SONY CSL, Paris, France.
Sorbonne Universités, UPMC Univ Paris 06, UMR 7606, LIP6, F-75005, Paris, France.
Sci Rep. 2017 Aug 23;7(1):9172. doi: 10.1038/s41598-017-08028-4.
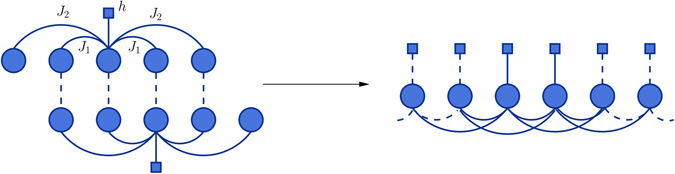
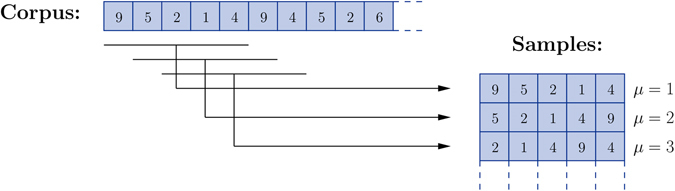
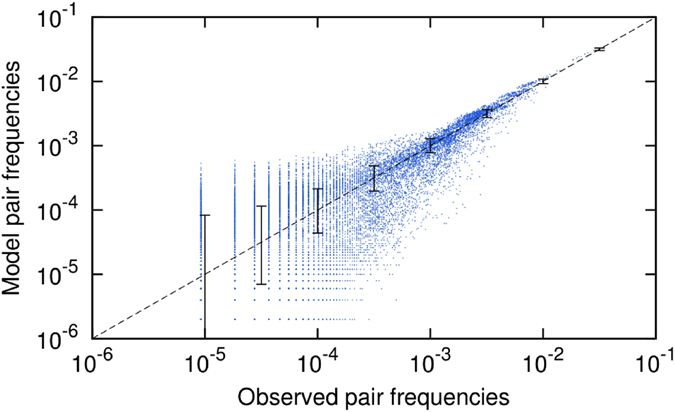
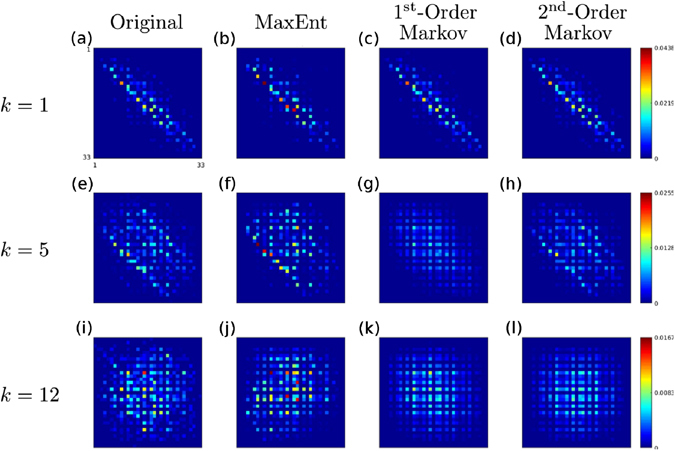
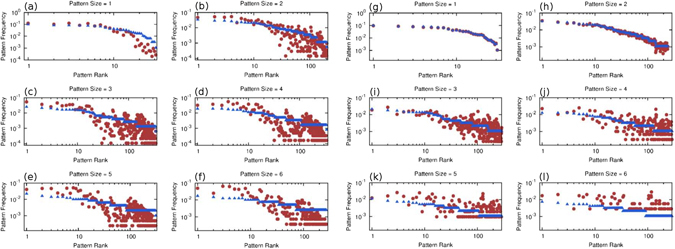
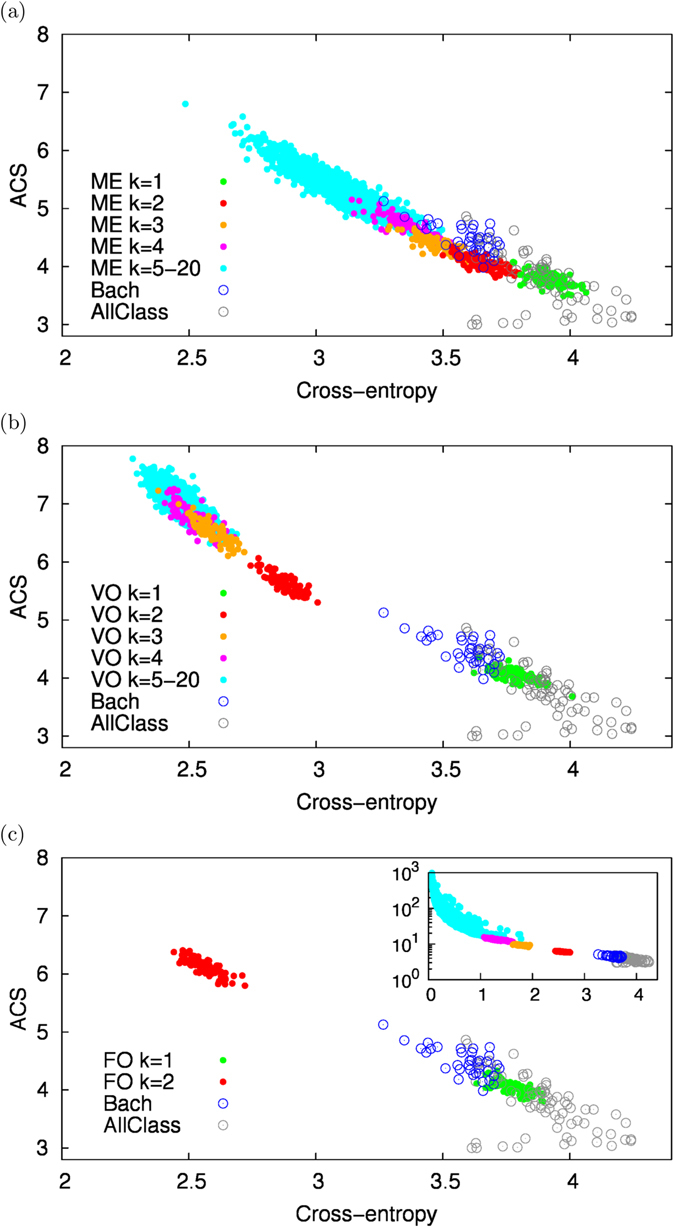
We introduce a Maximum Entropy model able to capture the statistics of melodies in music. The model can be used to generate new melodies that emulate the style of a given musical corpus. Instead of using the n-body interactions of (n-1)-order Markov models, traditionally used in automatic music generation, we use a k-nearest neighbour model with pairwise interactions only. In that way, we keep the number of parameters low and avoid over-fitting problems typical of Markov models. We show that long-range musical phrases don't need to be explicitly enforced using high-order Markov interactions, but