Communication & Computer Network Lab of Guangdong, School of Computer Science and Engineering, South China University of Technology, Guangzhou, China.
BMC Med Inform Decis Mak. 2019 Apr 9;19(Suppl 2):65. doi: 10.1186/s12911-019-0762-7.
The Named Entity Recognition (NER) task as a key step in the extraction of health information, has encountered many challenges in Chinese Electronic Medical Records (EMRs). Firstly, the casual use of Chinese abbreviations and doctors' personal style may result in multiple expressions of the same entity, and we lack a common Chinese medical dictionary to perform accurate entity extraction. Secondly, the electronic medical record contains entities from a variety of categories of entities, and the length of those entities in different categories varies greatly, which increases the difficult in the extraction for the Chinese NER. Therefore, the entity boundary detection becomes the key to perform accurate entity extraction of Chinese EMRs, and we need to develop a model that supports multiple length entity recognition without relying on any medical dictionary.
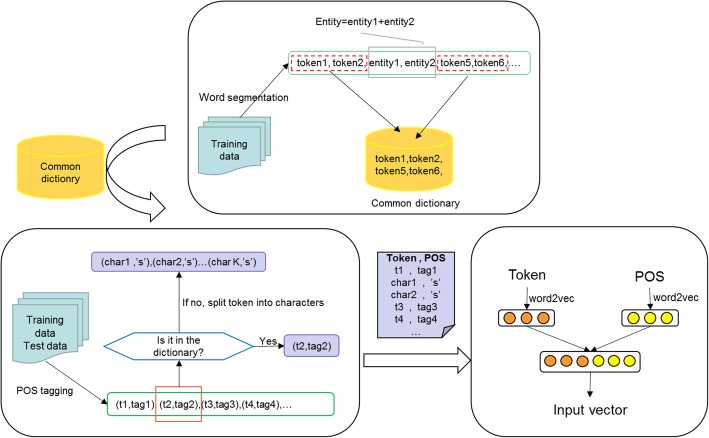
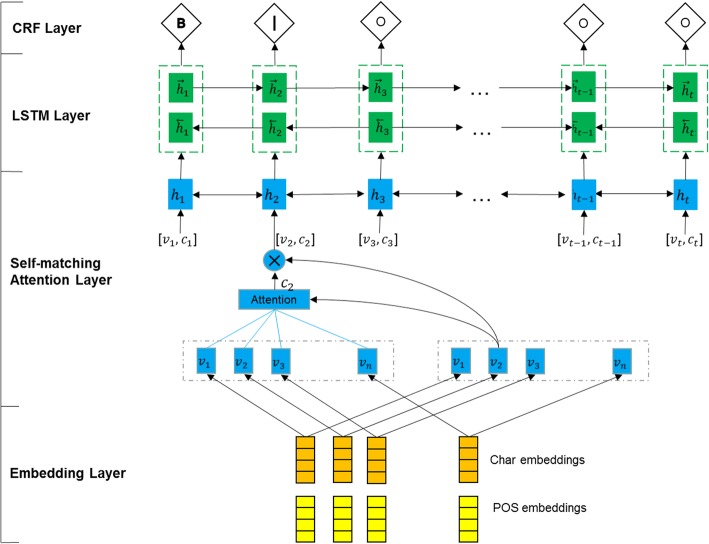
In this study, we incorporate part-of-speech (POS) information into the deep learning model to improve the accuracy of Chinese entity boundary detection. In order to avoid the wrongly POS tagging of long entities, we proposed a method called reduced POS tagging that reserves the tags of general words but not of the seemingly medical entities. The model proposed in this paper, named SM-LSTM-CRF, consists of three layers: self-matching attention layer - calculating the relevance of each character to the entire sentence; LSTM (Long Short-Term Memory) layer - capturing the context feature of each character; CRF (Conditional Random Field) layer - labeling characters based on their features and transfer rules.
