Price Nathan D, Magis Andrew T, Earls John C, Glusman Gustavo, Levy Roie, Lausted Christopher, McDonald Daniel T, Kusebauch Ulrike, Moss Christopher L, Zhou Yong, Qin Shizhen, Moritz Robert L, Brogaard Kristin, Omenn Gilbert S, Lovejoy Jennifer C, Hood Leroy
Institute for Systems Biology, Seattle, Washington, USA.
Arivale, Seattle, Washington, USA.
Nat Biotechnol. 2017 Aug;35(8):747-756. doi: 10.1038/nbt.3870. Epub 2017 Jul 17.
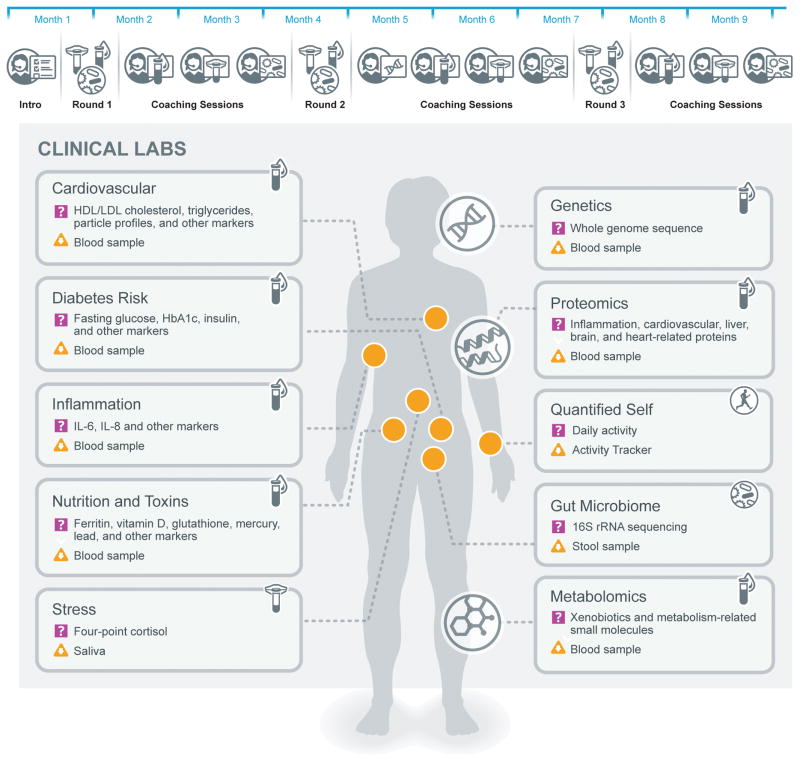
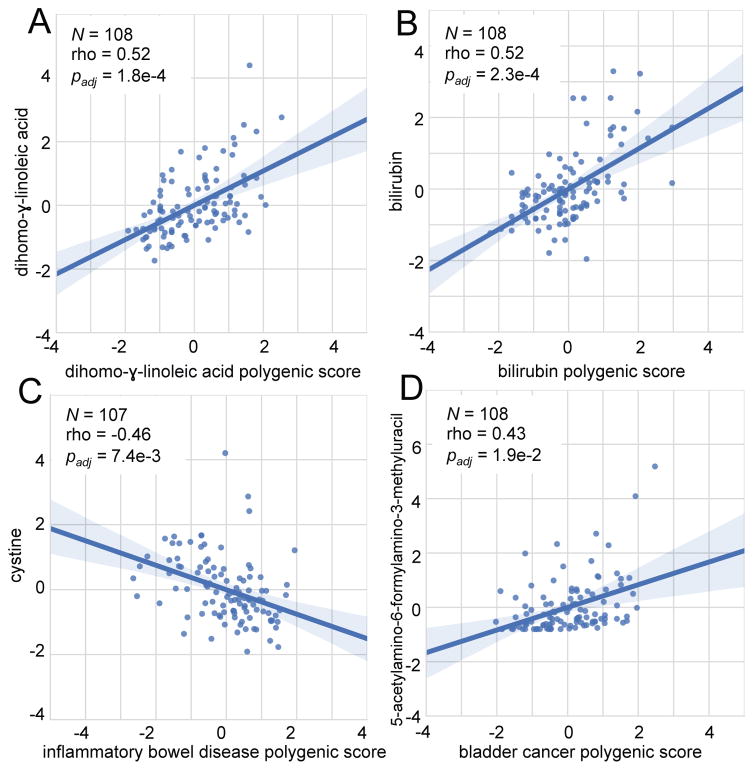
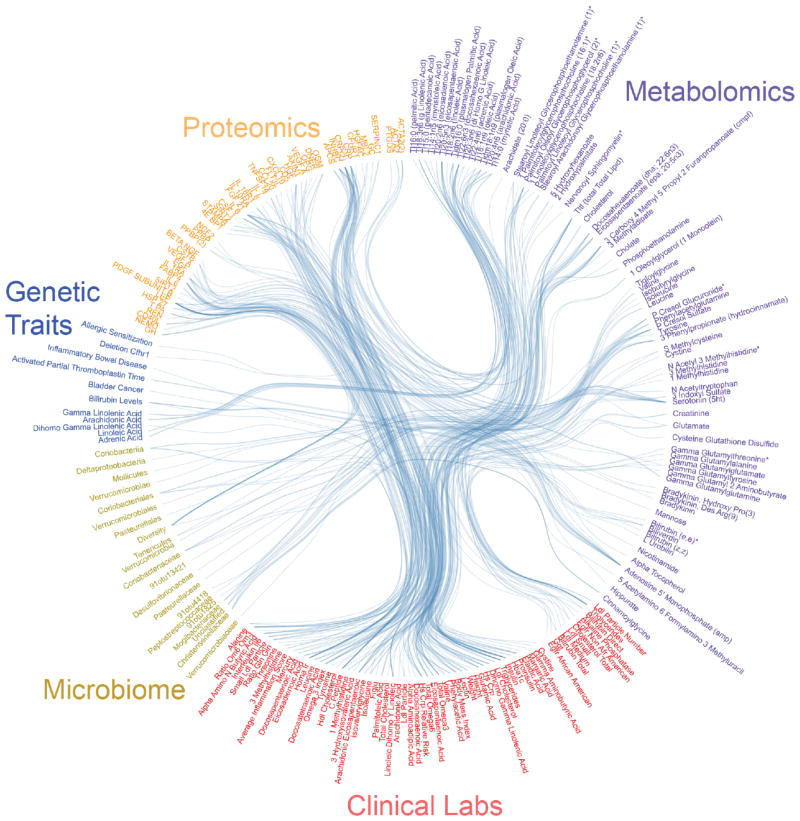
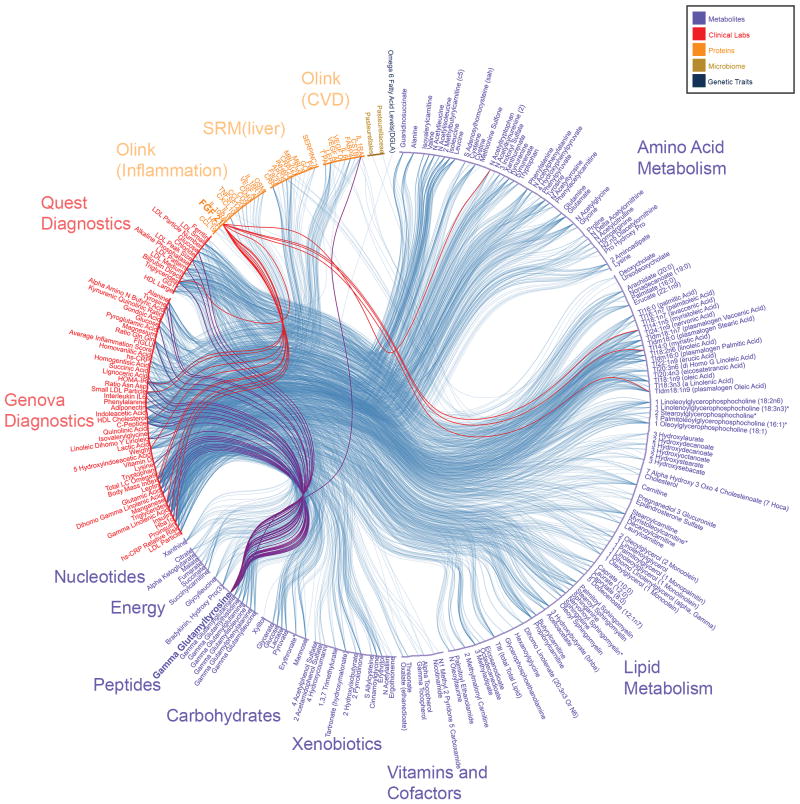
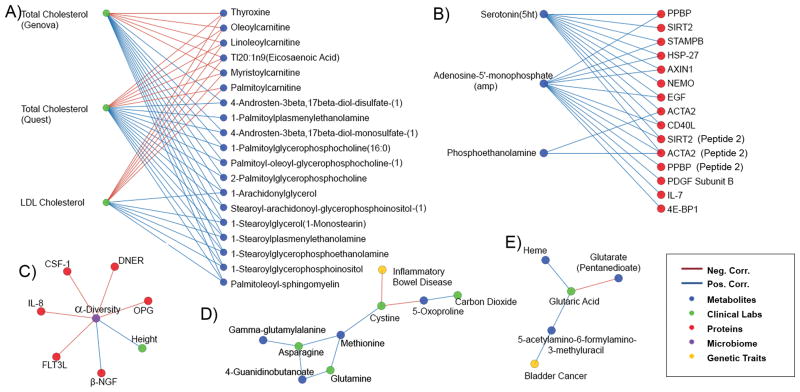