can instead emerge from multiple, competing, pairwise interactions. We validate our Maximum Entropy model by contrasting how much the generated sequences capture the style of the original corpus without plagiarizing it. To this end we use a data-compression approach to discriminate the levels of borrowing and innovation featured by the artificial sequences. Our modelling scheme outperforms both fixed-order and variable-order Markov models. This shows that, despite being based only on pairwise interactions, our scheme opens the possibility to generate musically sensible alterations of the original phrases, providing a way to generate innovation.
我们引入了一种最大熵模型,能够捕捉音乐中旋律的统计信息。该模型可用于生成新的旋律,模仿给定音乐语料库的风格。与传统的自动音乐生成中使用的(n-1)阶马尔可夫模型的 n 体相互作用不同,我们仅使用具有成对相互作用的 k 最近邻模型。通过这种方式,我们保持参数数量低,并避免马尔可夫模型中常见的过拟合问题。我们表明,长距离音乐短语不需要使用高阶马尔可夫相互作用显式强制,而是可以从多个相互竞争的成对相互作用中出现。我们通过对比生成序列在不抄袭原始语料库的情况下捕捉原始语料库风格的程度来验证我们的最大熵模型。为此,我们使用数据压缩方法来区分人工序列所具有的借用和创新水平。我们的建模方案优于固定阶和可变阶马尔可夫模型。这表明,尽管仅基于成对相互作用,我们的方案仍为生成原始短语的音乐感知改变提供了可能性,从而为生成创新提供了一种方法。