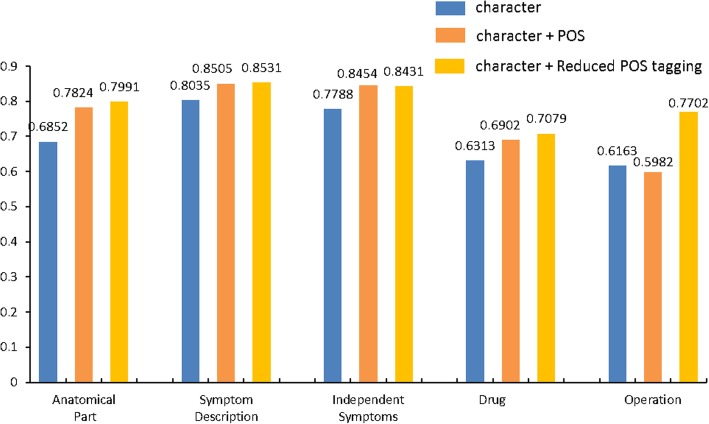
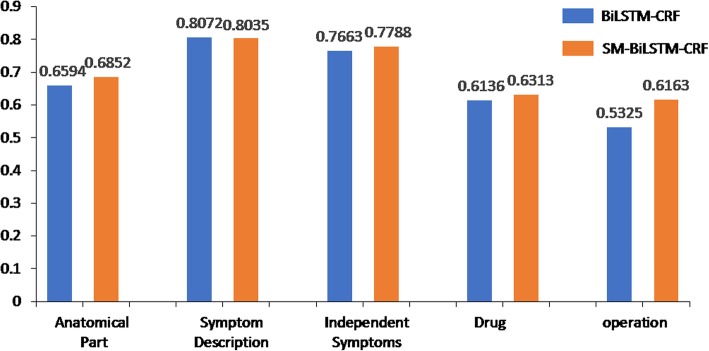
The experimental results at a Chinese EMRs dataset show that the F1 value of SM-LSTM-CRF is increased by 2.59% compared to that of the LSTM-CRF. After adding POS feature in the model, we get an improvement of about 7.74% at F1. The reduced POS tagging reduces the false tagging on long entities, thus increases the F1 value by 2.42% and achieves an F1 score of 80.07%.
The POS feature marked by the reduced POS tagging together with self-matching attention mechanism puts a stranglehold on entity boundaries and has a good performance in the recognition of clinical entities.
命名实体识别(NER)任务作为提取健康信息的关键步骤,在中文电子病历(EMR)中遇到了许多挑战。首先,随意使用中文缩写和医生的个人风格可能会导致同一个实体有多种表达方式,并且我们缺乏一个通用的中文医学词典来进行准确的实体提取。其次,电子病历中包含来自各种实体类别的实体,并且不同类别的实体长度差异很大,这增加了中文 NER 提取的难度。因此,实体边界检测成为准确提取中文 EMR 实体的关键,我们需要开发一种支持多种长度实体识别的模型,而无需依赖任何医学词典。
在本研究中,我们将词性(POS)信息纳入深度学习模型中,以提高中文实体边界检测的准确性。为了避免长实体的错误 POS 标记,我们提出了一种称为简化 POS 标记的方法,该方法保留了普通词的标记,但不保留看似医学实体的标记。本文提出的模型名为 SM-LSTM-CRF,由三层组成:自匹配注意力层 - 计算每个字符与整个句子的相关性;LSTM(长短期记忆)层 - 捕获每个字符的上下文特征;CRF(条件随机场)层 - 根据字符的特征和转移规则对字符进行标记。
在中文 EMRs 数据集上的实验结果表明,与 LSTM-CRF 相比,SM-LSTM-CRF 的 F1 值提高了 2.59%。在模型中添加 POS 特征后,我们在 F1 上的提高约为 7.74%。简化 POS 标记减少了长实体的错误标记,从而使 F1 值提高了 2.42%,达到了 80.07%的 F1 得分。
经简化 POS 标记标记的 POS 特征与自匹配注意力机制相结合,对实体边界施加了严格的限制,在临床实体识别方面表现良好。