Adelson Jill L, McCoach D B, Rogers H J, Adelson Jonathan A, Sauer Timothy M
Department of Counseling and Human Development, University of Louisville, LouisvilleKY, United States.
Department of Educational Psychology, University of Connecticut, StorrsCT, United States.
Front Psychol. 2017 Aug 17;8:1413. doi: 10.3389/fpsyg.2017.01413. eCollection 2017.
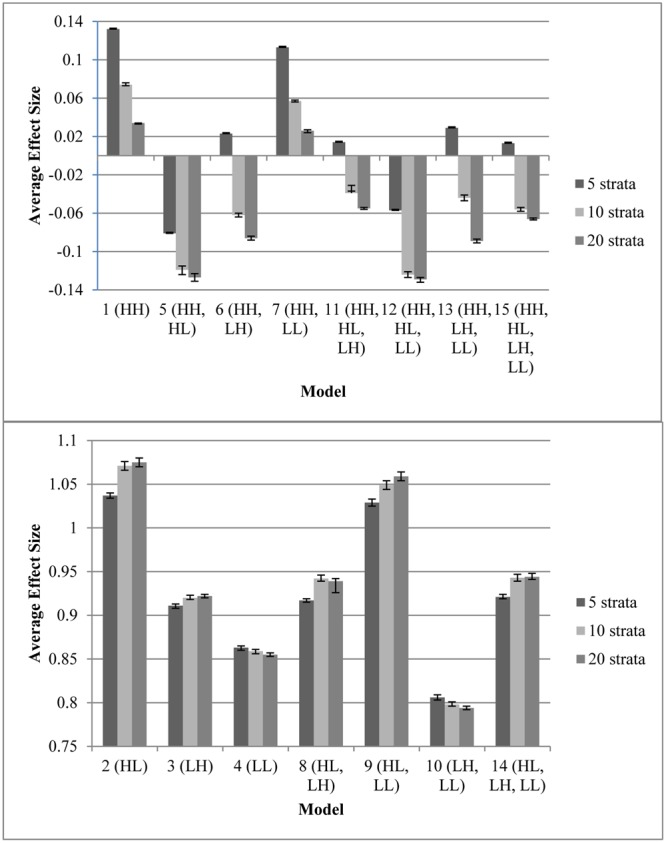
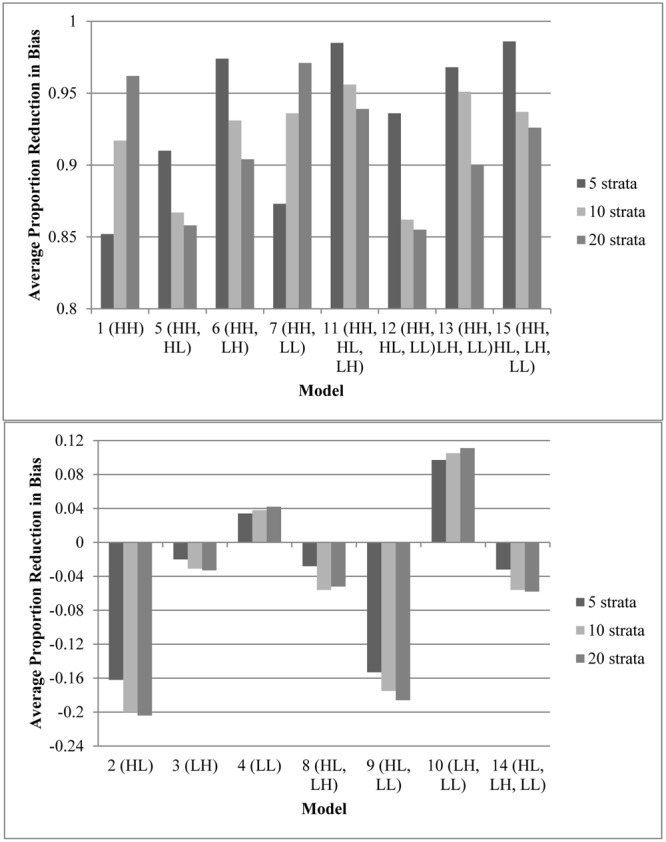
This Monte Carlo simulation examined the effects of variable selection (combinations of confounders with four patterns of relationships to outcome and assignment to treatment) and number of strata (5, 10, or 20) in propensity score analyses. The focus was on how the variations affected the average effect size compared to quasi-assignment without adjustment for bias. Results indicate that if a propensity score model does not include variables strongly related to both outcome and assignment, not only will bias not decrease, but it may possibly increase. Furthermore, models that include a variable highly related to assignment to treatment but do not also include a variable highly related to the outcome could increase bias. In regards to the number of strata, results varied depending on the propensity score model and sample size. In 75% of the models that resulted in a significant reduction in bias, quintiles outperformed the other stratification schemes. In fact, the richer that the propensity score model was (i.e., including multiple covariates of varying relationships to the outcome and to assignment to treatment), the more likely that the model required fewer strata to balance the covariates. In models without that same richness, additional strata were necessary. Finally, the study suggests that when developing a rich propensity score model with stratification, it is crucial to examine the strata for overlap.
这项蒙特卡洛模拟研究了倾向得分分析中变量选择(混杂因素与结果及治疗分配的四种关系模式的组合)和分层数量(5、10或20)的影响。重点在于与未调整偏差的准分配相比,这些变化如何影响平均效应大小。结果表明,如果倾向得分模型不包括与结果和分配都密切相关的变量,偏差不仅不会减小,反而可能会增加。此外,包含与治疗分配高度相关但不包含与结果高度相关变量的模型可能会增加偏差。关于分层数量,结果因倾向得分模型和样本量而异。在75%导致偏差显著减少的模型中,五分位数的表现优于其他分层方案。实际上,倾向得分模型越丰富(即包括与结果和治疗分配具有不同关系的多个协变量),该模型就越有可能需要较少的分层来平衡协变量。在不具有相同丰富度的模型中,则需要额外的分层。最后,该研究表明,在开发具有分层的丰富倾向得分模型时,检查分层的重叠情况至关重要。