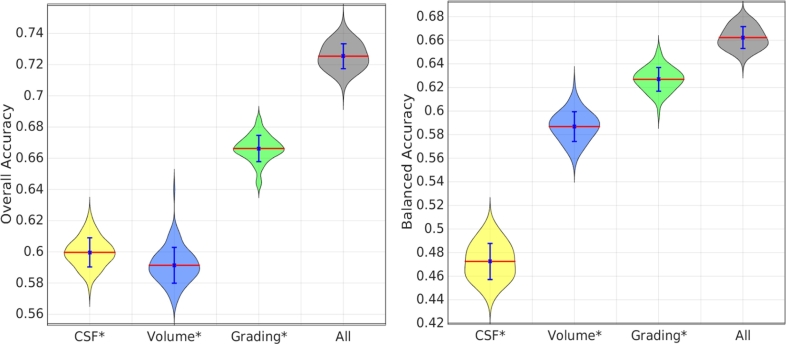
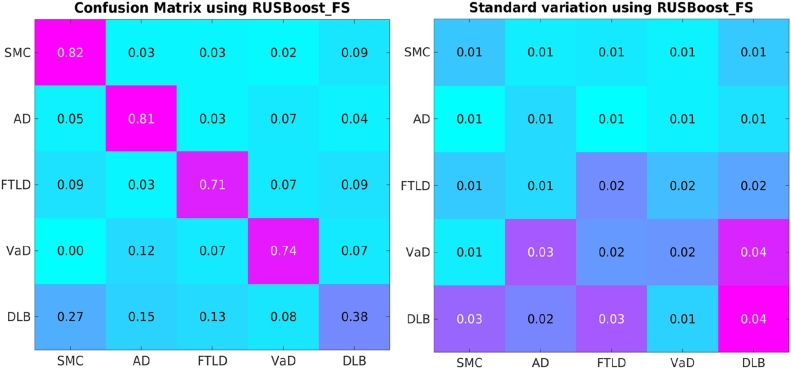
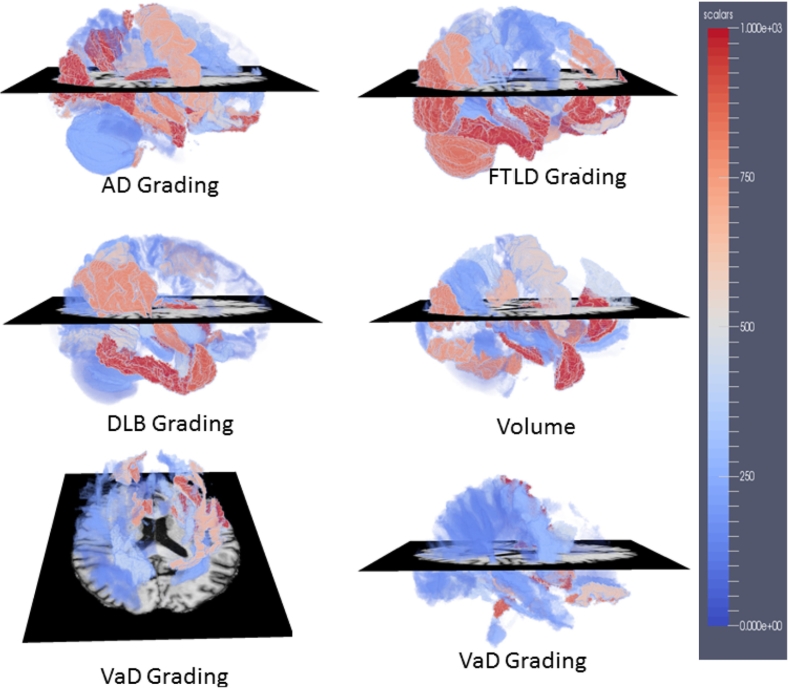
Differentiating between different types of neurodegenerative diseases is not only crucial in clinical practice when treatment decisions have to be made, but also has a significant potential for the enrichment of clinical trials. The purpose of this study is to develop a classification framework for distinguishing the four most common neurodegenerative diseases, including Alzheimer's disease, frontotemporal lobe degeneration, Dementia with Lewy bodies and vascular dementia, as well as patients with subjective memory complaints. Different biomarkers including features from images (volume features, region-wise grading features) and non-imaging features (CSF measures) were extracted for each subject. In clinical practice, the prevalence of different dementia types is imbalanced, posing challenges for learning an effective classification model. Therefore, we propose the use of the RUSBoost algorithm in order to train classifiers and to handle the class imbalance training problem. Furthermore, a multi-class feature selection method based on sparsity is integrated into the proposed framework to improve the classification performance. It also provides a way for investigating the importance of different features and regions. Using a dataset of 500 subjects, the proposed framework achieved a high accuracy of 75.2% with a balanced accuracy of 69.3% for the five-class classification using ten-fold cross validation, which is significantly better than the results using support vector machine or random forest, demonstrating the feasibility of the proposed framework to support clinical decision making.
区分不同类型的神经退行性疾病不仅在临床实践中做出治疗决策时至关重要,而且在丰富临床试验方面具有巨大潜力。本研究的目的是开发一个分类框架,用于区分四种最常见的神经退行性疾病,包括阿尔茨海默病、额颞叶变性、路易体痴呆和血管性痴呆,以及有主观记忆主诉的患者。为每个受试者提取了不同的生物标志物,包括来自图像的特征(体积特征、区域分级特征)和非成像特征(脑脊液测量)。在临床实践中,不同痴呆类型的患病率不均衡,这给学习有效的分类模型带来了挑战。因此,我们建议使用RUSBoost算法来训练分类器并处理类别不平衡训练问题。此外,一种基于稀疏性的多类特征选择方法被集成到所提出的框架中,以提高分类性能。它还为研究不同特征和区域的重要性提供了一种方法。使用一个包含500名受试者的数据集,所提出的框架在十折交叉验证的五类分类中实现了75.2%的高精度和69.3%的平衡精度,这明显优于使用支持向量机或随机森林的结果,证明了所提出的框架支持临床决策的可行性。