Personal data for 108 individuals were collected during a 9-month period, including whole genome sequences; clinical tests, metabolomes, proteomes, and microbiomes at three time points; and daily activity tracking. Using all of these data, we generated a correlation network that revealed communities of related analytes associated with physiology and disease. Connectivity within analyte communities enabled the identification of known and candidate biomarkers (e.g., gamma-glutamyltyrosine was densely interconnected with clinical analytes for cardiometabolic disease). We calculated polygenic scores from genome-wide association studies (GWAS) for 127 traits and diseases, and used these to discover molecular correlates of polygenic risk (e.g., genetic risk for inflammatory bowel disease was negatively correlated with plasma cystine). Finally, behavioral coaching informed by personal data helped participants to improve clinical biomarkers. Our results show that measurement of personal data clouds over time can improve our understanding of health and disease, including early transitions to disease states.
在9个月的时间里收集了108个人的个人数据,包括全基因组序列;三个时间点的临床测试、代谢组、蛋白质组和微生物组;以及日常活动跟踪。利用所有这些数据,我们生成了一个相关网络,该网络揭示了与生理和疾病相关的分析物群落。分析物群落内部的连通性有助于识别已知和候选生物标志物(例如,γ-谷氨酰酪氨酸与心脏代谢疾病的临床分析物紧密相连)。我们从全基因组关联研究(GWAS)中计算了127种性状和疾病的多基因评分,并利用这些评分发现多基因风险的分子相关性(例如,炎症性肠病的遗传风险与血浆胱氨酸呈负相关)。最后,基于个人数据的行为指导帮助参与者改善临床生物标志物。我们的结果表明,随着时间的推移对个人数据云进行测量可以增进我们对健康和疾病的理解,包括向疾病状态的早期转变。